大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeeper与hbase的部署与配置,常见hbase shell命令
选件版本选择:
选举机制:Zookeeper-3.4.12,部署3台,50、51、52
分布式列式数据库:HBase-1.4.9,主机50,从机51、52、53
安装配置Zookeeper集群
这里可以选择不安装Zookeeper,而使用HBase自带的Zookeeper,不过这里还是介绍一下Zookeeper的安装配置
上传Zookeeper

解压Zookeeper
tar -zxvf zookeeper-3.4.12.tar.gz -C /cloud/
配置zookeeper
cd /cloud/zookeeper-3.4.12/conf/
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
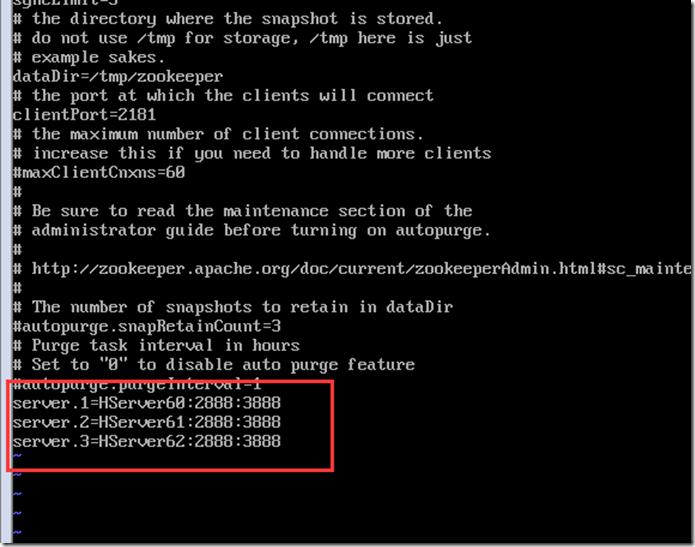
创建对应ID,在60上为1,61上为2,62为3
cd /cloud/zookeeper-3.4.12
mkdir tmp
vi tmp/myid
输入对应ID,保存,zookeeper配置完毕
安装配置HBase集群
上传解压hbase

tar -zxvf hbase-1.4.9-bin.tar.gz -C /cloud/
进入HBase配置文件目录
cd /cloud/hbase-1.4.9/conf/
配置hbase-env.sh
vi hbase-env.sh
设置jdk路径与hbase的配置路径
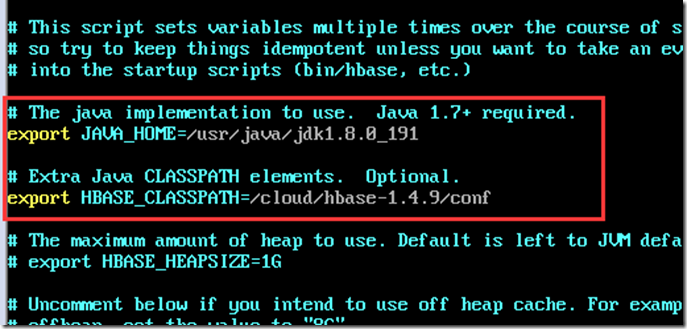
设置是否使用hbase自带的zookeeper

配置从机节点
vi regionservers
配置为从机的HServer51、HServer52、HServer53

配置hbase-site.xml
vi hbase-site.xml
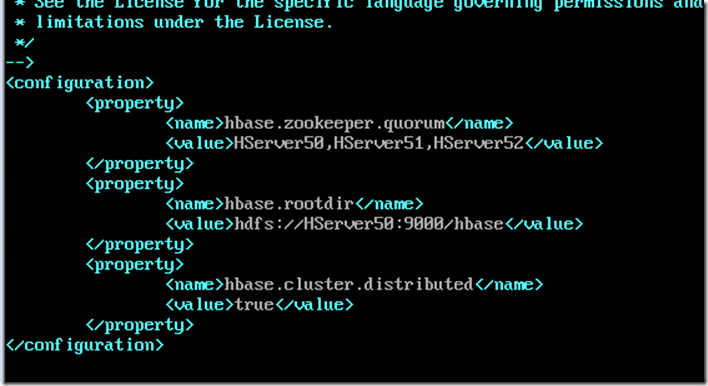
可以将配置好的hbase通过scp命令复制到其他从机上,整个hbase配置完毕,测试hbase是否成功
hbase的运行命令在hbase/bin目录下,可以将该路径加入/etc/profile中
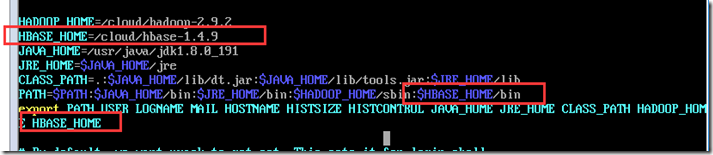
启动hbase
start-hbase.sh
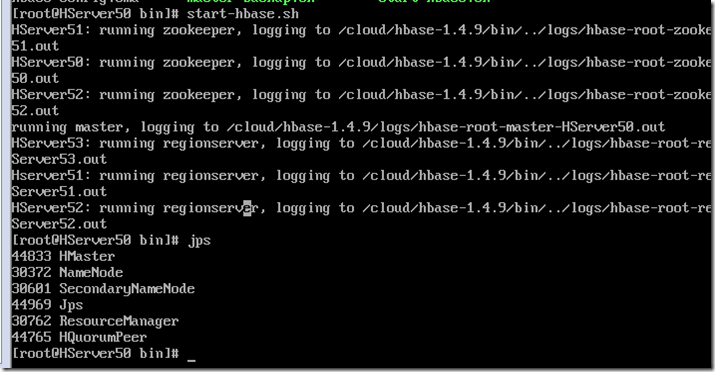
主机上jps可以看到HMaster
从机上可以看到HRegionServer
配置了zookeeper节点的可以看到HQuorumPeer
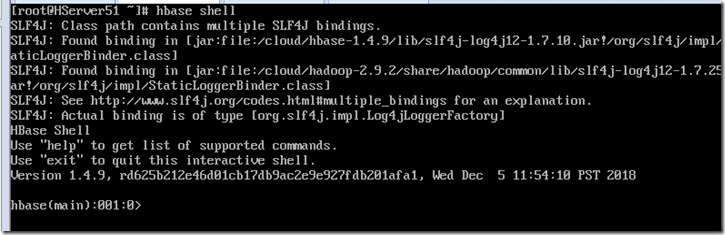
HBase Shell
从机上通过hbase shell初步尝试使用hbase
hbase shell
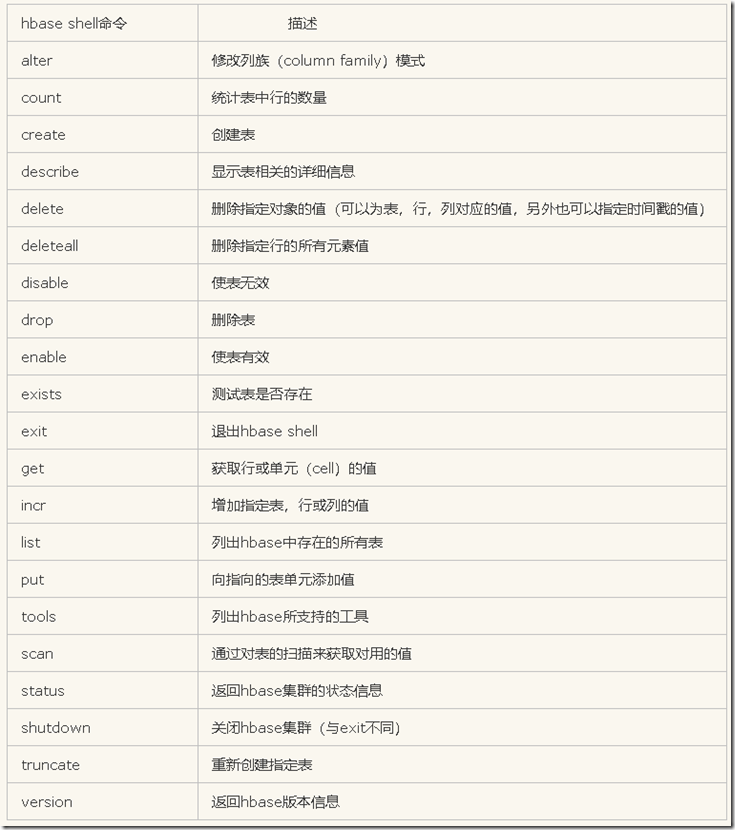
常用命令如下:
大数据中HBase集群搭建与配置的更多相关文章
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建. 对应4个IP为192.168.1.60.61.62.63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即 ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据-spark HA集群搭建
一.安装scala 我们安装的是scala-2.11.8 5台机器全部安装 下载需要的安装包,放到特定的目录下/opt/workspace/并进行解压 1.解压缩 [root@master1 ~]# ...
- 大数据-hadoop HA集群搭建
一.安装hadoop.HA及配置journalnode 实现namenode HA 实现resourcemanager HA namenode节点之间通过journalnode同步元数据 首先下载需要 ...
随机推荐
- 【转】【Flex】#010 操作XML文件(E4X)
该教程转载来自于:http://blog.chinaunix.net/uid-14767524-id-2785506.html [看到这边文章的位置,具体原作者未知] 经过一些排版的修改,其他内 ...
- 前端技术-HTML页面的加载
HTML页面的加载 HTML页面的加载实际上是基于http过程+浏览器对数据的解析渲染. http协议的请求过程是基于TCP协议的.http是要基于TCP连接基础上,简单的说,TCP单纯建立连接,不涉 ...
- [转]IE9.0或者360下js(JavaScript、jQuery)不能正确执行(加载),按F12后执行正常;Firefox下ajax的success返回数据data(json、string)无法获取
兼容问题1: 页面的分享等插件加载不全,并无法点击. 兼容问题2: IE下页面选择器(#id..class.etc.)绑定click事件无法访问到,后台springmvc方法,也无法获取ajax的su ...
- HDU4513:完美队形II(Manacher)
Description Input Output Sample Input Sample Output Solution 才发现我之前不会证$Manacher$复杂度……QAQ 题意是求最长向 ...
- 【CF662C】Binary Table
题目 好吧,我连板子都不会了 有一个非常显然的做法就是\(O(2^nm)\)做法就是枚举每一行的状态,之后我们贪心去看看每一列是否需要翻转就好啦 显然这个做法非常垃圾过不去 首先我们发现每一列都不超过 ...
- 【openjudge】【字符串+模拟】1777:文件结构“图”
[题目传送门:]戳 [描述:] 在计算机上看到文件系统的结构通常很有用.Microsoft Windows上面的"explorer"程序就是这样的一个例子.但是在有图形界面之前,没 ...
- 一个简单的统计问题(解决方案:Trie树)
题目如图 输入几个不重复的单词和几个前缀,分别统计出单词中包含前缀的个数. Trie树 这个题目用到了 Trie 树.它在百度百科中的定义如下:在计算机科学中,Trie,又称字典树.单词查找树 ...
- Mac app打包成dmg
1. 找到打包的app文件,在Xcode工程的Products目录下 2. 在桌面新建一个文件夹dmg,将app文件放进去. 3. 为了实现拖拽到Application的效果,需要在这个文件夹里放一个 ...
- Python自动化之clean方法前端调用clean方法的错误
obj.non_field_errors.0 源代码: NON_FIELD_ERRORS = '__all__' 如果在前端写 obj.errors.__all__.0直接就会报错 所以经过尝试得知, ...
- [图解tensorflow源码] MatMul 矩阵乘积运算 (前向计算,反向梯度计算)