ElasticJob 3.0.0:打造面向互联网生态和海量任务的分布式调度解决方案
ElasticJob 于 2020 年 5 月 28 日重启并成为 Apache ShardingSphere 子项目。新版本借鉴了 ShardingSphere 可拔插架构的设计理念,对内核进行了大量解耦和重构,打造了全新的作业 API,提升项目的易用性。自重启以来,社区活跃度大幅增加,目前项目累计收获超过 7,000 Star,贡献了超过 2,000 次 commits,面向互联网生态和海量数据的分布式调度平台将进一步被大规模使用,解决用户的作业调度难以水平扩展、可用性有限的问题。
本文将给各位介绍 ElasticJob 3.0.0 究竟做出了怎样的改变。
吴伟杰
SphereEx 中间件研发工程师,Apache ShardingSphere committer,ElasticJob 3.0.0 版本 Release Manager。目前专注于 Apache ShardingSphere 及其子项目 ElasticJob 的研发。
ElasticJob 简介
ElasticJob 是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。它通过弹性调度、资源管控、以及作业治理的功能,打造一个适用于互联网场景的分布式调度解决方案,并通过开放的架构设计,提供多元化的作业生态。它的各个产品使用统一的作业 API,开发者仅需一次开发,即可随意部署。
3.0 的改变
一、全新作业 API,作业类型可灵活扩展
新版本的 ElasticJob ,打造了全新的作业 API。开发者不再局限于框架预置的作业类型,能够借助 SPI 扩展作业执行器类型,打造更贴合实际场景的作业逻辑。除此之外,得益于新的模块化架构,开发者可以方便地向社区回馈独立、通用的作业类型。
以 ElasticJob 2.1.5 版本为例,作业执行器的类型已经固定在代码逻辑中,传入的参数如果不是内置的作业执行器类型,则直接抛出异常,开发者无法直接扩展。
public static AbstractElasticJobExecutor getJobExecutor(final ElasticJob elasticJob, final JobFacade jobFacade) {
if (null == elasticJob) {
return new ScriptJobExecutor(jobFacade);
}
if (elasticJob instanceof SimpleJob) {
return new SimpleJobExecutor((SimpleJob) elasticJob, jobFacade);
}
if (elasticJob instanceof DataflowJob) {
return new DataflowJobExecutor((DataflowJob) elasticJob, jobFacade);
}
throw new JobConfigurationException("Cannot support job type '%s'", elasticJob.getClass().getCanonicalName());
}
在 ElasticJob 3.0.0,作业执行器经过重新设计,分为 Classed 与 Typed 两类。需要编写作业逻辑的 Simple、Dataflow 作业属于 Classed 类型作业,通过配置执行的 Script、HTTP 作业属于 Typed 类型作业。
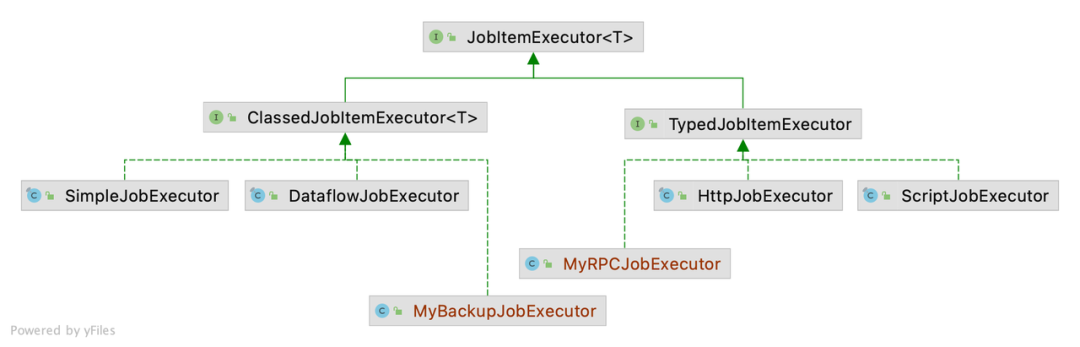
基于这种设计,开发者只需要三个步骤就可以自行扩展更贴合业务场景的 Class 类型作业执行器。
举个例子:
1. 先扩展 ElasticJob 顶层接口定义作业逻辑的执行接口:
public interface BackupJob extends ElasticJob {
void backup(Collection<AvailableData> availableData) throws IOException;
}
2. 然后实现一个 ClassedJobItemExecutor<BackupJob> 命名为 MyBackupJobExecutor:
public class MyBackupJobExecutor implements ClassedJobItemExecutor<BackupJob> {
@SneakyThrows
@Override
public void process(BackupJob elasticJob, JobConfiguration jobConfig, JobFacade jobFacade, ShardingContext shardingContext) {
Collection<AvailableData> availableData = getAvaiableData(shardingContext);
elasticJob.backup(availableData);
}
@Override
public Class<BackupJob> getElasticJobClass() {
return BackupJob.class;
}
}
3. 把自己实现的 MyBackupJobExecutor 通过 Java SPI 的方式声明实现类。
如果是扩展 Type 类型的作业执行器,只需要进行后面两步。完成了以上步骤,就可以在作业中使用自己定制的作业执行器了。
二、作业调度方式多元化
全新引入的“一次性调度”让 ElasticJob Lite 的作业调度不再局限于“定时”。原本基于 Cron 表达式调度的方式重构为 ScheduleJobBootstrap,OneOffJobBootstrap 是 ElasticJob 3.0.0 新增的调度方式。
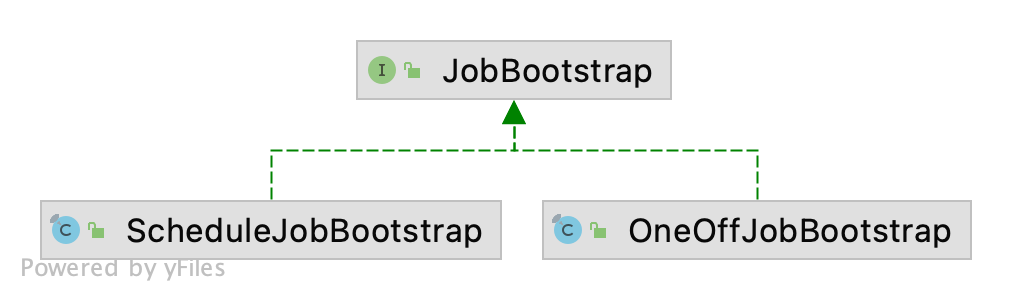
使用 ElasticJob 2.x 时,如果要实现一个能够自由触发的作业,需要经过以下步骤:
1. 创建一个短时间内不会触发的作业,例如设置 Cron 表达式为 59 59 23 31 12 ? 2099;
2. 在项目中引入 elasticjob-lite-lifecycle 模块依赖;
3. 创建一个 JobOperationAPI 的实例;
4. 调用 JobOperationAPI 的 trigger 方法。
在 ElasticJob 3.0.0 可以这么操作:
OneOffJobBootstrap job = new OneOffJobBootstrap(regCenter, elasticjob, jobConfig);
job.execute();
无论是操作复杂度还是代码优雅性,新的 API 都更胜一筹。新的调度方式将为 ElasticJob 的应用增加更多的可能性。
三、微内核 & 生态分离
作业错误处理器、执行轨迹追踪等可扩展模块从内核模块完全抽离,全新的 API 结合 SPI 机制,让开发者可以灵活扩展各个模块的功能,促成 ElasticJob 生态对接。
在 3.0.0 版本中,作业错误处理器预置了企业微信、钉钉、邮件 3 种通知渠道。
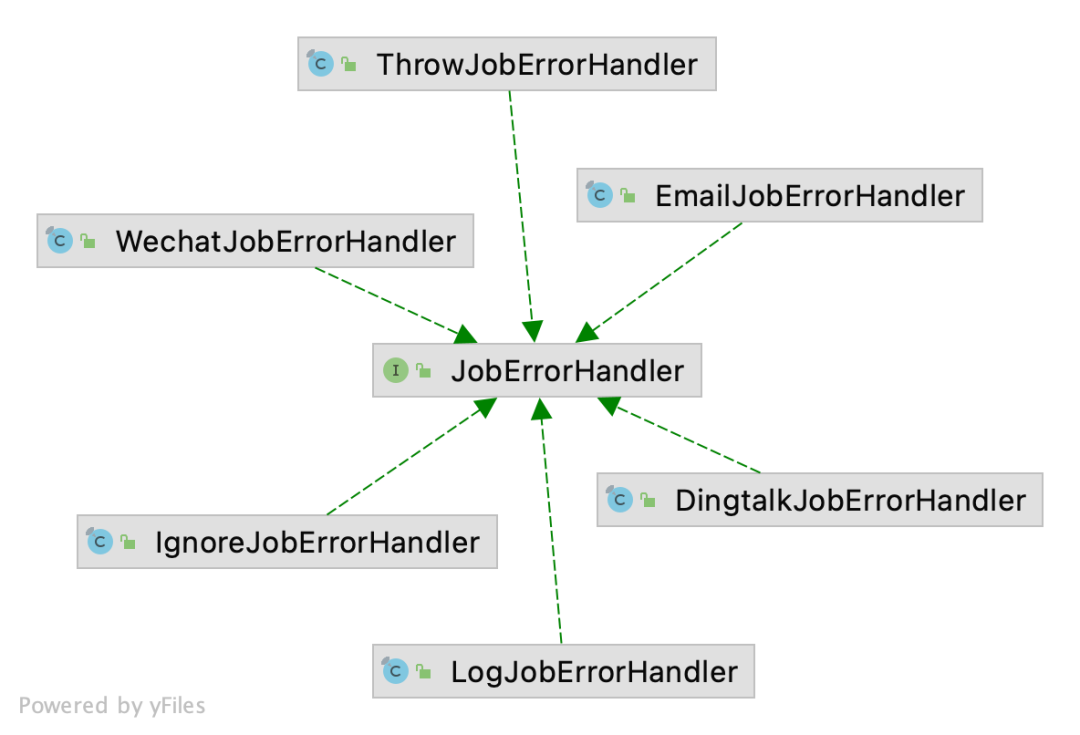
执行轨迹追踪模块数据源不再局限于 MySQL,现已支持 PostgreSQL、Oracle、H2、DB2、SQLServer 以及其他遵循 SQL92 标准的数据库。

值得一提的是,以上提到的 ElasticJob 3.0.0 生态扩充的内容,均是由社区的同学们贡献的。
四、ElasticJob Lite 提供官方的 Spring Boot Starter
Spring 应用引入 ElasticJob Lite 时可以不再编写繁琐的 XML 文件了。新版本提供了全新的 Spring Boot Starter,在项目中使用 ElasticJob 定时调度只需两个步骤。
1. 在作业逻辑的类上加上 @Component 注解:
@Component
public class DataRefreshJob implements SimpleJob {
@Override
public void execute(final ShardingContext shardingContext) {
// Do something here
}
}
2. 在 Spring 配置文件中配置作业
elasticjob:
regCenter:
serverLists: zookeeper0:2181,zookeeper1:2181,zookeeper2:2181
namespace: schedule-jobs
jobs:
dataRefreshJob:
elasticJobClass: org.path.to.DataRefreshJob
cron: 0 0 0/6 * * ?
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
完成以上配置后,ElasticJob 的作业就会随着 Spring Boot 启动了。
后续版本还将实现基于注解配置作业,提供更多样化的配置方式,更进一步简化配置。
五、可观测性
通过 APM,辅以 ElasticJob 的作业执行轨迹追踪模块,以 ElasticJob 调度为起点的作业全链路可以一览无余。后续计划基于 OpenTracing 等方式开发托管在 ElasticJob 仓库的 Agent。
例如,SkyWalking 实现了支持 ElasticJob 3.x 版本的自动探针。
六、对多网卡环境的支持更完善
ElasticJob 在运行过程中会获取当前进程所在环境的 IP 地址,在一些多网卡的环境下,自动获取 IP 地址的逻辑可能会获取到非用户所预期的地址,对管控界面的展示或作业管理对带来一些不便之处。ElasticJob 3.0.0 将允许用户指定优先使用的网卡,使节点信息更符合用户的预期。在后续版本计划支持正则表达式匹配等方式进行网卡的选择。
社区
自 ShardingSphere ElasticJob 重启以来,有至少 62 位 Contributors(部分 Contributors 邮箱设置不正确没有被统计到)的 653 个 PR 被合并,感谢各位 Contributors!

欢迎扫码关注大家

ElasticJob 3.0.0:打造面向互联网生态和海量任务的分布式调度解决方案的更多相关文章
- 官宣!ElasticJob 3.0.0 版本正式发布
ElasticJob 是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成.它通过弹性调度.资源管控.以及 ...
- Elastic-Job 分布式调度平台
概述 referred:http://elasticjob.io/docs/elastic-job-lite/00-overview Elastic-Job是一个分布式调度解决方案,由两个相互独立的子 ...
- Vue+Django2.0 restframework打造前后端分离的生鲜电商项目(1)
1.开发环境配置 Windows7 64位旗舰版 python3.6 node.js mysql navicat pycharm webstorm或vscode 2.项目初始化 新版的pycharm很 ...
- 乘风破浪,遇见华为鸿蒙智能终端系统(HarmonyOS 2),打造面向全场景的分布式操作系统
什么是鸿蒙智能终端系统(HarmonyOS 2) HarmonyOS 是新一代的智能终端操作系统,为不同设备的智能化.互联与协同提供了统一的语言.带来简洁,流畅,连续,安全可靠的全场景交互体验. ht ...
- 重磅|Apache ShardingSphere 5.0.0 即将正式发布
Apache ShardingSphere 5.0.0 GA 版在经历 5.0.0-alpha 及 5.0.0-beta 接近两年时间的研发和打磨,终于将在 11 月份与大家正式见面! 11 月 10 ...
- Apache ShardingSphere 5.0.0 内核优化及升级指南
经过近两年时间的优化和打磨,Apache ShardingSphere 5.0.0 GA 版终于在本月正式发布,相比于 4.1.1 GA 版,5.0.0 GA 版在内核层面进行了大量的优化.首先,基于 ...
- Nacos 发布 1.0.0 GA 版本,可大规模投入到生产环境
经过 3 个 RC 版本的社区体验之后,Nacos 正式发布 1.0.0 GA 版本,在架构.功能和 API 设计上进行了全方位的重构和升级. 1.0.0 版本的发布标志着 Nacos 已经可以大规模 ...
- HarmonyOS 3.0.0开发者预览版全新发布
2021年10月22日在华为开发者大会HDC.Together 2021 主题演讲上,我们发布了HarmonyOS 3.0.0开发者预览版,主要内容包括:Harmony设计系统.ArkUI 3.0.A ...
- mongo链接报错:couldn't connect to server 127.0.0.1:27017 (127.0.0.1)
angela@angeladeMacBook-Air:/data/db$mongo MongoDB shell version: 2.6.1 connecting to: test 2014-06-0 ...
随机推荐
- git 使用代理出现 LibreSSL SSL_connect: SSL_ERROR_SYSCALL in connection to github.com:443 错误
删除代理即可. 具体操作如下: 1. git config --global --list 查看git配置 发现其中有 http.https.XXXXXX.proxy 和 https.http ...
- linux》centos6.1.环境下发送邮件设置
转自https://blog.csdn.net/bodybo/article/details/80817968 一. Sendmail安装 在CentOS下,sendmail一般默认是随操作系统一起安 ...
- Vivado实战—单周期CPU指令分析
引言 不知道你是否和我有过同样的感受,<计算机组成原理>这门学科学起来如此的艰难:一节课下来,教室黑板上留下了满满的 "足迹",看上去也挺简单的,不就是 0 和 1 ...
- 微信小程序 转盘抽奖 倒计时 整点
xml: <view id="luckdraw_box"> <view id="luckdraw_back"> <image st ...
- a、b、n为正整数且a>b,证明:若n|(a^n-b^n),则n|(a^n-b^n)/(a-b).
- Android系统编程入门系列之应用内键值对数据的简单保存
在应用程序间及与用户的通信交互过程中,会产生并传递一系列数据.针对这些数据,有部分是只在应用程序中使用的缓存数据,还有一部分是在不同位置多次或长时间使用的持久化数据. 对于缓存数据来说,通常以代码中定 ...
- MySQL存储结构及SQL分类
MySQL目录结构 bin -- mysql执行程序 docs -- 文档 share - 各国编码信息 data -- 存放mysql 数据文件 * 每个数据库 创建一个同名文件夹,.frm 存放t ...
- opengl中标准矩形像素点手动网格化为三角形条带的实现
这里以一张矩形图片为例进行说明: 一张图片的像素点是孤立的,导入opengl中进行绘制出来,看起来没问题,但是当我们放大图片时候,显示的就是一个个孤立的点,而没有像看图软件放大图片那样看起来还是连续的 ...
- kubernetes使用jenkins Pipeline 部署Nginx
文章原文 环境需求 kubernetes 未安装参考使用kubeadm安装kubernetes 1.21 jenkins github/gitee/gitlab 静态页面 镜像仓库(我使用的 hub. ...
- 这些解决 Bug 的套路,你都会了不?
最近整理了我原创的 140 篇编程经验和技术文章,欢迎大家阅读,一起成长!指路:https://t.1yb.co/ARnD 大家好,我是鱼皮. 学编程的过程中,我们会遇到各式各样的 Bug,也常常因为 ...