使用HttpGet协议与正则表达实现桌面版的糗事百科
打开糗事百科笑话的主页,在这里我只取糗事笑话中文字这一板块,点击文字这一菜单栏。如下图。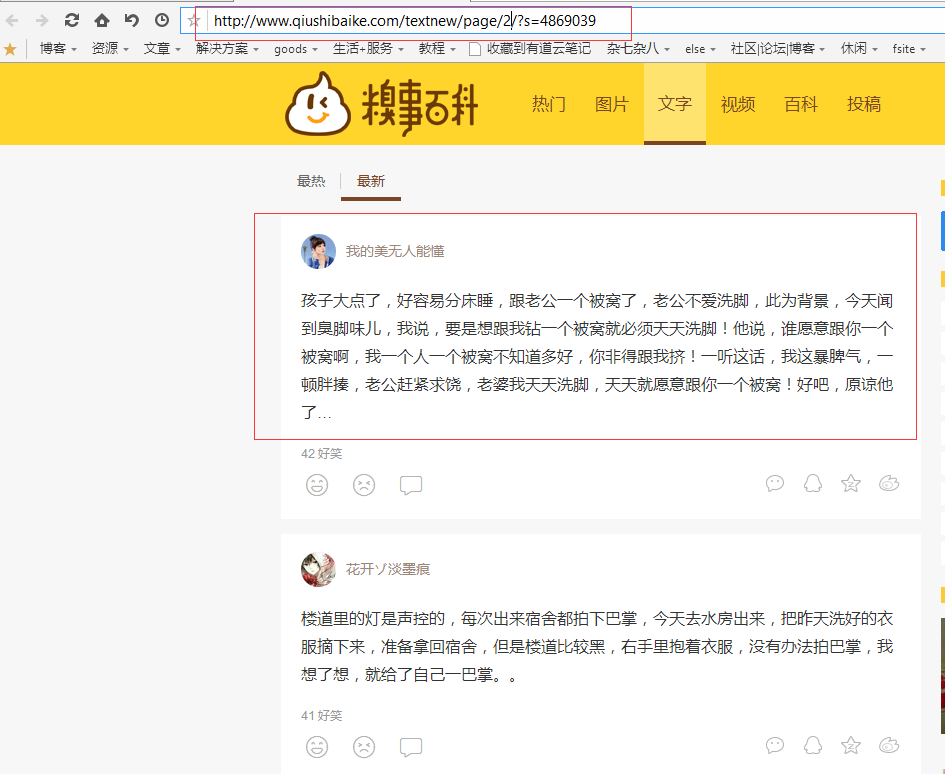
const string qsbkMainUrl = "http://www.qiushibaike.com";
//获取糗百文字笑话页的url
private static string GetWBJokeUrl(int pageIndex)
{
StringBuilder url = new StringBuilder();
url.Append(qsbkMainUrl);
url.Append ("/textnew/page/");
url.Append(pageIndex.ToString ());
url.Append("/?s=4869039");
return url.ToString();
}
//根据网页的url获取网页的html源码
private static string GetUrlContent(string url)
{
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
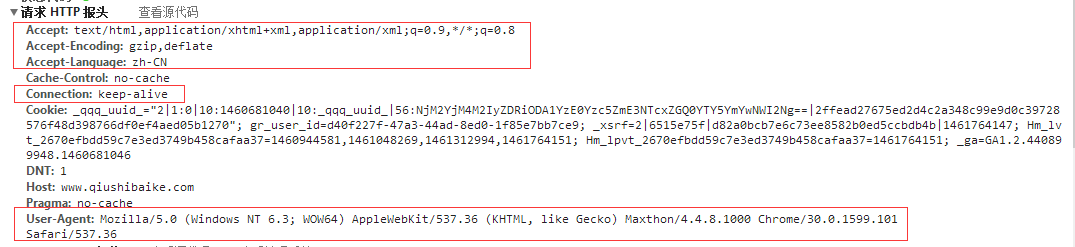
request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36";
request.Method = "GET";
request.ContentType = "text/html;charset=UTF-8";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));//因为知道糗百网页的编码方式为utf-8
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
catch { return null; }
}
在1中我们已经根据page页索引的不同而获取不同的页面内容,而这一步的任务就是如何从返回的html源代码中获取我们想要的笑话内容。
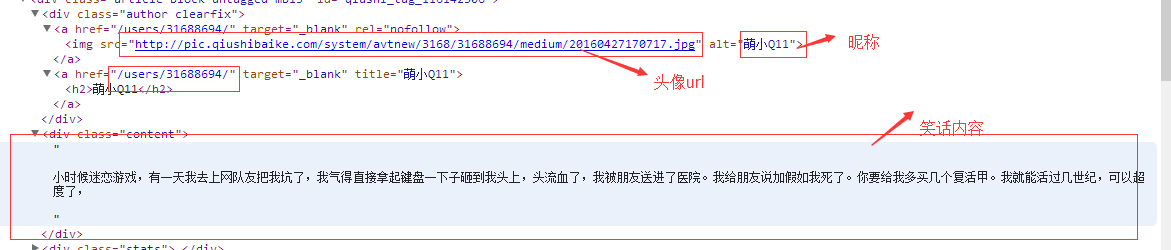
正则:<img src="([^"]*")\s*alt="([^"]*)"/>\s</a>\s<a href="([^"]*)"[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class="content">\s*((.*|<br/>)*)
public class JokeItem
{
private string nickName;
/// <summary>
/// 昵称
/// </summary>
public string NickName
{
get { return nickName; }
set { nickName = value; }
}
private Image headImage;
/// <summary>
/// 头像
/// </summary>
public Image HeadImage
{
get { return headImage; }
set { headImage = value; }
}
private string jokeContent;
/// <summary>
/// 笑话内容
/// </summary>
public string JokeContent
{
get { return jokeContent; }
set { jokeContent = value; }
}
private string jokeUrl;
/// <summary>
/// 笑话地址
/// </summary>
public string JokeUrl
{
get { return jokeUrl; }
set { jokeUrl = value; }
}
}
b、利用正则获取笑话内容
/// <summary>
/// 获取笑话列表
/// </summary>
/// <param name="htmlContent"></param>
public static List<JokeItem> GetJokeList(int pageIndex)
{
string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex));
List<JokeItem> jokeList = new List<JokeItem>();
Regex rg = new Regex(@"<img src=""([^""]*"")\s*alt=""([^""]*)""/>\s</a>\s<a href=""([^""]*)""[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class=""content"">\s*((.*|<br/>)*)", RegexOptions.IgnoreCase);
JokeItem joke;
MatchCollection matchResults = rg.Matches(htmlContent);
foreach (Match result in matchResults)
{
joke = new JokeItem();
joke.HeadImage = GetWebImage(result.Groups[].Value);
joke.HeadImage = joke.HeadImage != null ? new Bitmap(GetWebImage(result.Groups[].Value), , ) : null;
joke.NickName = result.Groups[].Value;
joke.JokeUrl = qsbkMainUrl + "/" + result.Groups[].Value; ;
joke.JokeContent = result.Groups[].Value.Replace("<br/>", "\r\n").Replace("<br>", "\r\n");
joke.JokeContent = Regex.Replace(joke.JokeContent, @"(\r\n)+", "\r\n");//去掉多余的空行
jokeList.Add(joke);
}
return jokeList;
}
c、根据头像url地址获取头像
private static Image GetWebImage(string webUrl)
{
try
{
Encoding encode = Encoding.GetEncoding("utf-8");//网页编码==Encoding.UTF8
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl));
HttpWebResponse ress = (HttpWebResponse)req.GetResponse();
Stream sstreamRes = ress.GetResponseStream();
return System.Drawing.Image.FromStream(sstreamRes);
}
catch { return null; }
}
3、数据绑定
使用HttpGet协议与正则表达实现桌面版的糗事百科的更多相关文章
- HttpGet协议与正则表达
使用HttpGet协议与正则表达实现桌面版的糗事百科 写在前面 最近在重温asp.net,找了一本相关的书籍.本书在第一章就讲了,在不使用浏览器的情况下生成一个web请求,获取服务器返回的内容.于 ...
- python+正则提取+ip代理爬取糗事百科文字信息
很多网站都有反爬措施,最常见的就是封ip,请求次数过多服务器会拒绝连接,如图: 在程序中设置一个代理ip,可有效的解决这种问题,代码如下: # 需要的库 import requests import ...
- Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)
1.博客目前在学习爬虫课程,使用正则表达式来爬取网页的图片信息 2.下面我们一起来回归下Python中的正则使用方式/方法 3.糗事百科图片爬取源码如下: import requestsimport ...
- python+正则+多进程爬取糗事百科图片
话不多说,直接上代码: # 需要的库 import requests import re import os from multiprocessing import Pool # 请求头 header ...
- Javascript正则构造函数与正则表达字面量&&常用正则表达式
本文不讨论正则表达式入门,即如何使用正则匹配.讨论的是两种创建正则表达式的优劣和一些细节,最后给出一些常用正则匹配表达式. Javascript中的正则表达式也是对象,我们可以使用两种方法创建正则表达 ...
- js正则表达test、exec和match的区别
test的用法和exec一致,只不过返回值是 true false. 以前用js很少用到js的正则表达式,即使用到了,也是诸如邮件名称之类的判断,网上代码很多,很少有研究,拿来即用. 最近开发遇到一些 ...
- 正则表达示 for Python3
前情提要 从大量的文字内容中找到自己想要的东西,正则似乎是最好的方法.也是写爬虫不可缺少的技能.所以,别墨迹了赶紧好好学吧! 教程来自http://www.runoob.com/python3/pyt ...
- Python之面向对象和正则表达(代数运算和自动更正)
面向对象 一.概念解释 面对对象编程(OOP:object oriented programming):是一种程序设计范型,同时也是一种程序开发的方法,实现OOP的程序希望能够在程序中包含各种独立而又 ...
- JS写法 数值与字符串的相互转换 取字符中的一部分显示 正则表达规则
http://www.imooc.com/article/15885 正则表达规则 <script type="text/javascript"> </scrip ...
随机推荐
- zookeeper基本操作
理解Zookeeper的一种方法是将他视为一个提供高可用性的文件系统.它没有文件和目录,但是有一个统一概念的节点,叫做znode,作为数据以及其他znode的容器.znode来自于一个层次级的命名空间 ...
- 清除float的方法
清除浮动有两种方法: 一种是加入clear:both: 一种是BFC申明: <!doctype html><html><head><meta charset= ...
- day 31 html(二) 和css入门
前情提要: 本次主要是继续昨天学的简单的html 补充以及 css的简单入门 一:表单标签 >1:get请求 <!DOCTYPE html> <html lang=" ...
- git命令上传项目到码云总结
码云上传项目git命令总结: git clone https://git.oschina.net/xh-lxx/xh-lxx.oschina.io.git 进入到克隆下来的文件夹,然后操作git命令 ...
- Storm实现单词统计代码
import java.io.File; import java.io.IOException; import java.util.Collection; import java.util.HashM ...
- (转)LINUX CENTOS7下安装PYTHON
LINUX CENTOS7下安装PYTHON 原文:http://www.cnblogs.com/lclq/p/5620196.html Posted on 2016-06-27 14:58 南宫羽香 ...
- Java之集合(九)LinkedHashMap
转载请注明源出处:http://www.cnblogs.com/lighten/p/7367525.html 1.前言 前一章对Map中的HashMap进行了讲解(虽然只详细介绍了一下红黑树的部分), ...
- postman—Runner的使用
1.首先在postman新建要批量运行的接口文件夹,新建一个接口,并设置好全局变量. 2.然后在Test里面设置好要断言的方法 如: pm.test("Status code is 200& ...
- IE10以下优雅降级(作为范例)
扒下来一段 优雅降级的代码. <!--[if lt IE 10]> <style> .ie-tip{margin-top: 100px;font-size: 16px;text ...
- ELK构建MySQL慢日志收集平台详解
上篇文章<中小团队快速构建SQL自动审核系统>我们完成了SQL的自动审核与执行,不仅提高了效率还受到了同事的肯定,心里美滋滋.但关于慢查询的收集及处理也耗费了我们太多的时间和精力,如何在这 ...