nodejs实现拉钩网爬虫
概述
详细
一、准备工作
1、安装最新版本的nodejs,其中npm会被自动安装
2、安装该项目需要的包
npm install cheerio jsdom mysql request -S
其中package.json中的内容为:
"dependencies": {
"cheerio": "^1.0.0-rc.1",
"jsdom": "^11.0.0",
"mysql": "^2.13.0",
"request": "^2.81.0"
}
二、程序实现
1、程序实现的目录结构如下:
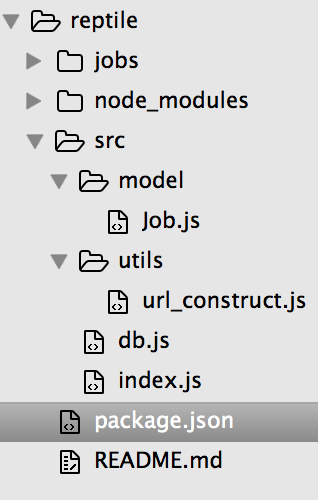
2、实现思路如下:
index.js:程序主文件,各种数据清洗工作,url构造在这个文件中完成
Job.js : 用于构建Job对象,有助于写入数据库
db.js:连接数据库并写入数据
url_construct.js:可以自己配置抓取那些公司的职位信息。如阿里巴巴,百度,腾讯等。部分代码如下:
const companyNames = ["网易","阿里巴巴","百度","腾讯","去哪儿","浪潮"];
const encodedCompanyNames = [];
//转化为urlencoded
for(let i=0;i<companyNames.length;i++){
encodedCompanyNames.push(encodeURIComponent(companyNames[i]));
}
module.exports = encodedCompanyNames;
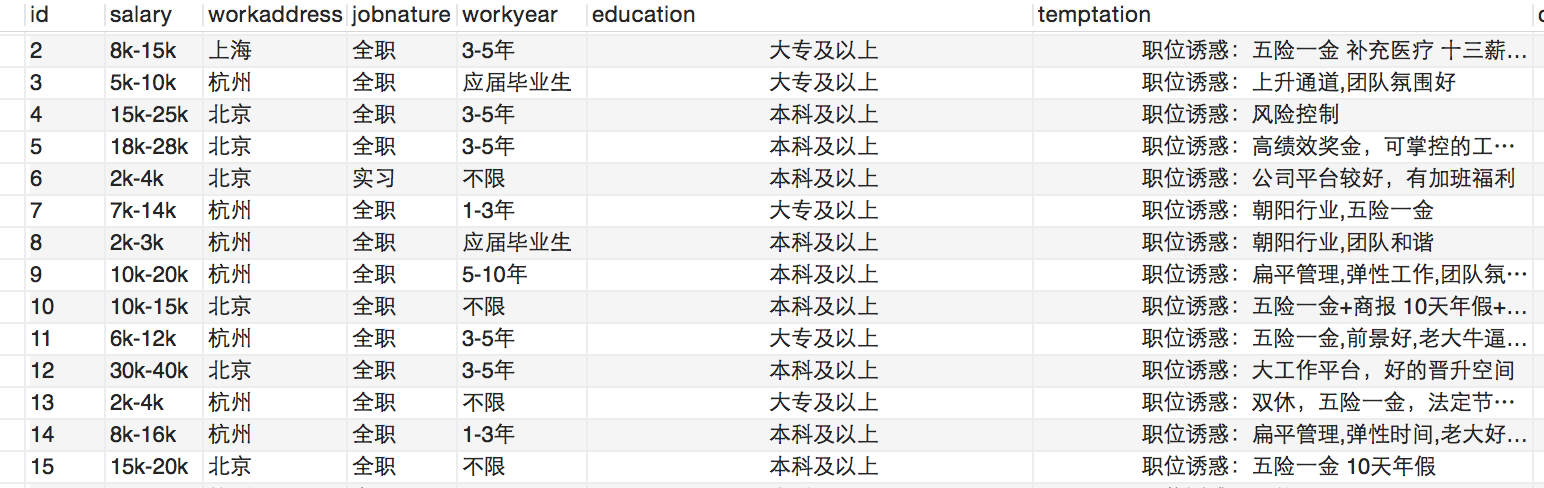
3、数据库设计截图

上面是本例子的数据库截图,其中id是主键,同时是自增的。
4、连接数据库注意点
下面的user和password的值是你安装数据库时候设置的,请自己修改
const pool = mysql.createPool({
connectionLimit:10,
database:TEST_DATABASE,
user:"root",
password:"root"
});
三、运行效果
首先cd到src目录下,然后简单的运行下面的命令就可以了:
node index.js
下面是数据库抓取的部分信息截图:
四、其他补充
如果你需要增加更多功能,可以在demo大师的"没有找到例子?"功能提出,我会增加例子,谢谢
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
nodejs实现拉钩网爬虫的更多相关文章
- day 112天,爬虫(拉钩网,斗音,GitHub)第二天
提前准备工作.安装准备工作(day3用) 1. 安装scrapy https://www.cnblogs.com/wupeiqi/articles/6229292.html a. 下载twiste ...
- Python3网络爬虫之requests动态爬虫:拉钩网
操作环境: Windows10.Python3.6.Pycharm.谷歌浏览器目标网址: https://www.lagou.com/jobs/list_Python/p-city_0?px=defa ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- 拉钩网爬取所有python职位信息
最近在找工作,所以爬取了拉钩网的全部python职位,以便给自己提供一个方向.拉钩网的数据还是比较容易爬取的,得到json数据直接解析就行,废话不多说, 直接贴代码: import json impo ...
- 使用request爬取拉钩网信息
通过cookies信息爬取 分析header和cookies 通过subtext粘贴处理header和cookies信息 处理后,方便粘贴到代码中 爬取拉钩信息代码 import requests c ...
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...
- 爬取拉钩网上所有的python职位
# 2.爬取拉钩网上的所有python职位. from urllib import request,parse import json,random def user_agent(page): #浏览 ...
- Python 爬取拉钩网工作岗位
如果拉钩网html页面做了调整,需要重新调整代码 代码如下 #/usr/bin/env python3 #coding:utf-8 import sys import json import requ ...
- ruby 爬虫爬取拉钩网职位信息,产生词云报告
思路:1.获取拉勾网搜索到职位的页数 2.调用接口获取职位id 3.根据职位id访问页面,匹配出关键字 url访问采用unirest,由于拉钩反爬虫,短时间内频繁访问会被限制访问,所以没有采用多线程, ...
随机推荐
- Windows 7 下玩游戏不能全屏
问题描述:许多用户反映,在 Windows 7 环境下,全屏游戏时两边屏幕都是黑的,只好窗口运行了.其实这是正常现象:有些游戏本身并没有提供宽屏分辨率支持.其图形界面都是按照一定比例(如 4:3)来设 ...
- Spring注解方式实现任务调度【官方文档翻译】
原文:http://docs.spring.io/spring/docs/4.0.1.BUILD-SNAPSHOT/javadoc-api/ 注解类型:EnableScheduling @Target ...
- Java读取properties配置文件时,中文乱码解决方法
public static String getConfig(String key) { Properties pros = new Properties(); String value = &quo ...
- SpringMVC @RequestBody 接收Json数组对象
@RequestMapping(value="/signIn",method=RequestMethod.POST) public int saveUser(@RequestBod ...
- 解决Sqoop报错Could not load db driver class: com.intersys.jdbc.CacheDriver
报错栈: // :: INFO tool.CodeGenTool: Beginning code generation // :: ERROR sqoop.Sqoop: Got exception r ...
- 简明python教程 --C++程序员的视角(六):输入输出IO
程序与用户交互 你会从用户那里得到输入,然后打印一些结果.我们可以分别使用raw_input,input和print语句来完成这些功能.raw_input会返回字符串,而input会返回字面值,相当于 ...
- iOS:UIView视图与组件控件
一.UIView常见属性 (1)@property(nonatomic,readonly)UIView *superview; //获取自己的父控件对象 (2)@property(nonatomi ...
- vb.net结构化异常处理和“邪用”
vb.net中的错误处理包括两种:非结构化异常处理技术和结构化异常处理.非结构化异常处理技术在vb 6.0中使用的比较普遍,即通过Err对象和ON Error.Go To.Resume等语句来实现.这 ...
- go语言基础之随机数的使用
1.随机数的使用 示例1: 如果种子参数一样,每次运行程序产生的随机数都一样 package main //必须有个main包 import "fmt" import &quo ...
- Android之属性动画(一)
一.概述 Android平台中常用的动画主要有两类,一类是View动画,一类是3.0后新增的属性动画.属性动画与View动画相比功能更加强大,主要体现在以下两个方面: 1. 属性动画不仅仅能应用到V ...