elasticsearch学习笔记--原理介绍
前言:上一篇中我们对ES有了一个比较大概的概念,知道它是什么,干什么用的,今天给大家主要讲一下他的工作原理
介绍:ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
揭面
架构图
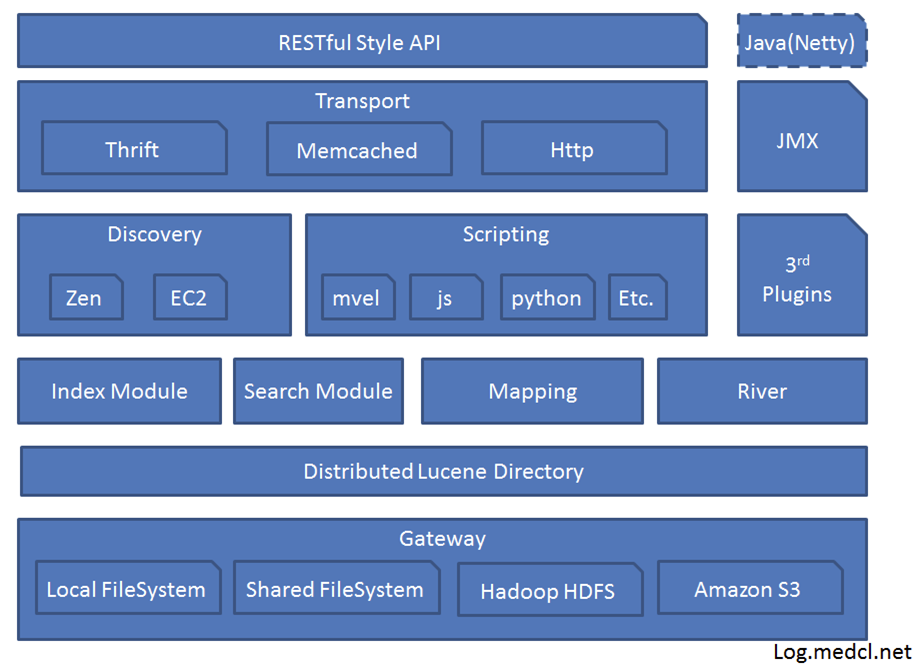
架构各模块介绍
Lucence Directory: 是lucene的框架服务发现以及选主 ZenDiscovery: 用来实现节点自动发现,还有Master节点选取,假如Master出现故障,其它的这个节点会自动选举,产生一个新的Master
Plugins:插件可以通过自定的方式扩展加强Elasticsearch的基本功能,比如可以自定义类型映射,分词器,本地脚本,自动发现等
Scripting:使用脚本语言可以计算自定义表达式的值,比如计算自定义查询相关度评分。
支持的脚本语言有groovy,js,mvel(1.3.0废弃),python等
Disovery:该模块主要负责集群中节点的自动发现和Master节点的选举。节点之间使用p2p的方式进行直接通信,不存在单点故障的问题。Elasticsearch中,Master节点维护集群的全局状态,比如节点加入和离开时进行shard的重新分配
River:代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中
Gateway:模块用于存储es集群的元数据信息。
Zen Discovery :zen发现机制是elasticsearch默认的内建模块。它提供了多播和单播两种发现方式,能够很容易的扩展至云环境。zen发现机制是和其他模块集成的,例如所有节点间通讯必须用trasport模块来完成。
核心概念
集群(Cluster): ES集群是一个或多个节点的集合,它们共同存储了整个数据集,并提供了联合索引以及可跨所有节点的搜索能力。多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。
集群靠其独有的名称进行标识,默认名称为“elasticsearch”。节点靠其集群名称来决定加入哪个ES集群,一个节点只能属一个集群。
节点(node): 一个节点是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能, 一个节点也有唯一的名字,群集通过节点名称进行管理和通信.
主节点:主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
数据节点:持有数据和倒排索引。
客户端节点:它既不能保持数据也不能成为主节点,该节点可以响应用户的情况,把相关操作发送到其他节点;客户端节点会将客户端请求路由到集群中合适的分片上。对于读请求来说,协调节点每次会选择不同的分片处理请求,以实现负载均衡。
部落节点:部落节点可以跨越多个集群,它可以接收每个集群的状态,然后合并成一个全局集群的状态,它可以读写所有节点上的数据。
索引(Index): ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
文档类型(Type):类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(Document) :文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。相当于数据库的“记录”
Mapping: 相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以自动根据数据创建
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。
分片(shard) :ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。
Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。
Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。
每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。
ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。
ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
创建索引

过程:当分片所在的节点接收到来自协调节点的请求后,会将该请求写入translog,并将文档加入内存缓存。如果请求在主分片上成功处理,该请求会并行发送到该分片的副本上。当translog被同步到全部的主分片及其副本上后,客户端才会收到确认通知。
内存缓冲会被周期性刷新(默认是1秒),内容将被写到文件系统缓存的一个新段(segment)上。虽然这个段并没有被同步(fsync),但它是开放的,内容可以被搜索到。
每30分钟,或者当translog很大的时候,translog会被清空,文件系统缓存会被同步。这个过程在Elasticsearch中称为冲洗(flush)。在冲洗过程中,内存中的缓冲将被清除,内容被写入一个新段。段的fsync将创建一个新的提交点,并将内容刷新到磁盘。旧的translog将被删除并开始一个新的translog。
ES如何做到实时检索?
由于在buffer中的索引片先同步到文件系统缓存,再刷写到磁盘,因此在检索时可以直接检索文件系统缓存,保证了实时性。
这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来说,几乎就相当于是实时可搜索了。
不过对于 ELK 的日志场景来说,并不需要如此高的实时性,而是需要更快的写入性能。我们可以通过 /_settings接口或者定制 template 的方式,加大 refresh_interval 参数。
当segment从文件系统缓存同步到磁盘时发生了错误怎么办? 数据会不会丢失?
由于Elasticsearch 在把数据写入到内存 buffer 的同时,其实还另外记录了一个 translog日志,如果在这期间故障发生时,Elasticsearch会从commit位置开始,恢复整个translog文件中的记录,保证数据的一致性。
等到真正把 segment 刷到磁盘,且 commit 文件进行更新的时候, translog 文件才清空。这一步,叫做flush。同样,Elasticsearch 也提供了 /_flush 接口。
索引数据的一致性通过 translog 保证,那么 translog 文件自己呢?
Elasticsearch 2.0 以后为了保证不丢失数据,每次 index、bulk、delete、update 完成的时候,一定触发刷新translog 到磁盘上,才给请求返回 200 OK。这个改变在提高数据安全性的同时当然也降低了一点性能
检索文档
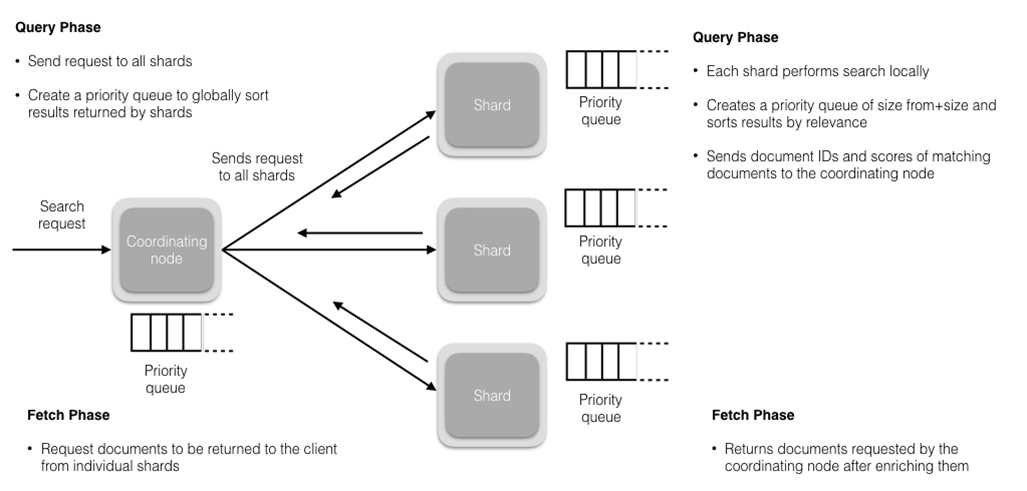
搜索相关性
相关性是由搜索结果中Elasticsearch打给每个文档的得分决定的。默认使用的排序算法是tf/idf(词频/逆文档频率)。词频衡量了一个词项在文档中出现的次数 (频率越高 == 相关性越高),逆文档频率衡量了词项在全部索引中出现的频率,是一个索引中文档总数的百分比(频率越高 == 相关性越低)。最后的得分是tf-idf得分与其他因子比如(短语查询中的)词项接近度、(模糊查询中的)词项相似度等的组合
更新删除索引
删除和更新也都是写操作。但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更。那么,该如何删除和更新文档呢?
磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并(我们将在本系列接下来的文章中讲到)时,在.del文件中被标记为删除的文档将不会被写入新段。
接下来我们看更新是如何工作的。在新的文档被创建时,Elasticsearch会为该文档指定一个版本号。当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
物理删除索引:当索引数据不断增长时,对应的segment也会不断的增多,查询性能可能就会下降。因此,Elasticsearch会触发segment合并的线程,把很多小的segment合并成更大的segment,然后删除小的segment,当这些标记为删除的segment不会被复制到新的索引段中。
Elasticseach查询
Elasticseach查询分为两种,结构化查询和全文查询;
尽管统一称之为query DSL,事实上Elasticsearch中存在两种DSL:查询DSL(query DSL)和过滤DSL(filter DSL)。
查询子句和过滤子句的自然属性非常相近,但在使用目的上略有区别。
简单来讲,当执行full-text查询或查询结果依赖于相关度分值时应该使用查询DSL,当执行精确值(extac-value)查询或查询结果仅有“yes”或“no”两种结果时应该使用过滤DSL。
Filter DSL计算及过滤速度较快,且适于缓存,因此可有效提升后续查询请求的执行速度。
而query DSL不仅要查找匹配的文档,还需要计算每个文件的相关度分值,因此为更重量级的查询,其查询结果不会被缓存。
不过,得益于倒排索引,一个仅返回少量文档的简单query或许比一个跨数百万文档的filter执行起来并得显得更慢。
Elasticsearch支持许多的query和filter,但最常用的也不过几种。
Filter DSL中常见的有term Filter、terms Filter、range Filter、exists and missing Filters和bool Filter。
而Query DSL中常见的有match_all、match 、multi_match及bool Query。鉴于时间关系,这里不再细述,朋友们可参考官方文档学习。
Queries用于查询上下文,而filters用于过滤上下文,不过,Elasticsearch的API也支持此二者合并运行。
组合查询可用于合并查询子句,组合过滤用于合并过滤子句,然而,Elasticsearch的使用习惯中,也常会把filter用于query上进行过滤。不过,很少有机会需要把query用于filter上的。
结构化搜索 是指查询包含内部结构的数据。日期,时间,和数字都是结构化的:它们有明确的格式给你执行逻辑操作。一般包括比较数字或日期的范围,或确定两个值哪个大。
文本也可以被结构化。一包蜡笔有不同的颜色:红色,绿色,蓝色。一篇博客可能被打上 分布式 和 搜索的标签。电子商务产品有商品统一代码(UPCs) 或其他有着严格格式的标识。
通过结构化搜索,你的查询结果始终是 是或非;是否应该属于集合。结构化搜索不关心文档的相关性或分数,它只是简单的包含或排除文档。
这必须是有意义的逻辑,一个数字不能比同一个范围中的其他数字 更多。它只能包含在一个范围中 —— 或不在其中。类似的,对于结构化文本,一个值必须相等或不等。这里没有 更匹配 的概念。
所谓的全文搜索查询通常是指在给定的文本域内部搜索指定的关键字,但搜索操作该需要真正理解查询者的目的,例如:
(1) 搜索“UK”应该返回包含“United Kingdom”的相关文档;(2) 搜索“jump”应该返回包含“JUMP”、“jumped”、“jumps”、“jumping”甚至是“leap”的文档;为了完成此类全文搜域的搜索,ES必须首先分析文本并将其构建成为倒排索引(inverted index),倒排索引由各文档中出现的单词列表组成,列表中的各单词不能重复且需要指向其所在的各文档。
因此,为了创建倒排索引,需要先将各文档中域的值切分为独立的单词(也称为term或token),而后将之创建为一个无重复的有序单词列表。这个过程称之为“分词(tokenization)”。
其次,为了完成此类full-text域的搜索,倒排索引中的数据还需进行“正规化(normalization)”为标准格式,才能评估其与用户搜索请求字符串的相似度。
这里的“分词”及“正规化”操作也称为“分析(analysis)”。
Analysis过程由两个步骤的操作组成:首先将文本切分为terms(词项)以适合构建倒排索引,其次将各terms正规化为标准形式以提升其“可搜索度”。这两个步骤由分析器(analyzers)完成。
一个分析器通常需要由三个组件构成:字符过滤器(Character filters)、分词器(Tokenizer)和分词过滤器(Token filters)组成。
字符过滤器:在文本被切割之前进行清理操作,例如移除HTML标签,将&替换为字符等;
分词器:将文本切分为独立的词项;简单的分词器通常是根据空白及标点符号进行切分;
分词过滤器:转换字符(如将大写转为小写)、移除词项(如移除a、an、of及the等)或者添加词项(例如,添加同义词);
Elasticsearch内置了许多字符过滤器、分词器和分词过滤器,用户可按需将它们组合成“自定义”的分析器。
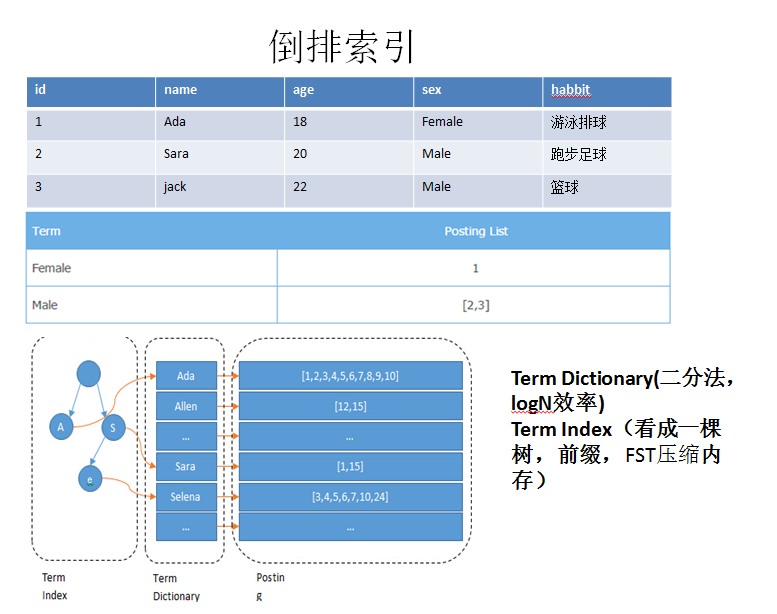
与SOLR比对

三种使用方式
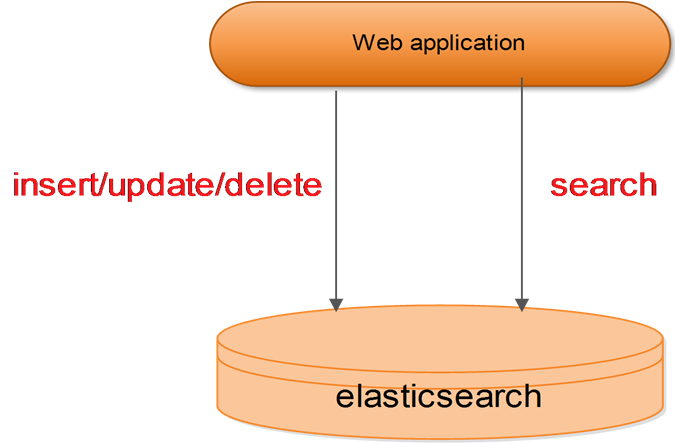
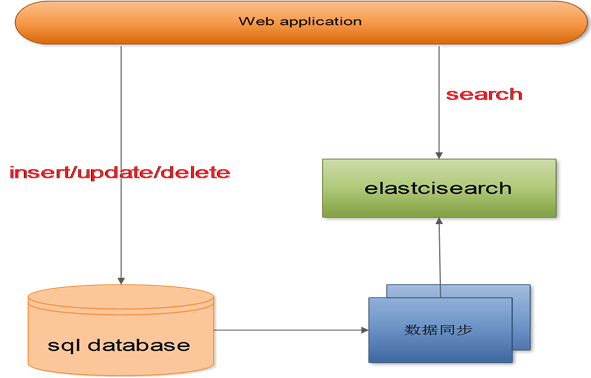

使用案例
(1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络
数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,
坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站,检索商品
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订
阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年
的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现
100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化
国内
(9)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门
的一个使用场景)
elasticsearch学习笔记--原理介绍的更多相关文章
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- ASP.NET Core Web开发学习笔记-1介绍篇
ASP.NET Core Web开发学习笔记-1介绍篇 给大家说声报歉,从2012年个人情感破裂的那一天,本人的51CTO,CnBlogs,Csdn,QQ,Weboo就再也没有更新过.踏实的生活(曾辞 ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- Elasticsearch学习系列之介绍安装
前言 关于ELK搭建的问题,或许你还有些模糊,其实你把我视频里讲的知识点串联起来就明白了.搭建ELK环境,看下面我说的: 首先,先把ES集群搭建起来,建议用CentOS6.5 64位的linux系统, ...
- Elasticsearch学习笔记(十一)Mapping原理
一.Mapping的功能作用 Mapping是定义如何存储和索引一个document及其所包含字段的过程. Mapping是index和type的元数据,每个type都有自己的一个mapping,决定 ...
- Elasticsearch学习笔记
Why Elasticsearch? 由于需要提升项目的搜索质量,最近研究了一下Elasticsearch,一款非常优秀的分布式搜索程序.最开始的一些笔记放到github,这里只是归纳总结一下. 首先 ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- 2018/2/11 ELK技术栈之ElasticSearch学习笔记二
终于有时间记录一下最近学习的知识了,其实除了写下的这些还有很多很多,但懒得一一写下了: ElasticSearch添加修改删除原理:ElasticSearch的倒排索引和文档一旦生成就不允许修改(其实 ...
随机推荐
- PyQt5整体介绍
1 PyQt5整体介绍 PyQt5是基于图形程序框架Qt5的Python语言实现,由一组Python模块构成. PyQt5的官方网站是:www.riverbankcomputing.co.uk. Py ...
- echarts彩虹柱状图 每个bar显示不同颜色, 标题在不同位置 ,工具中有可以直接保存为图片下载,平均线的添加
可以参考: https://echarts.baidu.com/echarts2/doc/example.html https://echarts.baidu.com/echarts2/doc/doc ...
- composer安装第三方库出现需要认证信息等原因
最近,在学习使用thinkcmf的时候,使用composer安装第三方类库,遇到了需要输入验证码的问题,援引https://laravel-china.org/topics/17893该链接中的讨论, ...
- Rigidbody和Collider
Rigidbody: 常用属性: Mass:默认为1,单位并不是g或kg,而是相对的质量计量单位,只决定物体的惯性: Drag:空气阻力: Angular Drag:角阻力,旋转时受的阻力: Use ...
- solr分组排序实现group by功能
http://wiki.apache.org/solr/FieldCollapsing solr分组排序,实现group by功能,代码待添加!
- 转:iOS-CoreLocation:无论你在哪里,我都要找到你!
1.定位 使用步骤: 创建CLLocationManager示例,并且需要强引用它 设置CLLocationManager的代理,监听并获取所更新的位置 启动位置更新 1 2 3 _manager = ...
- 判断android是否是debug
1.使用BuildConfig.DEBUG,这个在住modul里面是有效的,但是在有依赖库里面使用就会一直返回false,可以通过下面的方法解决:在library的build.gradle中添加以下代 ...
- Django 2.0.1 官方文档翻译:接下来读什么(page 14)
接下来读什么(page 14) 现在你应该已经阅读了所有的(page1-13 )介绍材料,决定继续使用Django.我们仅仅做了简要的介绍(事实上,如果你阅读了前面所有的内容,也只是全部文档的5%.) ...
- 【转载】wondows下wget的使用
原文地址:http://www.cnblogs.com/Randy0528/archive/2011/10/21/2219831.html 感觉要放弃windows了,,,哎,,,, 下载window ...
- python学习笔记2-文件操作
一.文件操作 #文件操作一定要注意文件指针 f=open('','a+,encoding=utf-8) f.seek(0) #文件指针移到行首 f.tell()#查看文件指针的位置 f.read()# ...