文本挖掘之文本聚类(MapReduce)
刘 勇 Email:lyssym@sina.com
简介
针对大数量的文本数据,采用单线程处理时,一方面消耗较长处理时间,另一方面对大量数据的I/O操作也会消耗较长处理时间,同时对内存空间的消耗也是很大,因此,本文引入MapReduce计算模型,以分布式方式处理文本数据,以期提高数据处理速率。本文结合Kmeans和DBSCAN算法,对上述算法进行改进,其中借鉴Kmeans聚类方法(类别个数的确定性)以及DBSCAN聚类方法(基于密度),并在数据处理过程中引入多个Reducer对数据进行归并处理。测试结果表明:在文本个数为457条,迭代次数为50次时,该算法具有可行性;但是在数据规模较小时,其处理速率较单线程处理存在一定的劣势,但是当数据量继续增大(数据量达到一定规模)时,基于分布式的算法,其速率优势会更加明显。
相关模型
本文本着以实际工程应用的角度,针对其中涉及到的数学模型简要描述如下,更多内容请参考本系列之前的内容:
1)余弦相似度
本文在判别Web 文本数据相似度时,采用余弦定理对其进行判别,即将两篇Web文本先中文分词后进行量化,然后计算上述两个向量的余弦值,进而对其进行判定相似度,其中为了让处理结果更加准确,引入了同义词词林,即加载同义词词典。更多内容在此不再赘述,详细内容见本系列之文本挖掘之文本相似度判定。
2)DBSCAN
DBSCAN聚类方法涉及两个重要的参数,即e邻域(近似理解为半径)和最少个数minPts(某一个固定值,即密度标识),上述参数表征在某个对象(理解为某一Web文本数据)的e邻域内对象数据个数大于minPts,则该对象为核心对象;然后根据该核心对象的e邻域内某一个对象i,选择对象i的e邻域内核心对象或边缘对象,继而持续递归,从而将上述所有寻找到的数据归为一个聚类集合。DBSCAN的目的在于寻找密度相连对象的最大集合,浅显的解释为,通过A可以找到B,通过B可以找到C,则A、B和C为同一聚类。更多内容在此不再赘述,详细内容见本系列之文本挖掘之文本聚类(DBSCAN)。
3)Kmeans
Kmeans聚类方法先初始化K(K在聚类前就已确定,需要指出,DBSCAN方法在聚类前的类别个数是无法知道的)个聚类中心(即质心),然后将文本数据与聚类中心比较,与哪个聚类中心更合适(本文以余弦相似度表征)则与该聚类中心为一类,一轮过后则重新计算各个聚类中心(即质心),并进行迭代,直至最终收敛或者达到迭代次数为止。其中在聚类中心计算中引入DBSCAN方法中基于密度的思维,即在某一类中,若某个向量的密度最大,则该节点向量成为新的质心,较其它算法采用距离统计的算法有所创新。更多内容在此不再赘述。
基于MapReduce的改进算法实现
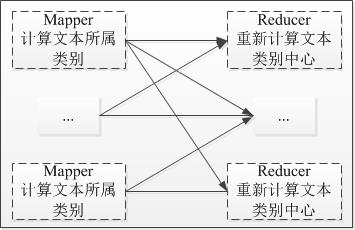
图-1 基于MapReduce的改进算法框架图
如图-1所示,为基于MapReduce的改进算法,单次执行框架图。对该框架中部分核心内容解释如下:
1) 在Mapper端,借鉴Kmeans算法确定K个类别及其初始质心,然后根据该质心,将所有文本进行一次聚类,以相似度与哪个质心相近,则属于质心属于该类别。
2)在Reducer端,借鉴DBSCAN算法,计算某个所属类别的e领域中所含个数,并以该e领域类所含个数,即minPts个数最多者为新的质心,即密度最大者为新的质心。
3)在Reducer端,为加快程序访问速率,采用5个Reducer来重新计算类别质心。
4)在Mapper端,通过读取缓存文件来获取每次迭代所需的类别新质心。
以下将本次设计中Mapper和Reducer端各自的输入和输出介绍一下:
Mapper : <Object,Text>--><IntWritable, Text>
输入:key未使用, value为Web文本数据;
输出:key为类别ID,value为Web文本数据。
Mapper设计的目标:给每篇文本计算出其所属类别,即类别ID。
Reducer: <IntWritable, Text>--><NullWritable, Text>
输入:key为文本类别ID, value为Web文本数据;
输出:key为Null, value为Web文本数据,即新的质心。
Reducer设计的目标:给每类数据确定新的质心。
测试结果与性能分析
由于本次测试目的,在于判别基于MapReduce的文本聚类算法可行性,因此数据规模并未设置很大。测试数据集为随机从网络上抓取的457篇Web标题,并迭代50次来展开测试,迭代的目的在于使每个类别的质心收敛。
表-1 改进的Kmeans和DBSCAN文本聚类算法测试结果

从表-1测试结果可知:在数据规模较小时,单线程处理的速率明显要优于MapReduce。主要原因在于,基于MapReduce框架,其每次迭代需要重新加载词典,同时读/写缓存文件,以获取质心或者修改质心,因此在数据规模较小时,处理数据的时间甚至不及上述文件的I/O时间,因此其优势并未发挥出来。本文作者曾尝试采用Java反射机制,加载数据对象以期解决上述问题,但收效甚微。
但是,采用MapReduce框架,在计算新的质心时,采用多个Reduer,明显能够改善数据规约的速率,较单线程处理来说,不仅能节省存储空间,同时处理简单、便捷。考虑到后期文本数据规模日益增大的趋势,引入分布式处理框架,对海量文本数据展开处理,已趋于一种潮流趋势,因此本文提出的算法有一定的实践意义。
程序源代码:
public class ElementDict {
private String term;
private int freq;
public ElementDict(String term, int freq) {
this.term = term;
this.freq = freq;
}
public void setFreq (int freq) {
this.freq = freq;
}
public String getTerm() {
return term;
}
public int getFreq() {
return freq;
}
public boolean equals(ElementDict e) {
boolean ret = false;
if (term.equals(e.getTerm()) && freq == e.getFreq())
{
ret = true;
}
return ret;
}
}
Class ElementDict
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.List;
import java.util.ArrayList;
import java.util.Map;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.wltea.analyzer.lucene.IKAnalyzer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger; public class TextCosine {
private Map<String, String> map= null;
private double common;
private double special;
private static final String PATH = "hdfs://10.1.130.10:9000";
private static Logger logger = LogManager.getLogger(TextCosine.class); public TextCosine() {
map = new HashMap<String, String>();
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(PATH), conf);
Path path = new Path("/user/hadoop/doc/synonyms.dict");
FSDataInputStream is = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String s = null;
while ((s = br.readLine()) != null) {
String []synonymsEnum = s.split("→");
map.put(synonymsEnum[0], synonymsEnum[1]);
}
br.close();
} catch (IOException e) {
logger.error("TextCosine IOException!");
}
} public TextCosine(double common, double special) {
map = new HashMap<String, String>();
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(PATH), conf);
Path path = new Path("/user/hadoop/doc/synonyms.dict");
FSDataInputStream is = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String s = null;
while ((s = br.readLine()) != null) {
String []synonymsEnum = s.split("→");
map.put(synonymsEnum[0], synonymsEnum[1]);
}
br.close();
} catch (IOException e) {
logger.error("TextCosine IOException!");
} this.common = common;
this.special = special;
} public void setCommon(double common) {
this.common = common;
} public void setSpecial(double special) {
this.special = special;
} // get the word with IK Analyzer
public List<ElementDict> tokenizer(String str) {
List<ElementDict> list = new ArrayList<ElementDict>();
IKAnalyzer analyzer = new IKAnalyzer(true);
try {
TokenStream stream = analyzer.tokenStream("", str);
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
stream.reset();
int index = -1;
while (stream.incrementToken()) {
if ((index = isContain(cta.toString(), list)) >= 0) {
list.get(index).setFreq(list.get(index).getFreq() + 1);
}
else {
list.add(new ElementDict(cta.toString(), 1));
}
}
analyzer.close();
} catch (IOException e) {
e.printStackTrace();
}
return list;
} // assert one term is in the List
public int isContain(String str, List<ElementDict> list) {
for (ElementDict ed : list) {
if (ed.getTerm().equals(str)) {
return list.indexOf(ed);
} else if (map.get(ed.getTerm())!= null && map.get(ed.getTerm()).equals(str)) {
return list.indexOf(ed);
}
}
return -1;
} // merge the two List to align the vector
public List<String> mergeTerms(List<ElementDict> list1, List<ElementDict> list2) {
List<String> list = new ArrayList<String>();
for (ElementDict ed : list1) {
if (!list.contains(ed.getTerm())) {
list.add(ed.getTerm());
} else if (!list.contains(map.get(ed.getTerm()))) {
list.add(ed.getTerm());
}
} for (ElementDict ed : list2) {
if (!list.contains(ed.getTerm())) {
list.add(ed.getTerm());
} else if (!list.contains(map.get(ed.getTerm()))) {
list.add(ed.getTerm());
}
}
return list;
} // get the max cosine
public double analysisText(List<ElementDict> list1, List<ElementDict> list2) {
int len1 = list1.size();
int len2 = list2.size();
double ret = 0;
if (len2 >= len1 * 1.5) {
List<ElementDict> newList = new ArrayList<ElementDict>();
for (int i = 0; i + len1 <= len2; i++) {
for (int j = 0; j < len1; j++)
newList.add(list2.get(i+j)); newList = adjustList(newList, list2, len2, len1, i);
double tmp = analysis(list1, newList);
if (tmp > ret)
ret = tmp;
}
} else if (len1 >= len2 * 1.5) {
List<ElementDict> newList = new ArrayList<ElementDict>();
for (int i = 0; i + len2 <= len1; i++) {
for (int j = 0; j < len2; j++)
newList.add(list1.get(i+j)); newList = adjustList(newList, list1, len1, len2, i);
double tmp = analysis(list1, newList);
if (tmp > ret)
ret = tmp;
}
} else {
ret = analysis(list1, list2);
}
return ret;
} // adjust the new List with the length about the original List
public List<ElementDict> adjustList(List<ElementDict> newList, List<ElementDict> list, int lenBig, int lenSmall, int index) {
int gap = lenBig -lenSmall;
int size = (gap/2 > 2) ? 2: gap/2;
if (index < gap/2) {
for (int i = 0; i < size; i++) {
newList.add(list.get(lenSmall+index+i));
}
} else {
for (int i = 0; i > size; i++) {
newList.add(list.get(lenBig-index-i));
}
}
return newList;
} // analysis the cosine for two vectors
public double analysis(List<ElementDict> list1, List<ElementDict> list2) {
List<String> list = mergeTerms(list1, list2);
List<Integer> weightList1 = assignWeight(list, list1);
List<Integer> weightList2 = assignWeight(list, list2);
return countCosSimilarity(weightList1, weightList2);
} // according the frequency to assign the weight
public List<Integer> assignWeight(List<String> list, List<ElementDict> list1) {
List<Integer> vecList = new ArrayList<Integer>(list.size());
boolean isEqual = false;
for (String str : list) {
for (ElementDict ed : list1) {
if (ed.getTerm().equals(str)) {
isEqual = true;
vecList.add(new Integer(ed.getFreq()));
} else if (map.get(ed.getTerm())!= null && map.get(ed.getTerm()).equals(str)) {
isEqual = true;
vecList.add(new Integer(ed.getFreq()));
}
} if (!isEqual) {
vecList.add(new Integer(0));
}
isEqual = false;
}
return vecList;
} // count the cosine about the two vectors
public double countCosSimilarity(List<Integer> list1, List<Integer> list2) {
double countScores = 0;
int element = 0;
int denominator1 = 0;
int denominator2 = 0;
int index = -1;
for (Integer it : list1) {
index ++;
int left = it.intValue();
int right = list2.get(index).intValue();
element += left * right;
denominator1 += left * left;
denominator2 += right * right;
}
try {
countScores = (double)element / Math.sqrt(denominator1 * denominator2);
} catch (ArithmeticException e) {
e.printStackTrace();
}
return countScores;
} public boolean isSimilarity(double param, double score) {
boolean ret = false;
if (score >= param)
ret = true;
return ret;
} public boolean assertSimilarity(List<ElementDict> list1, List<ElementDict> list2)
{
int len1 = list1.size();
int len2 = list2.size();
if (len2 >= len1 * 1.5) {
List<ElementDict> newList = new ArrayList<ElementDict>();
for (int i = 0; i + len1 <= len2; i++) {
for (int j = 0; j < len1; j++)
newList.add(list2.get(i+j)); newList = adjustList(newList, list2, len2, len1, i);
if (isSimilarity(special, analysis(list1, newList)))
return true;
}
} else if (len1 >= len2 * 1.5) {
List<ElementDict> newList = new ArrayList<ElementDict>();
for (int i = 0; i + len2 <= len1; i++) {
for (int j = 0; j < len2; j++)
newList.add(list1.get(i+j)); newList = adjustList(newList, list1, len1, len2, i);
if (isSimilarity(special, analysis(list1, newList)))
return true;
}
} else {
if (isSimilarity(common, analysis(list1, list2)))
return true;
}
return false;
}
}
Class TextCosine
import java.util.Collections;
import java.util.List; import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger; import com.gta.cosine.TextCosine;
import com.gta.cosine.ElementDict; public class DensityCenter {
private Logger logger = LogManager.getLogger(DensityCenter.class);
private double eps;
private TextCosine cosine; public DensityCenter(double eps, TextCosine cosine) {
this.eps = eps;
this.cosine = cosine;
} public double cosineDistance(String src, String dst)
{
List<ElementDict> vec1 = cosine.tokenizer(src);
List<ElementDict> vec2 = cosine.tokenizer(dst);
return cosine.analysisText(vec1, vec2);
} public int getNeighbors(String src, List<String> dst) {
int ret = 0;
double score = 0;
for (String s : dst) {
score = cosineDistance(src, s);
if (score >= eps)
ret++;
}
return ret;
} public String getDensityCenter(List<String> text) {
int max = 0;
int i = 0;
int index = 0;
for (String s : text) {
int ret = getNeighbors(s, text);
if (ret > max) {
index = i;
max = ret;
}
i++;
}
return text.get(index);
} public boolean compareCenters(List<String> oldCenters, List<String> newCenters)
{
boolean ret = false;
Collections.sort(oldCenters);
Collections.sort(newCenters);
int oldSize = oldCenters.size();
int newSize = newCenters.size();
logger.info("oldSize : " + oldSize);
logger.info("newSize : " + newSize);
int size = oldSize > newSize ? newSize : oldSize;
int index = 0;
int count = 0;
for (String s : oldCenters) {
if (s.equals(newCenters.get(index)))
count++; index++;
if (index >= size) // Avoid the size of two List is not the same
break;
}
logger.info("count : " + count);
if (count == index)
ret = true; return ret;
}
}
Class DensityCenter
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import com.gta.cosine.TextCosine;
import com.gta.cosine.ElementDict;
import com.gta.util.DensityCenter; public class KMeansProcess { public static class TextMapper extends Mapper<Object, Text, IntWritable, Text> {
private static Logger logger = LogManager.getLogger(TextMapper.class);
public static List<String> centersList = new ArrayList<String>();
public static TextCosine cosine = new TextCosine(); public void setup(Context context)
{
int iteration = context.getConfiguration().getInt("ITERATION", 100);
if (iteration == 0) {
int task = context.getConfiguration().getInt("TASK", 0);
try {
URI[] caches = context.getCacheFiles();
if (caches == null || caches.length <= 0) {
System.exit(1);
}
for (int i = 0; i < task; i++) {
FileSystem fs = FileSystem.get(caches[i], context.getConfiguration());
FSDataInputStream is = fs.open(new Path(caches[i].toString()));
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String s = null;
while ((s = br.readLine()) != null) {
centersList.add(s);
}
br.close();
}
} catch (IOException e) {
logger.error(e.getMessage());
}
}
} public void map(Object key, Text value, Context context)
{
try {
String str = value.toString();
double score = 0;
double countTmp = 0;
int clusterID = 0;
int index = 0;
List<ElementDict> vec1 = cosine.tokenizer(str);
for (String s : centersList) {
List<ElementDict> vec2 = cosine.tokenizer(s);
countTmp = cosine.analysisText(vec1, vec2);
if (countTmp > score) {
clusterID = index;
score = countTmp;
}
index++;
}
context.write(new IntWritable(clusterID), new Text(str));
} catch (IOException e) {
logger.error(e.getMessage());
} catch (InterruptedException e) {
logger.error(e.getMessage());
}
}
} public static class TextReducer extends Reducer<IntWritable, Text, NullWritable, Text> {
private static Logger logger = LogManager.getLogger(TextReducer.class);
public static DensityCenter center = new DensityCenter(0.75, KMeansProcess.TextMapper.cosine); public void reduce(IntWritable key, Iterable<Text> values, Context context) {
try {
List<String> list = new ArrayList<String>();
for (Text val : values) {
list.add(val.toString());
}
context.write(NullWritable.get(), new Text(center.getDensityCenter(list)));
} catch (IOException e) {
logger.error(e.getMessage());
} catch (InterruptedException e) {
logger.error(e.getMessage());
}
}
}
}
Class KMeansProcess
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.List;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import com.gta.cosine.TextCosine;
import com.gta.cosine.ElementDict; public class KMeans { public static class KMeansMapper extends Mapper<Object, Text, IntWritable, Text> {
private List<String> centersList = KMeansProcess.TextMapper.centersList;
private static Logger logger = LogManager.getLogger(KMeans.KMeansMapper.class);
private TextCosine cosine = KMeansProcess.TextMapper.cosine; public void setup(Context context)
{
int task = context.getConfiguration().getInt("TASK", 0);
try {
URI[] caches = context.getCacheFiles();
if (caches == null || caches.length <= 0) {
System.exit(1);
}
for (int i = 0; i < task; i++) {
FileSystem fs = FileSystem.get(caches[i], context.getConfiguration());
FSDataInputStream is = fs.open(new Path(caches[i].toString()));
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String s = null;
while ((s = br.readLine()) != null)
centersList.add(s);
br.close();
}
} catch (IOException e) {
logger.error(e.getMessage());
}
} public void map(Object key, Text value, Context context) {
try {
String str = value.toString();
double score = 0;
double countTmp = 0;
int clusterID = 0;
int index = 0;
List<ElementDict> vec1 = cosine.tokenizer(str);
for (String s : centersList) {
List<ElementDict> vec2 = cosine.tokenizer(s);
countTmp = cosine.analysisText(vec1, vec2);
if (countTmp > score) {
clusterID = index;
score = countTmp;
}
index++;
}
context.write(new IntWritable(clusterID), new Text(str));
} catch (IOException e) {
logger.error(e.getMessage());
} catch (InterruptedException e) {
logger.error(e.getMessage());
}
} public void cleanup(Context context)
{
centersList.clear();
}
} public static class KMeansReducer extends Reducer<IntWritable, Text, IntWritable, Text> {
private static Logger logger = LogManager.getLogger(KMeans.KMeansReducer.class); public void ruduce(IntWritable key, Iterable<Text> values, Context context) {
try {
for (Text val : values) {
context.write(key, val);
}
} catch (IOException e) {
logger.error(e.getMessage());
} catch (InterruptedException e) {
logger.error(e.getMessage());
}
}
} }
Class KMeans
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import java.util.ArrayList;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.gta.cluster.KMeans.KMeansMapper;
import com.gta.cluster.KMeans.KMeansReducer;
import com.gta.cluster.KMeansProcess.TextMapper;
import com.gta.cluster.KMeansProcess.TextReducer;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger; public class Cluster {
public static final int MAX = 50;
public static final String INPUT_PATH = "hdfs://10.1.130.10:9000/user/hadoop/input/";
public static final String OUTPUT_PATH = "hdfs://10.1.130.10:9000/user/hadoop/output/";
public static final String TMP_PATH = "hdfs://10.1.130.10:9000/user/hadoop/tmp/";
public static final int TASK = 5;
public static Logger logger = LogManager.getLogger(Cluster.class);
private Configuration conf;
private int iteration = 0; public Cluster()
{
this.conf = new Configuration();
conf.setInt("TASK", TASK);
} public void run() throws IOException, InterruptedException, ClassNotFoundException
{
while (iteration < MAX) {
logger.info("次数 : " + (iteration+1));
conf.setInt("ITERATION", iteration);
Job job = Job.getInstance(conf, "KMeans Process");
if (iteration == 0) {
String cacheFile = TMP_PATH + iteration + "/part-r-0000";
for (int i = 0; i < TASK; i++)
job.addCacheFile(URI.create(cacheFile+i));
}
job.setJarByClass(KMeansProcess.class);
job.setMapperClass(TextMapper.class);
job.setNumReduceTasks(TASK);
job.setReducerClass(TextReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
iteration++;
String outFile = TMP_PATH + iteration;
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(outFile));
job.waitForCompletion(true);
conf.unset("ITERATION");
List<String> tmpList = getCenterList(outFile);
if (KMeansProcess.TextReducer.center.compareCenters(KMeansProcess.TextMapper.centersList, tmpList))
break;
else {
KMeansProcess.TextMapper.centersList.clear();
for (String s : tmpList) {
KMeansProcess.TextMapper.centersList.add(s);
}
}
}
} public void lastRun() throws IOException, InterruptedException, ClassNotFoundException
{
String cacheFile = TMP_PATH + iteration + "/part-r-0000";
Job job = Job.getInstance(conf, "KMeans");
for (int i = 0; i < TASK; i++)
job.addCacheFile(URI.create(cacheFile+i));
job.setJarByClass(KMeans.class);
job.setMapperClass(KMeansMapper.class);
job.setReducerClass(KMeansReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
job.waitForCompletion(true);
} public List<String> getCenterList(String outFile)
{
List<String> centerList = new ArrayList<String>();
String fileName = outFile + "/part-r-0000";
try {
for (int i = 0; i < TASK; i++) {
FileSystem fs = FileSystem.get(URI.create((fileName+i)), conf);
FSDataInputStream is = fs.open(new Path((fileName+i).toString()));
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String s = null;
while ((s = br.readLine()) != null)
centerList.add(s);
br.close();
}
} catch (IOException e) {
logger.info(e.getMessage());
} return centerList;
} public static void main(String[] args) {
Cluster cluster = new Cluster();
try {
long start = System.currentTimeMillis();
cluster.run();
cluster.lastRun();
long end = System.currentTimeMillis();
Cluster.logger.info(end-start);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Class Cluster
鉴于在分布式环境下,多次迭代需要多次读取缓存文件,因此本文引入静态变量,以减少对TextCosine等初始化,以达到提升文本处理速率的目的。本文作者一直试图将对象实体传入Job中,但是经过多次实践,均以失败告终,若是有更好的解决方案,请联系我。
作者:志青云集
出处:http://www.cnblogs.com/lyssym
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【志青云集】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
文本挖掘之文本聚类(MapReduce)的更多相关文章
- 文本挖掘之文本聚类(OPTICS)
刘 勇 Email:lyssym@sina.com 简介 鉴于DBSCAN算法对输入参数,邻域半径E和阈值M比较敏感,在参数调优时比较麻烦,因此本文对另一种基于密度的聚类算法OPTICS(Order ...
- 文本挖掘之文本聚类(DBSCAN)
刘 勇 Email:lyssym@sina.com 简介 鉴于基于划分的文本聚类方法只能识别球形的聚类,因此本文对基于密度的文本聚类算法展开研究.DBSCAN(Density-Based Spat ...
- 灵玖软件NLPIRParser智能文本聚类
随着互联网的迅猛发展,信息的爆炸式增加,信息超载问题变的越来越严重,信息的更新率也越来越高,用户在信息海洋里查找信息就像大海捞针一样.搜索引擎服务应运而生,在一定程度上满足了用户查找信息的需要.然而互 ...
- 10.HanLP实现k均值--文本聚类
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 10. 文本聚类 正所谓物以类聚,人以群分.人们在获取数据时需要整理,将相似的数据 ...
- K-means算法及文本聚类实践
K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,聚类的效果也还不错,这里简单介绍一下k-means算法,下图是一个手写体数据集聚类的结果. 基本思想 k-means算法需要事先指定 ...
- R语言做文本挖掘 Part4文本分类
Part4文本分类 Part3文本聚类提到过.与聚类分类的简单差异. 那么,我们需要理清训练集的分类,有明白分类的文本:測试集,能够就用训练集来替代.预測集,就是未分类的文本.是分类方法最后的应用实现 ...
- [python] 使用Jieba工具中文分词及文本聚类概念
声明:由于担心CSDN博客丢失,在博客园简单对其进行备份,以后两个地方都会写文章的~感谢CSDN和博客园提供的平台. 前面讲述了很多关于Python爬取本体Ontology.消息盒Inf ...
- pyhanlp 文本聚类详细介绍
文本聚类 文本聚类简单点的来说就是将文本视作一个样本,在其上面进行聚类操作.但是与我们机器学习中常用的聚类操作不同之处在于. 我们的聚类对象不是直接的文本本身,而是文本提取出来的特征.因此如何提取特征 ...
- [转]python进行中文文本聚类(切词以及Kmeans聚类)
简介 查看百度搜索中文文本聚类我失望的发现,网上竟然没有一个完整的关于Python实现的中文文本聚类(乃至搜索关键词python 中文文本聚类也是如此),网上大部分是关于文本聚类的Kmeans聚类的原 ...
随机推荐
- Spring-Bean配置-使用外部属性文件(转)
Spring-Bean配置-使用外部属性文件 所以可以通过@value注解获取配置文件的key-value,生成一个配置文件bean.用以在代码中直接使用bean的方式. •在配置文件里配置Bean时 ...
- spring mvc 下 applicationContext 和webApplicationContext
spring中的ApplicationContexts可以被限制在不同的作用域.在web框架中,每个DispatcherServlet有它自己的WebApplicationContext,它包含了Di ...
- Openfire 服务器更换ip后的恢复方法
如果你的服务器名称和mysql的地址都是使用的静态ip地址配置的,更改ip后,openfire就会开启失败,这种情况下请看下面的解决方法. 比如你的ip地址由 192.168.0.111 改为192. ...
- VirtualBox 安装虚拟机
- 命令行编译工具NMAKE
简介 大家已经习惯于微软提供的功能强大的IDE,已经很少考虑手动编连项目了,所谓技多不压身,有空的时候还是随我一块了解一下命令行编译. C/C++/VC++程序员或有Unix/Linux编程经验应该很 ...
- .NET:CLR via C# Compute-Bound Asynchronous Operations
线程槽 使用线程池了以后就不要使用线程槽了,当线程池执行完调度任务后,线程槽的数据还在. 测试代码 using System; using System.Collections.Generic; us ...
- 【视频分享】Liger UI实战集智建筑project管理系统配商业代码(打印报表、角色式权限管理)
QQ 2059055336 课程讲师:集思博智 课程分类:.net 适合人群:中级 课时数量:23课时 用到技术:Liger UI框架.AJAX.JSON数据格式的序列化与反序列化.角色的交叉权限管理 ...
- 如何读取抓取的wifi包内容
有密码的WIFI,WIFI的密码会生成一个临时会话密钥,这个临时会话密钥可以用来加密会话内容,也就是说.比如你在浏览网页,用有密码的WIFI,连接上以后,浏览的网页流量是加密了的,所以更安全.无密码的 ...
- OTL翻译(7) -- otl_exception类
otl_exception 这个类是OTL用来抛出异常的类.如果数据库API返回一个非0的错误值,则OTL会将会抛出一个otl_exception的异常.一个otl_exception异常有可能是一个 ...
- CSS文字换行详细解说
本文列举了兼容 IE 和 FF 地换行 CSS 推荐样式,详细介绍了word-wrap同word-break地区别.兼容 IE 和 FF 地换行 CSS 推荐样式: 最好地方式是 word-wrap: ...