Solr的入门知识
一.Solr的简介
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。都是Web服务器,Servlet容器,报文 ,JSON 格式字符串, XML格式字符串。Solr是一个可以独立运行的搜索服务器,使用solr进行全文检索服务的话,只需要通过http请求访问该服务器即可。
使用Solr 进行创建索引和搜索索引的实现方法很简单,如下:
- 创建索引:客户端(可以是浏览器可以是Java程序)用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr服务器根据xml文档添加、删除、更新索引 。
- 搜索索引:客户端(可以是浏览器可以是Java程序)用 GET方法向 Solr 服务器发送请求,然后对 Solr服务器返回Xml、json等格式的查询结果进行解析。Solr不提供构建页面UI的功能。Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
二.Solr和Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
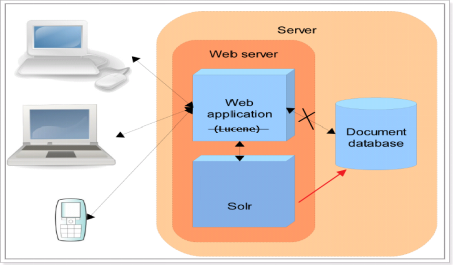
三.Solr的单机与集群概念
1.Solr的单机版
概念:HttpSolrServer
2.Solr的集群版
概念:SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
结构:SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
- 整个集群的配置信息可以集中配置
- 对于搜索自动负载均衡、出现故障时可以自动切换
- 集成了ZooKeeper,负责集群的协调和配置
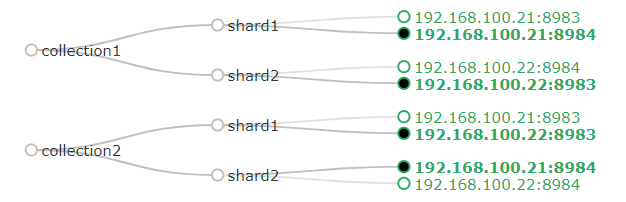
- HA:High Availability
- Node:一个服务器、或虚拟服务器节点,每个node对应一个port向外提供服务。对应于一个JVM。
- Collection:一个SolrCloud实例,负责对一批数据建立一个索引,并提供基于这个索引的搜索服务
- Shard:一个SolrCloud中的索引可以被拆分存放到多个shard中
- Replica:一个shard中的数据,可以有多个副本,就是Replica,其中有一个被推选出来的leader
- Core:负责处理一个Replica,跟一个node对应
- Cluster:由ZooKeeper管理的多个Node的集合,对solr的请求可以发送给一个cluster
- 如果文档被送到一个replica中,那么这个replica会把这些文档发送给这个shard的leader
- 当一个leader接收到文档的时候,SolrCloud会决定这些文档应该分配到哪个shard,然后把它们发生给这个shard的leader、建立索引、并把索引发送给这个shard中所有的replica
package com.xyg.solrj; import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test; /**
* <p>Title:SolrjDemo</p>
* @Description:solrj的入门程序
* @Param:
* @Return:
* @Author:Administrator
* @Date:2017年11月3日上午12:32:42
*/
public class SolrjDemo {
//添加 修改
@Test
public void testCreateAndUpdateIndex() throws Exception {
// 1. 创建HttpSolrServer对象
// 设置solr服务接口,浏览器客户端地址http://127.0.0.1:8080/solr/#/
String baseURL = "http://127.0.0.1:8080/solr";
//String baseURL = "http://localhost:8080/solr/collection2";
SolrServer solrServer = new HttpSolrServer(baseURL);
// 2. 创建SolrInputDocument对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "");
document.addField("name", "Hello world!");
// 3. 把SolrInputDocument对象添加到索引库中
solrServer.add(document); //httpSolrServer.add(document,1000);
// 4. 提交
solrServer.commit();
}
//删除
@Test
public void testDeleteIndex() throws Exception {
String baseURL = "http://127.0.0.1:8080/solr";
SolrServer solrServer = new HttpSolrServer(baseURL);
// 根据id删除索引数据
//solrServer.deleteById("100");
// 根据条件删除(如果是*:*就表示全部删除,慎用)
//solrServer.deleteByQuery("name:Hello");
solrServer.deleteByQuery("*:*"); //删除所有
solrServer.commit(); // 提交
}
//查询
@Test
public void testSearchIndex1() throws Exception {
String baseURL = "http://127.0.0.1:8080/solr";
SolrServer solrServer = new HttpSolrServer(baseURL);
// 创建搜索对象
SolrQuery query = new SolrQuery();
// 设置搜索条件
query.setQuery("*:*");
// 发起搜索请求
QueryResponse response = solrServer.query(query);
// 处理搜索结果
SolrDocumentList docs = response.getResults();
System.out.println("搜索到的结果总数:" + docs.getNumFound());
// 遍历搜索结果
for (SolrDocument doc : docs) {
System.out.println("----------------------------------------------------");
System.out.println("id:" + doc.get("id"));
System.out.println("name:" + doc.get("name"));
}
}
//复杂查询索引
@Test
public void queryIndex2() throws Exception {
//创建连接
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
//创建一个query对象
SolrQuery solrQuery = new SolrQuery();
//设置关键词查询条件
solrQuery.setQuery("钻石"); //solrQuery.set("q","钻石");
//过滤条件
solrQuery.setFilterQueries("product_catalog_name:幽默杂货");
//排序条件
solrQuery.setSort("product_price", ORDER.asc);
//分页处理
solrQuery.setStart();
solrQuery.setRows();
//结果中域的列表 solrQuery.setFields("id","product_name","product_price","product_catalog_name","product_picture");
//设置默认搜索域
solrQuery.set("df", "product_keywords");
//高亮显示
solrQuery.setHighlight(true);
//高亮显示的域
solrQuery.addHighlightField("product_name");
//高亮显示的前缀
solrQuery.setHighlightSimplePre("<font color='red'>");
//高亮显示的后缀
solrQuery.setHighlightSimplePost("</font>");
//执行查询
QueryResponse queryResponse = solrServer.query(solrQuery);
//取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
//共查询到商品数量
System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());
//遍历查询的结果
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
//取高亮显示
String productName = "";
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
List<String> list = highlighting.get(solrDocument.get("id")).get("product_name");
//判断是否有高亮内容
if (null != list) {
productName = list.get();
} else {
productName = (String) solrDocument.get("product_name");
}
System.out.println(productName);
System.out.println(solrDocument.get("product_price"));
System.out.println(solrDocument.get("product_catalog_name"));
System.out.println(solrDocument.get("product_picture"));
}
}
}
Solr的入门知识的更多相关文章
- Solr搜索引擎入门知识汇总
1.技术选型,为什么用solr而不用lucene,或者其他检索工具 lucene:需要开发者自己维护索引文件,在多机环境中备份同步索引文件很是麻烦 Lucene本质上是搜索库,不是独立的应用程序.而S ...
- Solr安装入门、查询详解
Solr安装入门:http://www.importnew.com/12607.html 查询详解:http://www.360doc.com/content/14/0306/18/203871_35 ...
- [置顶] Mysql存储过程入门知识
Mysql存储过程入门知识 #1,查看数据库所有的存储过程名 #--这个语句被用来移除一个存储程序.不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程 #SELECT NAME FROM ...
- 移动H5开发入门知识,CSS的单位汇总与用法
说到css的单位,大家应该首先想到的是px,也就是像素,我们在网页布局中一般都是用px,但是近年来自适应网页布局越来越多,em和百分比也经常用到了.然后随着手机的流行,web app和hybrid a ...
- H5移动端开发入门知识以及CSS的单位汇总与用法
说到css的单位,大家应该首先想到的是px,也就是像素,我们在网页布局中一般都是用px,但是近年来自适应网页布局越来越多,em和百分比也经常用到了.然后随着手机的流行,web app和hybrid a ...
- Java web 入门知识 及HTTP协议详解
Java web 入门知识 及HTTP协议详解 WEB入门 WEB,在英语中web即表示网页的意思,它用于表示Internet主机上供外界访问的资源. Internet上供外界访问的Web资 ...
- Java基础入门知识
Java编程入门知识 知识概要: (1)Java入门基本常识 (2)Java的特性跨平台性 (3)Java的编程环境的搭建 (4)Java的运行机制 (5)第一个Java小程序入门 (1)Java ...
- zabbix入门知识
zabbix入门知识 zabbix中文手册 https://www.zabbix.com/documentation/3.4/manual/ 1.zabbix介绍 Zabbix 是一个企业级的分布式开 ...
- React的入门知识与概念【1】
回顾在以往的项目开发中,从最初的使用的原生html+js+css+jquery开发,到后来随着项目功能的增加,也渐渐学习了Vue.js框架的开发,以及Vue.js的全家桶Axios,Vue-route ...
随机推荐
- bzoj千题计划152:bzoj3405: [Usaco2009 Open]Grazing2 移动牛棚
http://www.lydsy.com/JudgeOnline/problem.php?id=3405 n个牛棚,n-1段 因为要求距离尽量大,而且尽可能多的为d 所以: 第1个牛棚一定在位置1 最 ...
- 贪心问题:区间覆盖 NYOJ 喷水装置(二)
喷水装置(二) 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 有一块草坪,横向长w,纵向长为h,在它的橫向中心线上不同位置处装有n(n<=10000)个点状的喷水 ...
- Java并发编程原理与实战二十六:闭锁 CountDownLatch
关于闭锁 CountDownLatch 之前在网上看到过一篇举例非常形象的例子,但不记得是出自哪里了,所以这里就当自己再重新写一篇吧: 例子如下: 我们每天起早贪黑的上班,父母每天也要上班,有一天定了 ...
- bzoj1190 [HNOI2007]梦幻岛宝珠
传送门:https://www.lydsy.com/JudgeOnline/problem.php?id=1190 [题解] 首先,我们把所有物品都分解成$a\times 2^b$的形式,然后把物品按 ...
- 20155227 2016-2017-2 《Java程序设计》第四周学习总结
20155227 2016-2017-2 <Java程序设计>第四周学习总结 教材学习内容总结 继承 继承 继承是Java程序设计语言面向对象的又一重要体现,允许子类继承父类,避免重复的行 ...
- Mysql 关闭自动commit
更多内容推荐微信公众号,欢迎关注: 1. 会话级关闭自动提交 mysql> set autocommit=off; Query OK, 0 rows affected (0.00 sec) my ...
- 南京邮电大学 CTF 逆向部分 Writeup
Hello,RE! 提示 IDA 中按 R . Google 到 IDA 中 R 快捷键是 Character ,转为字符串. 丢进 IDA(虽然我并不会使用 IDA 有个 strcmp 函数,比较 ...
- qt中int与string的相互转换
我经常搞错这个问题,一直以为整形int b可以直接使用函数toString呢! 但是在qtCreator中在整形后面不管怎么按点(可以自动提示)他就是不给我提示,我就纳闷了这样居然不行 百度了之后才知 ...
- Lucene7.1.0版本的索引创建与查询以及维护,包括新版本的一些新特性探索!
一 吐槽 lucene版本更新实在太快了,往往旧版本都还没学会,新的就出来,而且每个版本改动都特别大,尤其是4.7,6,6,7.1.......ε=(´ο`*)))唉,但不可否认,新版本确实要比旧版本 ...
- Chapter 4 深入理解Caffe MNIST DEMO中的LeNet网络模型
明代思想家王阳明提出了"知行合一",谓认识事物的道理与在现实中运用此道理,是密不可分的一回事.我以为这样的中国哲学话语,对于学习者来说,极具启发意义,要细细体会.中华文明源远流长, ...