各类分布----二项分布,泊松分布,负二项分布,gamma 分布,高斯分布,学生分布,Z分布
伯努利实验:
如果无穷随机变量序列  是独立同分布(i.i.d.)的,而且每个随机变量
是独立同分布(i.i.d.)的,而且每个随机变量  都服从参数为p的伯努利分布,那么随机变量 就形成参数为p的一系列伯努利试验。同样,如果n个随机变量
都服从参数为p的伯努利分布,那么随机变量 就形成参数为p的一系列伯努利试验。同样,如果n个随机变量  独立同分布,并且都服从参数为p的伯努利分布,则随机变量 形成参数为p的n重伯努利试验。
独立同分布,并且都服从参数为p的伯努利分布,则随机变量 形成参数为p的n重伯努利试验。
伯努利试验是只有两种可能结果的单次随机试验。
- 如果试验E是一个伯努利试验,将E独立重复地进行n次,则称这一串重复的独立试验为n重伯努利试验。
一、伯努利分布:
伯努利分布亦称“零一分布”、“两点分布”。称随机变量X有伯努利分布, 参数为p(0<p<1),如果它分别以概率p和1-p取1和0为值。EX= p,DX=p(1-p)。伯努利试验成功的次数服从伯努利分布,参数p是试验成功的概率。伯努利分布是一个离散型机率分布,是N=1时二项分布的特殊情况,为纪念瑞士科学家詹姆斯·伯努利(Jacob Bernoulli 或James Bernoulli)而命名。
例子:假定重复抛掷一枚均匀硬币,如果在第i次抛掷中出现正面,令  ;如果出现反面,令
;如果出现反面,令  ,那么,随机变量 就形成参数为
,那么,随机变量 就形成参数为  的一系列伯努利试验,同样,假定由一个特定机器生产的零件中10%是有缺陷的,随机抽取n个进行观测,如果第i个零件有缺陷,令
的一系列伯努利试验,同样,假定由一个特定机器生产的零件中10%是有缺陷的,随机抽取n个进行观测,如果第i个零件有缺陷,令 ;如果没有缺陷,令
;如果没有缺陷,令  ,那么,随机变量 就形成参数为
,那么,随机变量 就形成参数为  的n重伯努利试验 (百度百科)
的n重伯努利试验 (百度百科)
E(X)=p, E(X2)=q , Var(X)=pq

二、二项分布:
n 次Bernoulli试验的结果中,每次试验的分布不变,结果为1的次数 X 的分布。就是重复n次的伯努利实验。
在概率论和统计学里面,带有参数n和p的二项分布表示的是n次独立试验的成功次数的概率分布。在每次独立试验中只有取两个值,表示成功的值的概率为p,那么表示试验不成功的概率为1-p。这样一种判断成功和失败的二值试验又叫做伯努利试验。
特殊地,当n=1的时候,我们把二项分布称为伯努利分布。

超几何分布,n 次伯努利试验,每次试验分布发生改变,结果为1的次数 X 的分布,当试验分布变化不大的时候和二项分布结果相同
它描述了从有限N个物件(其中包含M个指定种类的物件)中抽出n个物件,成功抽出该指定种类的物件的次数(不放回)


泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生次数。 泊松分布适合于描述单位时间内随机事件发生的次数。
k事件X发生的频数;P(X=k)事件X发生k次的概率
泊松分布的期望和方差均为 
特征函数为 
当二项分布的n很大而p很小时,泊松分布可作为二项分布的近似,其中λ为np。通常当n≧20,p≦0.05时,就可以用泊松公式近似得计算,当n趋近于无穷的时候等同于二项分布。
五、多项分布
是二项式分布的推广。二项式做n次伯努利实验,规定了每次试验的结果只有两个,如果现在还是做n次试验,只不过每次试验的结果可以有多m个,且m个结果发生的概率互斥且和为1,则发生其中一个结果X次的概率就是多项式分布。
扔骰子是典型的多项式分布。扔骰子,不同于扔硬币,骰子有6个面对应6个不同的点数,这样单次每个点数朝上的概率都是1/6(对应p1~p6,它们的值不一定都是1/6,只要和为1且互斥即可,比如一个形状不规则的骰子),重复扔n次,如果问有k次都是点数6朝上的概率。
六、负二项分布
一种离散概率分布。满足以下条件的称为负二项分布:实验包含一系列独立的实验, 每个实验都有成功、失败两种结果,成功的概率是恒定的,实验持续到r次成功,r为正整数。

它表示,已知一个事件在伯努利试验中每次的出现概率是p,在一连串伯努利试验中,一件事件刚好在第r + k次试验出现第r次的概率。
 。
。七、gamma分布
是统计学的一种连续概率函数。
gamma函数定义:
Γ(x) = ∫0∞ tx-1 e-t dt Γ(x+1) = x Γ(x); Γ(x+1) = x!
Gamma分布中的参数α称为形状参数(shape parameter),β称为逆尺度参数(scale parameter)




的数值。

时,

为递减函数;

时,
为递增函数;
 时,
时,
为单峰函数;
八、指数分布
指数分布是事件的时间间隔的概率。如:
婴儿出生的时间间隔
来电的时间间隔
奶粉销售的时间间隔
网站访问的时间间隔
是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。 这是伽马分布的一个特殊情况,它是几何分布的连续模拟,它具有无记忆的关键性质。
指数函数的一个重要特征是无记忆性(Memoryless Property,又称遗失记忆性)。这表示如果一个随机变量呈指数分布,当s,t>0时有P(T>t+s|T>t)=P(T>s)。即,如果T是某一元件的寿命,已知元件使用了t小时,它总共使用至少s+t小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。
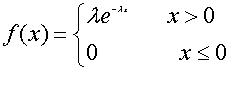
期望值:  ,方差:
,方差:  若随机变量x服从参数为λ的指数分布,则记为
若随机变量x服从参数为λ的指数分布,则记为  。
。
九、卡方分布
若n个相互独立的随机变量ξ₁,ξ₂,...,ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和  构成一新的随机变量,其分布规律称为卡方分布(chi-square distribution)。其中参数
构成一新的随机变量,其分布规律称为卡方分布(chi-square distribution)。其中参数  称为自由度。记为
称为自由度。记为  或者
或者  (其中
(其中  ,
,  为限制条件数)。
为限制条件数)。
卡方分布是由正态分布构造而成的一个新的分布,当自由度 很大时,
很大时,  分布近似为正态分布。
分布近似为正态分布。
1) 分布在第一象限内,卡方值都是正值,呈正偏态(右偏态),随着参数  的增大, 分布趋近于正态分布;卡方分布密度曲线下的面积都是1.
的增大, 分布趋近于正态分布;卡方分布密度曲线下的面积都是1.
2) 分布的均值与方差可以看出,随着自由度 的增大,χ2分布向正无穷方向延伸(因为均值
的增大,χ2分布向正无穷方向延伸(因为均值  越来越大),分布曲线也越来越低阔(因为方
越来越大),分布曲线也越来越低阔(因为方  越来越大)。
越来越大)。
 互相独立,则:
互相独立,则:

服从
分布,自由度为





十、Beta分布
B函数,又称为Beta函数或者第一类欧拉积分,是一个作为伯努利分布和二项式分布的共轭先验分布的密度函数,是指一组定义在(0,1) 区间的连续概率分布,定义如下:
有两个参数 







实例:
十一、几何分布
是离散型概率分布。在n次伯努利试验中,试验k次才得到第一次成功的机率。详细地说,是:前k-1次皆失败,第k次成功的概率。几何分布是帕斯卡分布当r=1时的特例。





十二、学生分布(t分布)
用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。
t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。
 分布,那么
分布,那么

的分布称为自由度为n的t分布,记为

。

,其中,Gam(x)为伽马函数。
十三、正态分布
十四、狄利克雷分布
狄利克雷分布(Dirichlet distribution)是多项分布的共轭分布,也就是它与多项分布具有相同形式的分布函数。同时可以看做是将Beta分布推广到多变量的情形。一类在实数域以正单纯形(standard simplex)为支撑集(support)的高维连续概率分布,是Beta分布在高维情形的推广。
对独立同分布(independent and identically distributed, iid)的连续随机变量  和支撑集
和支撑集 ,若
,若 服从狄利克雷分布,则其概率密度函数
服从狄利克雷分布,则其概率密度函数

有如下定义 [1] :

 是
是
是分布参数的和,

是多元Beta函数(multivariate beta function),

为Gamma函数。由上述解析形式可知,狄利克雷分布是指数族分布 [1] 。
应用
泊松分布和负二项分布用途区分
https://www.jianshu.com/p/ad24bb90b972
---------------------
原文:https://blog.csdn.net/tonyshengtan/article/details/82947416
各类分布----二项分布,泊松分布,负二项分布,gamma 分布,高斯分布,学生分布,Z分布的更多相关文章
- 从 高斯 到 正态分布 到 Z分布 到 t分布
正态分布是如何被高斯推导出来的, 我感觉高斯更像是猜出了正态分布. 详见这篇文章:<正态分布的前世今生> http://songshuhui.NET/archives/76501 说一说理 ...
- 统计学中z分布、t分布、F分布及χ^2分布
Z就是正态分布,X^2分布是一个正态分布的平方,t分布是一个正态分布除以(一个X^2分布除以它的自由度然后开根号),F分布是两个卡方分布分布除以他们各自的自由度再相除 比如X是一个Z分布,Y(n)=X ...
- 中心极限定理|z分布|t分布|卡方分布
生物统计学 抽样分布:n个样本会得到n个统计量,将这n个统计量作为总体,该总体的分布即是抽样分布 根据辛钦大数定律,从一个非正态分布的总体中抽取的含量主n的样本,当n充分大时,样本平均数渐近服从正态分 ...
- gamma函数及相关其分布
神奇的gamma函数(上) 神奇的gamma函数(下) gamma函数的定义及重要性质 \[\Gamma(x)=\int_0^{\infty}t^{x-1}e^{-t}dt\] \[\Gamma(x+ ...
- 《A First Course in Probability》-chaper4-离散型随机变量-负二项分布
基于我们最为熟悉的离散型分布——二项分布,我们能够衍生出很多别的分布列,对于之前介绍过的几何分布,我们赋予其的含义是:某个事件成功的概率是p,在n次独立重复实验中恰好成功一次的概率是多少.顺着这层含义 ...
- 《A First Course in Probability》-chape4-离散型随机变量-几种典型分布列
超几何分布: 超几何分布基于这样一个模型,一个坛子中有N个球,其中m个白球,N-m个黑球,从中随机取n(不放回),令X表示取出来的白球数,那么: 我们称随机变量X满足参数为(n,m,M)的超几何分布. ...
- 机器学习 Logistic Regression
Logistic Regression 之前我们讨论过回归问题,并且讨论了线性回归模型.现在我们来看看分类问题,分类问题与回归问题类似,只不过输出变量一个是离散的,一个是连续的.我们先关注二分类问题, ...
- CS299笔记:广义线性模型
指数分布族 我们称一类分布属于指数分布族(exponential family distribution),如果它的分布函数可以写成以下的形式: \[ \begin{equation} p(y;\et ...
- sysbench的安装与使用(with MySQL)
sysbench是一款开源的多线程性能测试工具,可以执行CPU/内存/线程/IO/数据库等方面的性能测试. 项目主页: http://sysbench.sourceforge.net/ 安装文档htt ...
随机推荐
- leetCode题解之寻找一个数在有序数组中的范围Search for a Range
1.问题描述 Given an array of integers sorted in ascending order, find the starting and ending position o ...
- 3.Spring MVC return url问题总结
一.return "cartSuccess" 和 return "redirect:/cart/cart.html" 的区别 二.return modelAnd ...
- XML与DataSet的相互转换的类
一.XML与DataSet的相互转换的类 using System; using System.Collections.Generic; using System.Text; using System ...
- 第一章:了解SQL_数据库基础
什么是数据库(database): 数据库(database)是保存有组织的数据的容器(通常是一个文件或一组文件).数据库是一种以某种有组织的方式存储的数据集合. 表(table): 表(tabl ...
- ps命令之排序
Linux中ps命令会自动选择一列进行排序,但有时这不是我们想要的. 方法一: ps+sort sort 选项与参数: -f :忽略大小写的差异,例如 A 与 a 视为编码相同:-b :忽略最前面 ...
- 安卓 USB摄像头 开源库 UVCCamera 教程
https://github.com/saki4510t/UVCCamera UVCCamera 听名字就知道使用UVC( USB VEDIO CLASS) 协议的通用类库.linux原生支持,基本支 ...
- 使用NSOperation以及NSOperationQueue
使用NSOperation以及NSOperationQueue NSOperation vs. Grand Central Dispatch (GCD) 在Mac OS X v10.6和iOS4之前, ...
- [翻译] CBStoreHouseRefreshControl
CBStoreHouseRefreshControl What is it? A fully customizable pull-to-refresh control for iOS inspired ...
- Linux at命令详解
at 只能执行一次,在一个指定的时间执行一个指定任务,只能执行一次,且需要开启atd进程 anacron: 适合于非 7*24 类型的服务器,以天为周期或者在系统开机后执行任务的工作 它会定时检测服务 ...
- 多数据源报错 expected single matching bean but found 2: xxx,xxx
问题: expected single matching bean but found 2: xxx,xxx 原因:在 Spring 容器中配置了两个类型Bean,Spring 容器将无法确定到底要用 ...