五个步骤教你理清Redis与Memcached的区别
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
memcached和redis,作为近些年最常用的缓存服务器,相信大家对它们再熟悉不过了。前两年还在学校时,我曾经读过它们的主要源码,如今写篇笔记从个人角度简单对比一下它们的实现方式,权当做复习,有理解错误之处,欢迎指正。
文中使用的架构类的图片大多来自于网络,有部分图与最新实现有出入,文中已经指出。
一. 综述
读一个软件的源码,首先要弄懂软件是用作干什么的,那memcached和redis是干啥的?众所周知,数据一般会放在数据库中,但是查询数据会相对比较慢,特别是用户很多时,频繁的查询,需要耗费大量的时间。怎么办呢?数据放在哪里查询快?那肯定是内存中。memcached和redis就是将数据存储在内存中,按照key-value的方式查询,可以大幅度提高效率。所以一般它们都用做缓存服务器,缓存常用的数据,需要查询的时候,直接从它们那儿获取,减少查询数据库的次数,提高查询效率。
二. 服务方式
memcached和redis怎么提供服务呢?它们是独立的进程,需要的话,还可以让他们变成daemon进程,所以我们的用户进程要使用memcached和redis的服务的话,就需要进程间通信了。考虑到用户进程和memcached和redis不一定在同一台机器上,所以还需要支持网络间通信。因此,memcached和redis自己本身就是网络服务器,用户进程通过与他们通过网络来传输数据,显然最简单和最常用的就是使用tcp连接了。另外,memcached和redis都支持udp协议。而且当用户进程和memcached和redis在同一机器时,还可以使用unix域套接字通信。
三. 事件模型
下面开始讲他们具体是怎么实现的了。首先来看一下它们的事件模型。
自从epoll出来以后,几乎所有的网络服务器全都抛弃select和poll,换成了epoll。redis也一样,只不多它还提供对select和poll的支持,可以自己配置使用哪一个,但是一般都是用epoll。另外针对BSD,还支持使用kqueue。而memcached是基于libevent的,不过libevent底层也是使用epoll的,所以可以认为它们都是使用epoll。epoll的特性这里就不介绍了,网上介绍文章很多。
它们都使用epoll来做事件循环,不过redis是单线程的服务器(redis也是多线程的,只不过除了主线程以外,其他线程没有event loop,只是会进行一些后台存储工作),而memcached是多线程的。 redis的事件模型很简单,只有一个event loop,是简单的reactor实现。不过redis事件模型中有一个亮点,我们知道epoll是针对fd的,它返回的就绪事件也是只有fd,redis里面的fd就是服务器与客户端连接的socket的fd,但是处理的时候,需要根据这个fd找到具体的客户端的信息,怎么找呢?通常的处理方式就是用红黑树将fd与客户端信息保存起来,通过fd查找,效率是lgn。不过redis比较特殊,redis的客户端的数量上限可以设置,即可以知道同一时刻,redis所打开的fd的上限,而我们知道,进程的fd在同一时刻是不会重复的(fd只有关闭后才能复用),所以redis使用一个数组,将fd作为数组的下标,数组的元素就是客户端的信息,这样,直接通过fd就能定位客户端信息,查找效率是O(1),还省去了复杂的红黑树的实现(我曾经用c写一个网络服务器,就因为要保持fd和connect对应关系,不想自己写红黑树,然后用了STL里面的set,导致项目变成了c++的,最后项目使用g++编译,这事我不说谁知道?)。显然这种方式只能针对connection数量上限已确定,并且不是太大的网络服务器,像nginx这种http服务器就不适用,nginx就是自己写了红黑树。
而memcached是多线程的,使用master-worker的方式,主线程监听端口,建立连接,然后顺序分配给各个工作线程。每一个从线程都有一个event loop,它们服务不同的客户端。master线程和worker线程之间使用管道通信,每一个工作线程都会创建一个管道,然后保存写端和读端,并且将读端加入event loop,监听可读事件。同时,每个从线程都有一个就绪连接队列,主线程连接连接后,将连接的item放入这个队列,然后往该线程的管道的写端写入一个connect命令,这样event loop中加入的管道读端就会就绪,从线程读取命令,解析命令发现是有连接,然后就会去自己的就绪队列中获取连接,并进行处理。多线程的优势就是可以充分发挥多核的优势,不过编写程序麻烦一点,memcached里面就有各种锁和条件变量来进行线程同步。
四. 内存分配
memcached和redis的核心任务都是在内存中操作数据,内存管理自然是核心的内容。
首先看看他们的内存分配方式。memcached是有自己得内存池的,即预先分配一大块内存,然后接下来分配内存就从内存池中分配,这样可以减少内存分配的次数,提高效率,这也是大部分网络服务器的实现方式,只不过各个内存池的管理方式根据具体情况而不同。而redis没有自己得内存池,而是直接使用时分配,即什么时候需要什么时候分配,内存管理的事交给内核,自己只负责取和释放(redis既是单线程,又没有自己的内存池,是不是感觉实现的太简单了?那是因为它的重点都放在数据库模块了)。不过redis支持使用tcmalloc来替换glibc的malloc,前者是google的产品,比glibc的malloc快。
由于redis没有自己的内存池,所以内存申请和释放的管理就简单很多,直接malloc和free即可,十分方便。而memcached是支持内存池的,所以内存申请是从内存池中获取,而free也是还给内存池,所以需要很多额外的管理操作,实现起来麻烦很多,具体的会在后面memcached的slab机制讲解中分析。
五. 数据库实现
接下来看看他们的最核心内容,各自数据库的实现。
1. memcached数据库实现
memcached只支持key-value,即只能一个key对于一个value。它的数据在内存中也是这样以key-value对的方式存储,它使用slab机制。
首先看memcached是如何存储数据的,即存储key-value对。如下图,每一个key-value对都存储在一个item结构中,包含了相关的属性和key和value的值。
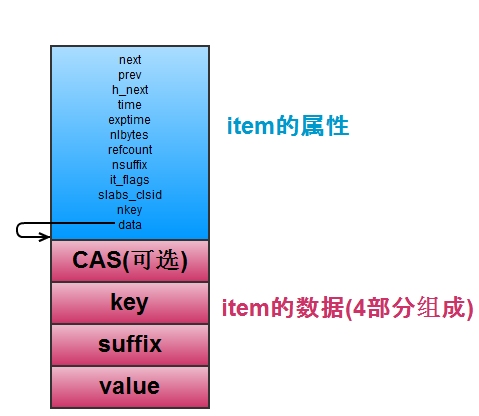
item是保存key-value对的,当item多的时候,怎么查找特定的item是个问题。所以memcached维护了一个hash表,它用于快速查找item。hash表适用开链法(与redis一样)解决键的冲突,每一个hash表的桶里面存储了一个链表,链表节点就是item的指针,如上图中的h_next就是指桶里面的链表的下一个节点。 hash表支持扩容(item的数量是桶的数量的1.5以上时扩容),有一个primary_hashtable,还有一个old_hashtable,其中正常适用primary_hashtable,但是扩容的时候,将old_hashtable = primary_hashtable,然后primary_hashtable设置为新申请的hash表(桶的数量乘以2),然后依次将old_hashtable 里面的数据往新的hash表里面移动,并用一个变量expand_bucket记录以及移动了多少个桶,移动完成后,再free原来的old_hashtable 即可(redis也是有两个hash表,也是移动,不过不是后台线程完成,而是每次移动一个桶)。扩容的操作,专门有一个后台扩容的线程来完成,需要扩容的时候,使用条件变量通知它,完成扩容后,它又考试阻塞等待扩容的条件变量。这样在扩容的时候,查找一个item可能会在primary_hashtable和old_hashtable的任意一个中,需要根据比较它的桶的位置和expand_bucket的大小来比较确定它在哪个表里。
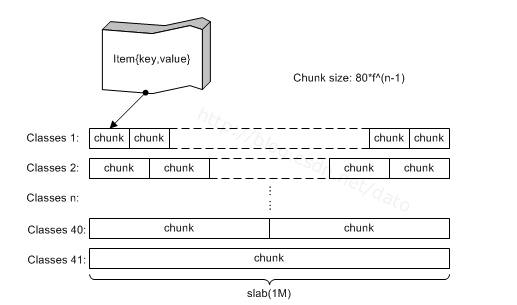
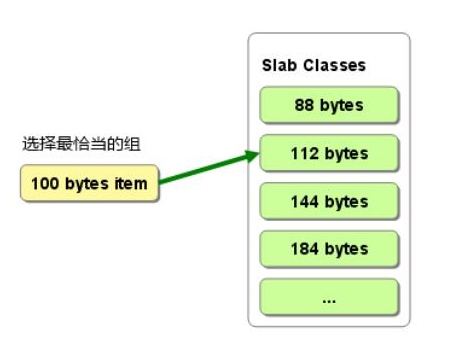
item是从哪里分配的呢?从slab中。如下图,memcached有很多slabclass,它们管理slab,每一个slab其实是trunk的集合,真正的item是在trunk中分配的,一个trunk分配一个item。一个slab中的trunk的大小一样,不同的slab,trunk的大小按比例递增,需要新申请一个item的时候,根据它的大小来选择trunk,规则是比它大的最小的那个trunk。这样,不同大小的item就分配在不同的slab中,归不同的slabclass管理。 这样的缺点是会有部分内存浪费,因为一个trunk可能比item大,如图2,分配100B的item的时候,选择112的trunk,但是会有12B的浪费,这部分内存资源没有使用。
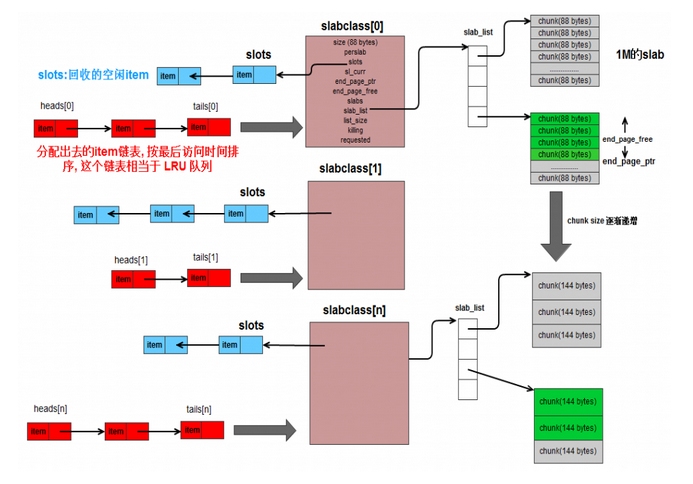
如上图,整个构造就是这样,slabclass管理slab,一个slabclass有一个slab_list,可以管理多个slab,同一个slabclass中的slab的trunk大小都一样。slabclass有一个指针slot,保存了未分配的item已经被free掉的item(不是真的free内存,只是不用了而已),有item不用的时候,就放入slot的头部,这样每次需要在当前slab中分配item的时候,直接取slot取即可,不用管item是未分配过的还是被释放掉的。
然后,每一个slabclass对应一个链表,有head数组和tail数组,它们分别保存了链表的头节点和尾节点。链表中的节点就是改slabclass所分配的item,新分配的放在头部,链表越往后的item,表示它已经很久没有被使用了。当slabclass的内存不足,需要删除一些过期item的时候,就可以从链表的尾部开始删除,没错,这个链表就是为了实现LRU。光靠它还不行,因为链表的查询是O(n)的,所以定位item的时候,使用hash表,这已经有了,所有分配的item已经在hash表中了,所以,hash用于查找item,然后链表有用存储item的最近使用顺序,这也是lru的标准实现方法。
每次需要新分配item的时候,找到slabclass对于的链表,从尾部往前找,看item是否已经过期,过期的话,直接就用这个过期的item当做新的item。没有过期的,则需要从slab中分配trunk,如果slab用完了,则需要往slabclass中添加slab了。
memcached支持设置过期时间,即expire time,但是内部并不定期检查数据是否过期,而是客户进程使用该数据的时候,memcached会检查expire time,如果过期,直接返回错误。这样的优点是,不需要额外的cpu来进行expire time的检查,缺点是有可能过期数据很久不被使用,则一直没有被释放,占用内存。
memcached是多线程的,而且只维护了一个数据库,所以可能有多个客户进程操作同一个数据,这就有可能产生问题。比如,A已经把数据更改了,然后B也更改了改数据,那么A的操作就被覆盖了,而可能A不知道,A任务数据现在的状态时他改完后的那个值,这样就可能产生问题。为了解决这个问题,memcached使用了CAS协议,简单说就是item保存一个64位的unsigned int值,标记数据的版本,每更新一次(数据值有修改),版本号增加,然后每次对数据进行更改操作,需要比对客户进程传来的版本号和服务器这边item的版本号是否一致,一致则可进行更改操作,否则提示脏数据。
以上就是memcached如何实现一个key-value的数据库的介绍。
2. redis数据库实现
首先redis数据库的功能强大一些,因为不像memcached只支持保存字符串,redis支持string, list, set,sorted set,hash table 5种数据结构。例如存储一个人的信息就可以使用hash table,用人的名字做key,然后name super, age 24, 通过key 和 name,就可以取到名字super,或者通过key和age,就可以取到年龄24。这样,当只需要取得age的时候,不需要把人的整个信息取回来,然后从里面找age,直接获取age即可,高效方便。
为了实现这些数据结构,redis定义了抽象的对象redis object,如下图。每一个对象有类型,一共5种:字符串,链表,集合,有序集合,哈希表。 同时,为了提高效率,redis为每种类型准备了多种实现方式,根据特定的场景来选择合适的实现方式,encoding就是表示对象的实现方式的。然后还有记录了对象的lru,即上次被访问的时间,同时在redis 服务器中会记录一个当前的时间(近似值,因为这个时间只是每隔一定时间,服务器进行自动维护的时候才更新),它们两个只差就可以计算出对象多久没有被访问了。 然后redis object中还有引用计数,这是为了共享对象,然后确定对象的删除时间用的。最后使用一个void*指针来指向对象的真正内容。正式由于使用了抽象redis object,使得数据库操作数据时方便很多,全部统一使用redis object对象即可,需要区分对象类型的时候,再根据type来判断。而且正式由于采用了这种面向对象的方法,让redis的代码看起来很像c++代码,其实全是用c写的。
//#define REDIS_STRING 0 // 字符串类型
//#define REDIS_LIST 1 // 链表类型
//#define REDIS_SET 2 // 集合类型(无序的),可以求差集,并集等
//#define REDIS_ZSET 3 // 有序的集合类型
//#define REDIS_HASH 4 // 哈希类型
//#define REDIS_ENCODING_RAW 0 /* Raw representation */ //raw 未加工
//#define REDIS_ENCODING_INT 1 /* Encoded as integer */
//#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
//#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
//#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
//#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
//#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
//#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
//#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds
string encoding */
typedef struct redisObject {
unsigned type:4; // 对象的类型,包括 /* Object types */
unsigned encoding:4; // 底部为了节省空间,一种type的数据,
// 可 以采用不同的存储方式
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount; // 引用计数
void *ptr;
} robj;
说到底redis还是一个key-value的数据库,不管它支持多少种数据结构,最终存储的还是以key-value的方式,只不过value可以是链表,set,sorted set,hash table等。和memcached一样,所有的key都是string,而set,sorted set,hash table等具体存储的时候也用到了string。 而c没有现成的string,所以redis的首要任务就是实现一个string,取名叫sds(simple dynamic string),如下的代码, 非常简单的一个结构体,len存储改string的内存总长度,free表示还有多少字节没有使用,而buf存储具体的数据,显然len-free就是目前字符串的长度。
struct sdshdr {
int len;
int free;
char buf[];
};
字符串解决了,所有的key都存成sds就行了,那么key和value怎么关联呢?key-value的格式在脚本语言中很好处理,直接使用字典即可,C没有字典,怎么办呢?自己写一个呗(redis十分热衷于造轮子)。看下面的代码,privdata存额外信息,用的很少,至少我们发现。 dictht是具体的哈希表,一个dict对应两张哈希表,这是为了扩容(包括rehashidx也是为了扩容)。dictType存储了哈希表的属性。redis还为dict实现了迭代器(所以说看起来像c++代码)。
哈希表的具体实现是和mc类似的做法,也是使用开链法来解决冲突,不过里面用到了一些小技巧。比如使用dictType存储函数指针,可以动态配置桶里面元素的操作方法。又比如dictht中保存的sizemask取size(桶的数量)-1,用它与key做&操作来代替取余运算,加快速度等等。总的来看,dict里面有两个哈希表,每个哈希表的桶里面存储dictEntry链表,dictEntry存储具体的key和value。
前面说过,一个dict对于两个dictht,是为了扩容(其实还有缩容)。正常的时候,dict只使用dictht[0],当dict[0]中已有entry的数量与桶的数量达到一定的比例后,就会触发扩容和缩容操作,我们统称为rehash,这时,为dictht[1]申请rehash后的大小的内存,然后把dictht[0]里的数据往dictht[1]里面移动,并用rehashidx记录当前已经移动万的桶的数量,当所有桶都移完后,rehash完成,这时将dictht[1]变成dictht[0], 将原来的dictht[0]变成dictht[1],并变为null即可。不同于memcached,这里不用开一个后台线程来做,而是就在event loop中完成,并且rehash不是一次性完成,而是分成多次,每次用户操作dict之前,redis移动一个桶的数据,直到rehash完成。这样就把移动分成多个小移动完成,把rehash的时间开销均分到用户每个操作上,这样避免了用户一个请求导致rehash的时候,需要等待很长时间,直到rehash完成才有返回的情况。不过在rehash期间,每个操作都变慢了点,而且用户还不知道redis在他的请求中间添加了移动数据的操作,感觉redis太贱了
五个步骤教你理清Redis与Memcached的区别的更多相关文章
- C#语法——泛型的多种应用 C#语法——await与async的正确打开方式 C#线程安全使用(五) C#语法——元组类型 好好耕耘 redis和memcached的区别
C#语法——泛型的多种应用 本篇文章主要介绍泛型的应用. 泛型是.NET Framework 2.0 版类库就已经提供的语法,主要用于提高代码的可重用性.类型安全性和效率. 泛型的定义 下面定义了 ...
- redis 和 memcached的区别
redis和memcached的区别 Redis 和 Memcache 都是基于内存的数据存储系统.Memcached是高性能分布式内存缓存服务:Redis是一个开源的key-value存储系统. ...
- 内存数据库:Redis与Memcached的区别
Redis与Memcached的区别 传统MySQL+ Memcached架构遇到的问题 实际MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都 ...
- Redis与Memcached的区别
传统MySQL+ Memcached架构遇到的问题 实际MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量 ...
- 也谈谈 Redis 和 Memcached 的区别
本文作者: 伯乐在线 - 朱小厮 . 说到redis就会联想到memcached,反之亦然.了解过两者的同学有那么个大致的印象: redis与memcached相比,比仅支持简单的key-value数 ...
- 【转载】Redis与Memcached的区别
传统MySQL+ Memcached架构遇到的问题 实际MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量 ...
- (转)Redis与Memcached的区别
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点: 1 Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储. 2 Redis支持 ...
- Redis 与 Memcached 的区别
[转]Redis 与 Memcached 的区别 传统 MySQL + Memcached 架构遇到的问题 实际上 MySQL 是适合进行海量数据存储的,通过 Memcached 将热点数据加 ...
- Redis和Memcached的区别【转】
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:1 Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储.2 Redis支持数据 ...
随机推荐
- 105032014138_牟平_z作业1
2)NextDate函数问题 NextDate函数说明一种复杂的关系,即输入变量之间逻辑关系的复杂性 NextDate函数包含三个变量month.day和year,函数的输出为输入日期后一天的日期. ...
- Python学习-41.Python中的断言
先来点题外话: 在现代编程开发中,TDD(测试驱动开发)变得越来越流行(PS:DDD(领域驱动开发)也是,但两者并不冲突,就像面向过程和面向对象).而作为TDD的根本——单元测试也是越来越重要,单元测 ...
- LeetCode138:Copy List with Random Pointer
题目: A linked list is given such that each node contains an additional random pointer which could poi ...
- .NET中的FileUpload控件的使用-原生JS(二)
本篇使用原生JS进行数据传输,使用FileUpload控件上传文件,适配IE. HTML <div class="container"> <div class=& ...
- MS SQL 分页存储过程
最近换了家新公司,但是新公司没有使用分页的存储过程.那我就自个写一个往项目上套 (效率怎么样就不怎么清楚没有详细的测试过) CREATE PROCEDURE [dbo].[pro_common_pag ...
- python——排序
从学校毕业出来后只知道冒泡排序,发现自己对排序的了解还是很浅显. 于是在网上搜索各种排序方法,以下是本人根据索搜出来的资料再结合自己理解作出的一些简单的阐述. 如果有不正确的地方欢迎大家指正.(共同学 ...
- C# npoi 从excel导入datagridviews 批量联网核查
DataSet ds = new DataSet(); OpenFileDialog openFileDialog = new OpenFileDialog(); openFileDialog.Fil ...
- Validation failed for one or more entities. See ‘EntityValidationErrors’ property for moredetails[转]
这里给大家介绍一个Exception类,让我们能够轻松的知道具体的哪一个字段出了什么问题. 那就是 System.Data.Entity.Validation.DbEntityValidationEx ...
- 688. Knight Probability in Chessboard
On an NxN chessboard, a knight starts at the r-th row and c-th column and attempts to make exactly K ...
- python http post json
直接上代码吧 #coding=utf-8 import os import urllib import urllib2 import re import cookielib import json h ...