基于MCRA-OMLSA的语音降噪(一):原理
前面的几篇文章讲了webRTC中的语音降噪。最近又用到了基于MCRA-OMLSA的语音降噪,就学习了原理并且软件实现了它。MCRA主要用于噪声估计,OMLSA是基于估计出来的噪声去做降噪。类比于webRTC中的降噪方法,也有噪声估计(分位数噪声估计法)和基于估计出来的噪声降噪(维纳滤波),MCRA就相当于分位数噪声估计法,OMLSA就相当于维纳滤波。本文先讲讲怎么用MCRA和OMLSA来做语音降噪的原理,后续会讲怎么来做软件实现。
一, MCRA
MCRA的全称是Minima Controlled Recursive Averaging(最小值控制的递归平均),是cohen提出的一种常用的噪声估计方法,具体见论文《Noise Estimation by Minima Controlled Recursive Averaging for Robust Speech Enhancement》。 从名字就可看出这个方法主要包括两部分,最小值控制和递归平均。 最小值控制用来算语音存在概率,递归平均用来做噪声估计,即基于语音存在概率做噪声估计。先定义一些名称,然后分别看这两部分。用l表示第l帧,k表示第k个频点,Y(k, l)表示带噪语音第l帧的第k个频点的幅度谱,N(k, l)表示噪声第l帧的第k个频点的幅度谱,S(k, l)表示干净语音第l帧的第k个频点的幅度谱,H0(k, l)表示第l帧的第k个频点上只有噪声,H1(k, l)表示第l帧的第k个频点上有语音。P(H1(k, l) | Y(k, l)) 表示第l帧的第k个频点上是语音的概率,P(H0(k, l) | Y(k, l)) 表示第l帧的第k个频点上是噪声的概率,显然P(H0(k, l) | Y(k, l)) + P(H1(k, l) | Y(k, l)) = 1。
1, 用最小值控制来算语音存在概率
前面的文章(webRTC中语音降噪模块ANS细节详解(四))讲过webRTC的ANS是基于似然比等来算语音存在概率。而这里是用最小值控制来算语音存在概率,即基于当前带噪语音的能量谱与指定长度帧内带噪语音的能量谱的最小值的比值来计算,具体如下:
1) 对带噪语音的能量谱做频域平滑和时域平滑
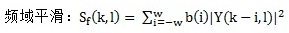
从上式可见,平滑窗的长度是奇数(2w + 1),系数是b(i)。
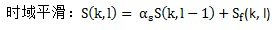
其中,αs (0 < αs < 1)是平滑因子。
2) 搜索能量谱最小值
定义Smin(k, l)和Stmp(k, l),并对它们初始化如下:

然后按频点从第一帧开始逐帧比较:
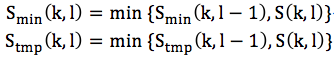
当到第L帧后:
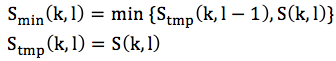
后面以L帧为一个周期,重复上面两步,得到这个周期内的Smin(k, l)和Stmp(k, l)。搜索窗的帧长度L会影响到噪声的跟踪速度,一般按照经验选0.5s~1.5s左右。
3) 计算语音存在概率
定义Sr(k, l)为当前帧相应频点的能量谱与最小值的比值,即
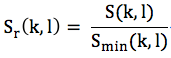
再定义二值I (k, l)如下:
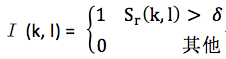
最终语音存在概率通过下式得到:
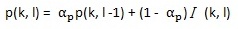
其中,αp (0 < αp < 1)是平滑因子。此处的p(k, l)就是P(H1(k, l) | Y(k, l))。为书写方便,下文用p表示P(H1(k, l) | Y(k, l)),用1-p表示P(H0(k, l) | Y(k, l))。
2, 用递归平均来估计噪声
通常认为噪声都是加性噪声,所以有下式:
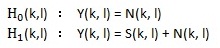
定义σ(k, l)表示第l帧的第k个频点上的噪声能量谱。这里噪声更新的思路如下:当语音不存在时更新噪声的估计,当语言存在时用前一帧的噪声估计值作为当前噪声的估计值,表示如下式:
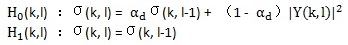
其中,αd (0 < αd < 1)是平滑因子。
所以噪声能量谱的估计如下式(p = P(H1(k, l) | Y(k, l)),为语音存在概率):
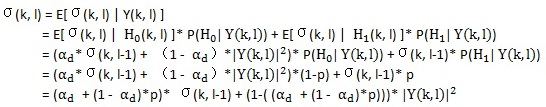
αd是tuning出来的,每个频点上的语音存在概率是上面基于最小控制的方法算出来的,上一帧估计出来的噪声能量谱σ(k, l-1)和当前帧的带噪语音的能量谱均已知,这样当前帧的估计出来的噪声的能量谱就可求出了。
通常令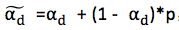 ,这样上式就可写成下式:
,这样上式就可写成下式:
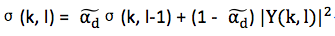
这就是噪声估计的数学表达式。
二, OMLSA
噪声估计出来后就要基于它做降噪了。这里用的是OMLSA(Optimally Modified Log-Spectral Amplitude Estimator,最优修正的对数幅度谱估计),依旧是cohen提出来的,论文是《Optimal Speech Enhancement Under Signal Presence Uncertainty Using Log-Spectral Amplitude Estimator》。OMLSA是MMSE-LSA的改进算法,目的是得到增益gain。算法推导有些复杂,这里只给出gain的表达式,如下:
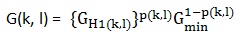
其中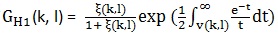 ,Gmin为预先设定的值,p(k, l)是语音存在概率。这里
,Gmin为预先设定的值,p(k, l)是语音存在概率。这里 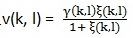 , ξ(k, l)是先验性噪比,γ(k, l)是后验性噪比。先验性噪比和后验性噪比在文章(webRTC中语音降噪模块ANS细节详解(一))中讲过。后验性噪比的计算基于上面用MCRA估计出来的噪声,
, ξ(k, l)是先验性噪比,γ(k, l)是后验性噪比。先验性噪比和后验性噪比在文章(webRTC中语音降噪模块ANS细节详解(一))中讲过。后验性噪比的计算基于上面用MCRA估计出来的噪声, , 先验性噪比计算依旧用文章(webRTC中语音降噪模块ANS细节详解(三))中提到的DD方法,表达式如下:
, 先验性噪比计算依旧用文章(webRTC中语音降噪模块ANS细节详解(三))中提到的DD方法,表达式如下:
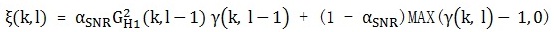
其中,αSNR (0 < αSNR < 1)是平滑因子。
G(k, l)得到后,降噪后干净语音的每个频点的幅度谱可通过下式得到:
S(k, l) = G(K, l)Y(k, l)
以上就是基于MCRA-OMLSA的语音降噪原理。这里需要指出的是噪声估计和语音降噪相对独立,有不同的组合方式来降噪,比如MCRA也可以和维纳滤波结合来降噪。
基于MCRA-OMLSA的语音降噪(一):原理的更多相关文章
- webRTC中语音降噪模块ANS细节详解(一)
ANS(adaptive noise suppression) 是webRTC中音频相关的核心模块之一,为众多公司所使用.从2015年开始,我在几个产品中使用了webRTC的3A(AEC/ANS/AG ...
- 基于MCRA-OMLSA的语音降噪(二):实现
上篇文章(基于MCRA-OMLSA的语音降噪(一):原理)讲了基于MCRA-OMLSA降噪的原理,本篇讲怎么做软件实现.软件实现有多种方式.单纯看降噪效果可用python,因为python有丰富的库可 ...
- 基于MCRA-OMLSA的语音降噪(三):实现(续)
上篇文章(基于MCRA-OMLSA的语音降噪(二):实现)讲了基于MCRA-OMLSA的语音降噪的软件实现.本篇继续讲,主要讲C语言下怎么对数学库里的求平方根(sqrt()).求自然指数(exp()) ...
- 语音降噪论文“A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier”的研读
最近认真的研读了这篇关于降噪的论文.它是一种利用混合模型降噪的方法,即既利用了生成模型(MoG高斯模型),也利用了判别模型(神经网络NN模型).本文根据自己的理解对原理做了梳理. 论文是基于" ...
- webRTC中语音降噪模块ANS细节详解(二)
上篇(webRTC中语音降噪模块ANS细节详解(一))讲了维纳滤波的基本原理.本篇先给出webRTC中ANS的基本处理过程,然后讲其中两步(即时域转频域和频域转时域)中的一些处理细节. ANS的基本处 ...
- webRTC中语音降噪模块ANS细节详解(三)
上篇(webRTC中语音降噪模块ANS细节详解(二))讲了ANS的处理流程和语音在时域和频域的相互转换.本篇开始讲语音降噪的核心部分,首先讲噪声的初始估计以及基于估计出来的噪声算先验信噪比和后验信噪比 ...
- webRTC中语音降噪模块ANS细节详解(四)
上篇(webRTC中语音降噪模块ANS细节详解(三))讲了噪声的初始估计方法以及怎么算先验SNR和后验SNR. 本篇开始讲基于带噪语音和特征的语音和噪声的概率计算方法和噪声估计更新以及基于维纳滤波的降 ...
- 基于简单sql语句的sql解析原理及在大数据中的应用
基于简单sql语句的sql解析原理及在大数据中的应用 李万鸿 老百姓呼吁打土豪分田地.共同富裕,总有一天会实现. 全面了解你所不知道的外星人和宇宙真想:http://pan.baidu.com/s/1 ...
- 基于LNMP(fastcgi协议)环境部署、原理介绍以及fastcgi_cache配置以及upstream模块负载均衡讲解
ngx_http_proxy_module只能反向代理后端使用HTTP协议的主机.而ngx_http_fastcgi_module只能反向代理后端使用FPM或者使用FastCGI协议的客户端. 一.部 ...
随机推荐
- [bzoj5291]链上二次求和
记$bi=b_{i-1}+ai$,$ci=c_{i-1}+bi$,那么答案就是$\sum_{i=l}^{r}\sum_{j=0}^{n-i}b_{j+i}-bj=(r-l+1)cn-\sum_{i=l ...
- /dev/random 和 /dev/urandom 的原理
/dev/null 是一个特殊的设备文件,它丢弃一切写入其中的数据 可以将它 视为一个黑洞, 它等效于只写文件, 写入其中的所有内容都会消失, 尝试从中读取或输出不会有任何结果,同样,/dev/nul ...
- python之元编程
一.什么是元编程 元编程是一种编写计算机程序的技术,这些程序可以将自己看作数据,因此你可以在运行时对它进行内省.生成和/或修改. Python在语言层面对函数.类等基本类型提供了内省及实时创建和修改的 ...
- FFT/NTT复习笔记&多项式&生成函数学习笔记Ⅰ
众所周知,tzc 在 2019 年(12 月 31 日)就第一次开始接触多项式相关算法,可到 2021 年(1 月 1 日)才开始写这篇 blog. 感觉自己开了个大坑( 多项式 多项式乘法 好吧这个 ...
- 洛谷 P2791 - 幼儿园篮球题(第二类斯特林数)
题面传送门 首先写出式子: \[ans=\sum\limits_{i=0}^m\dbinom{m}{i}\dbinom{n-m}{k-i}·i^L \] 看到后面有个幂,我们看它不爽,因此考虑将其拆开 ...
- char *p、char p[]、字符串的几个题目
总结一下遇到的关于char *p.char p[]和字符串的题目: 例一:(指针的指针) 1 void getmemory(char **p) 2 { 3 p = (char *)malloc(100 ...
- WPS for Linux 字体配置(字体缺失解决办法)
WPS for Linux 字体配置(字体缺失解决办法) 1. 背景 有些linux装完wps后提示"部分字体无法显示"或"some formula symbols mi ...
- 日常Java 2021/10/21
Java Iterator(迭代器) 如果需要使用iterator类需要从java.util包中引入它 Java Iterator不是一个集合,它是一种访问集合的方法,用于迭代ArrayList和Ha ...
- jQuery无限载入瀑布流 【转载】
转载至 http://wuyuans.com/2013/08/jquery-masonry-infinite-scroll/ jQuery无限载入瀑布流 好久没更新日志了,一来我比较懒,二来最近也比较 ...
- 转 序列化Serializable和Parcelable的区别详解
什么是序列化,为什么要进行序列化 答:对象要进行传输(如:activity 与activity间 ,网络间 进程间等等).存储到本地就必须进行序列化 . 这种可传输的状态就是序列化. 怎么序列化??两 ...