Python之路-pandas包的详解与使用
什么是pandas
pandas是一种Python数据分析的利器,是一个开源的数据分析包,最初是应用于金融数据分析工具而开发出来的,因此pandas为时间序列分析提供了很好的支持。pandas是PyData项目的一部分。
官方文档:http://pandas.pydata.org/pandas-docs/stable/
安装pandas
Python版本要求:2.7、3.4、3.5、3.6
依赖Python库:setuptools、NumPy、python-dateutil、pytz
安装方式:
Python的Anaconda发行版,已经安装好pandas库,不需要另外安装
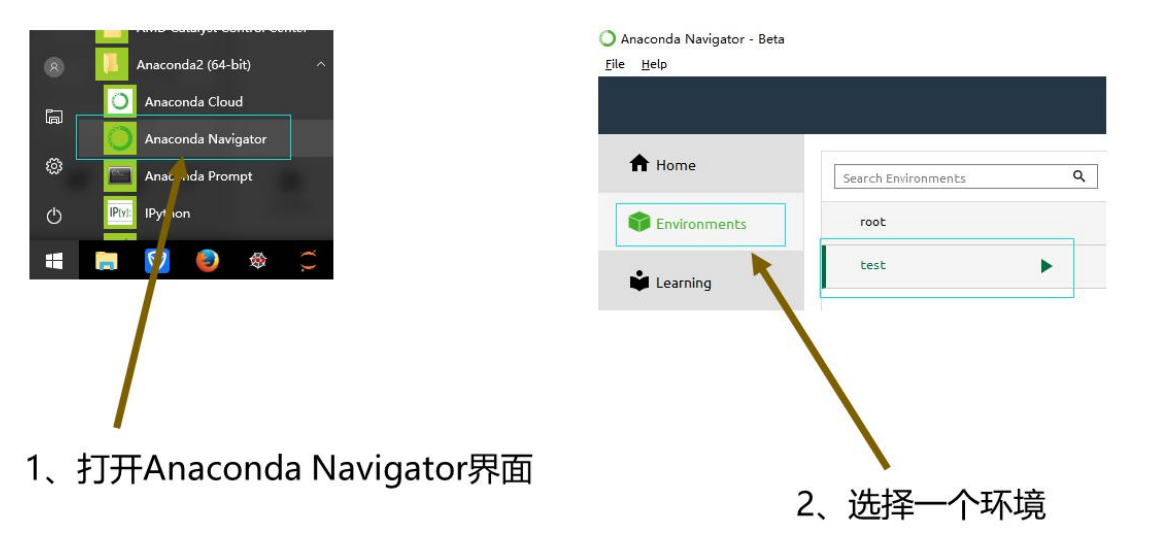
使用Anaconda界面安装,选择对应的pandas进行勾选安装即可
使用Anaconda命令安装:conda install pandas
使用PyPi安装命令安装:pip install pandas
使用Anaconda界面安装pandas

pandas操作
pandas引入约定
from pandas import Series,
DataFrame import pandas as pd
pandas基本数据结构
pandas中主要有两种数据结构,分别是:Series和DataFrame。
Series:一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。注意:Series中的索引值是可以重复的。
DataFrame:一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
Series:通过一维数组创建
练习
In [2]: import pandas as pd
import numpy as np
series创建 In [8]: # ser01 = pd.Series([1,2,3,4])
# ser01
ser01 = pd.Series(np.array([1,2,3,4]))
ser01
print(ser01.dtype)
print(ser01.values)
print(ser01.index)
print(ser01)
int32
[1 2 3 4]
RangeIndex(start=0, stop=4, step=1)
0 1
1 2
2 3
3 4
dtype: int32
In [9]: #设置索引(创建好后改)
ser01.index = ['a','b','c','d']
ser01
Out[9]:
a 1
b 2
c 3
d 4
dtype: int32
In [10]: ser01 = pd.Series(np.array([1,2,3,4]),index = ['a','b','c','d'])
ser01
Out[10]:
a 1
b 2
c 3
d 4
dtype: int32
Series:通过字典的方式创建
练习
通过字典的方式创建
In [11]:
ser02 = pd.Series({
'a':10, #key变为索引
'b':20,
'c':30
})
ser02
Out[11]:
a 10
b 20
c 30
dtype: int64
Series值的获取
Series值的获取主要有两种方式:
通过方括号+索引的方式读取对应索引的数据,有可能返回多条数据
通过方括号+下标值的方式读取对应下标值的数据,下标值的取值范围为:[0,len(Series.values));另外下标值也可以是负数,表示从右往左获取数据
Series获取多个值的方式类似NumPy中的ndarray的切片操作,通过方括号+下标值/索引值+冒号(:)的形式来截取series对象中的一部分数据。
Series的运算
NumPy中的数组运算,在Series中都保留了,均可以使用,并且Series进行数组运算的时候,索引与值之间的映射关系不会发生改变。
注意:其实在操作Series的时候,基本上可以把Series看成NumPy中的ndarray数组来进行操作。ndarray数组的绝大多数操作都可以应用到Series上。
练习
Series值得获取 In [15]: print(ser02['a'])
print(ser02[0])
print(ser02[0:2])
print(ser02['a':'c'])
10
10
a 10
b 20
dtype: int64
a 10
b 20
c 30
dtype: int64
Series的运算 In [16]: ser02 = pd.Series({
'a':10, #key变为索引
'b':20,
'c':30
})
ser02
Out[16]:
a 10
b 20
c 30
dtype: int64
In [20]: ser02[ser02 > 10]
ser02/10
ser02+10
ser02*10
Out[20]:
a 100
b 200
c 300
dtype: int64
In [22]: np.exp(ser02)
np.fabs(ser02)
Out[22]:
a 10.0
b 20.0
c 30.0
dtype: float64
Series缺失值检测
pandas中的isnull和notnull两个函数可以用于在Series中检测缺失值,这两个函数的返回时一个布尔类型的Series
Series自动对齐
当多个series对象之间进行运算的时候,如果不同series之间具有不同的索引值,那么运算会自动对齐不同索引值的数据,如果某个series没有某个索引值,那么最终结果会赋值为NaN。
Series及其索引的name属性
Series对象本身以及索引都具有一个name属性,默认为空,根据需要可以进行赋值操作
Series缺失值检测与处理
In [26]:
ser01 = pd.Series({
'a':10,
'b':20,
'c':30
})
ser01
ser02 = pd.Series(ser01,index = ['a','b','c','d'])
ser02
Out[26]:
a 10.0
b 20.0
c 30.0
d NaN
dtype: float64
In [28]:
ser02[pd.isnull(ser02)]
ser02[pd.notnull(ser02)]
Out[28]:
a 10.0
b 20.0
c 30.0
dtype: float64
In [29]:
ser01 = pd.Series([1,2,3,4],index = ['a','b','c','d'])
ser02 = pd.Series([10,20,30,40],index = ['e','a','f','b'])
ser01+ser02
Out[29]:
a 21.0
b 42.0
c NaN
d NaN
e NaN
f NaN
dtype: float64
In [32]:
#series的name属性
ser01 = pd.Series([1,2,3,4],index = ['a','b','c','d'])
ser01.name = 'aaa'
ser01.index.name = 'names'
ser01
Out[32]:
names
a 1
b 2
c 3
d 4
Name: aaa, dtype: int64
DataFrame: 通过二维数组创建
In [1]: import pandas as pd
In [3]: df01 = pd.DataFrame([['joe','susan','anne'],[79,45,67]])
df01
Out[3]:
0 1 2
0 joe susan anne
1 79 45 67
In [10]: df01 = pd.DataFrame([['joe','susan','anne'],[79,45,67]],index = ['one','teo'],columns = ['a','b','c'])
print(df01)
print(df01.index)
print(df01.columns)
print(df01.values)
a b c
one joe susan anne
teo 79 45 67
Index(['one', 'teo'], dtype='object')
Index(['a', 'b', 'c'], dtype='object')
[['joe' 'susan' 'anne']
[79 45 67]]
DataFrame: 通过字典的方式创建
索引对象
不管是Series还是DataFrame对象,都有索引对象。
索引对象负责管理轴标签和其它元数据(eg:轴名称等等)
通过索引可以从Series、DataFrame中获取值或者对某个索引值进行重新赋值
Series或者DataFrame的自动对齐功能是通过索引实现的
DataFrame数据获取
可以直接通过列索引获取指定列的数据, eg: df[column_name]
如果需要获取指定行的数据的话,需要通过ix方法来获取对应行索引的行数据,eg: df.ix[index_name]
通过字典的方法创建
In [42]:
df01 = pd.DataFrame({
'name':['joe','susan','anne'],
'sex':['men','women','women'],
'age':[18,19,20],
'classid':3
},index = ['one','two','three'])
print(df01)
age classid name sex
one 18 3 joe men
two 19 3 susan women
three 20 3 anne women
DataFrame获取数据
In [43]:
#列索引获取数据
df01['name']
df01.name
Out[43]:
one joe
two susan
three anne
Name: name, dtype: object
In [44]:
#列添加
df01['address'] = ['北京','上海','广州']
df01
Out[44]:
age classid name sex address
one 18 3 joe men 北京
two 19 3 susan women 上海
three 20 3 anne women 广州
In [45]:
#列删除
df01.pop('address')
df01
Out[45]:
age classid name sex
one 18 3 joe men
two 19 3 susan women
three 20 3 anne women
In [46]:
#列修改
df01['classid'] = 4
df01
Out[46]:
age classid name sex
one 18 4 joe men
two 19 4 susan women
three 20 4 anne women
In [47]:
#行获取
df01.ix['one']
df01.loc['two']#两种方式
df01.loc['two','name']
df01.loc['two']['name']#两种方式
Out[47]:
'susan'
In [33]:
#行增加
df01.ix['four'] = [21,3,'black','men']
df01
Out[33]:
age classid name sex
one 18 4 joe men
two 19 4 susan women
three 20 4 anne wpmen
four 21 3 black men
In [48]:
#行修改
df01.ix['four'] = [23,4,'ronaldo','men']
df01
Out[48]:
age classid name sex
one 18 4 joe men
two 19 4 susan women
three 20 4 anne women
four 23 4 ronaldo men
In [35]:
#行删除
df01.drop('four')
Out[35]:
age classid name sex
one 18 4 joe men
two 19 4 susan women
three 20 4 anne wpmen
pandas基本功能
数据文件读取/文本数据读取
索引、选取和数据过滤
算法运算和数据对齐
函数的应用和映射
重置索引
pandas:数据文件读取
通过pandas提供的read_xxx相关的函数可以读取文件中的数据,并形成DataFrame,常用的数据读取方法为:read_csv,主要可以读取文本类型的数据
In [13]: import pandas as pd
import numpy as np
读取文件 In [4]: df01 = pd.read_csv('data.csv')
df01
Out[4]:
name age sex
0 joe 18 men
1 susan 19 women
2 anne 20 women
In [5]: df02 = pd.read_excel('data.xlsx')
df02
Out[5]:
name age sex
0 joe 18 men
1 susan 19 women
2 anne 20 women
In [9]: df03 = pd.read_csv('data.txt',sep = ';',header = None)
df03
Out[9]:
0 1 2
0 joe 18 men
1 susan 19 women
2 anne 20 women
pandas:数据过滤获取
通过DataFrame的相关方式可以获取对应的列或者数据形成一个新的DataFrame, 方便后续进行统计计算。
数据过滤
In [11]:
df01 = pd.DataFrame({
'name':['joe','susan','anne'],
'sex':['men','women','women'],
'age':[18,19,20],
'classid':3
},index = ['one','two','three'])
print(df01)
print(df01.columns)
age classid name sex
one 18 3 joe men
two 19 3 susan women
three 20 3 anne women
Index(['age', 'classid', 'name', 'sex'], dtype='object')
In [12]:
df01[df01.columns[2:]]
Out[12]:
name sex
one joe men
two susan women
three anne women
pandas:缺省值NaN处理方法
对于DataFrame/Series中的NaN一般采取的方式为删除对应的列/行或者填充一个默认值

缺失值NaN In [32]: df01 = pd.DataFrame(np.random.randint(1,9,size = (4,4)))
df01
Out[32]:
0 1 2 3
0 7 7 1 6
1 3 8 5 7
2 7 4 3 2
3 8 2 6 6
In [33]: df01.ix[1:2,1] = np.NaN
df01.ix[1:2,2] = np.NaN
df01.ix[1:2,3] = np.NaN
df01
Out[33]:
0 1 2 3
0 7 7.0 1.0 6.0
1 3 NaN NaN NaN
2 7 NaN NaN NaN
3 8 2.0 6.0 6.0
In [34]: df01.dropna()#默认只要包含NaN就会删除
Out[34]:
0 1 2 3
0 7 7.0 1.0 6.0
3 8 2.0 6.0 6.0
In [35]: df01.ix[1,0] = np.NaN
df01.dropna(how = 'all')#指定阈值 删除行
Out[35]:
0 1 2 3
0 7.0 7.0 1.0 6.0
2 7.0 NaN NaN NaN
3 8.0 2.0 6.0 6.0
In [36]: df01.dropna(axis = 1)#删除列(包含就删除)
Out[36]:
0
1
2
3
In [37]: df01 = pd.DataFrame(np.random.randint(1,9,size = (4,4)))
df01
Out[37]:
0 1 2 3
0 1 7 7 2
1 2 7 7 8
2 7 8 2 1
3 8 5 4 4
In [40]: df01.ix[1,0] = np.NaN
df01.ix[1:2,1] = np.NaN
df01.ix[1:2,2] = np.NaN
df01.ix[1:2,3] = np.NaN
df01
Out[40]:
0 1 2 3
0 1.0 NaN 7.0 2.0
1 NaN NaN NaN NaN
2 7.0 NaN NaN NaN
3 8.0 5.0 4.0 4.0
In [41]: df01.fillna(0)#将0插入
Out[41]:
0 1 2 3
0 1.0 0.0 7.0 2.0
1 0.0 0.0 0.0 0.0
2 7.0 0.0 0.0 0.0
3 8.0 5.0 4.0 4.0
In [42]: df01.fillna({0:1,1:1,2:2,3:3})#指定列插入值
Out[42]:
0 1 2 3
0 1.0 1.0 7.0 2.0
1 1.0 1.0 2.0 3.0
2 7.0 1.0 2.0 3.0
3 8.0 5.0 4.0 4.0
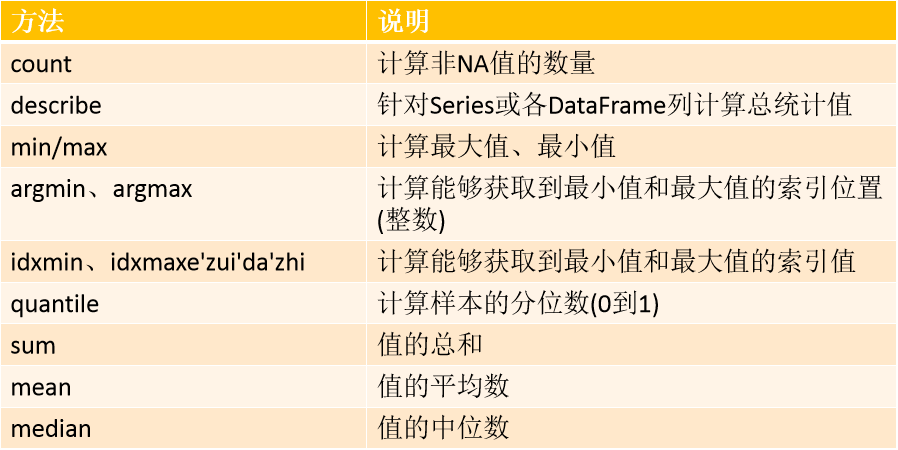
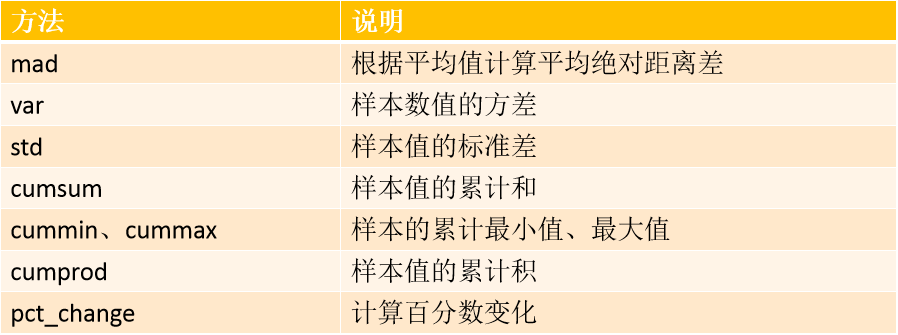
pandas:常用的数学统计方法
数学统计方法 In [56]: df01 = pd.DataFrame(np.random.randint(1,9,size = (5,4)))
df01
Out[56]:
0 1 2 3
0 4 2 3 6
1 5 3 1 8
2 7 1 1 7
3 8 8 2 5
4 4 4 6 7
In [50]: df01.sum() #列求和
# df01.sum(axis = 1) #0 按照列求和 1 按照行求和
Out[50]:
0 16
1 22
2 17
3 12
dtype: int64
In [53]: df01.min()
df01.min(axis = 1)
Out[53]:
0 1
1 2
2 2
3 2
dtype: int32
In [60]: df01.quantile(0.25)#样本位 分数位
df01.quantile(0.75)
Out[60]:
0 7.0
1 4.0
2 3.0
3 7.0
dtype: float64
In [57]: df01.median()#中位数
Out[57]:
0 5.0
1 3.0
2 2.0
3 7.0
dtype: float64
In [61]: df01.cumsum()#累加
Out[61]:
0 1 2 3
0 4 2 3 6
1 9 5 4 14
2 16 6 5 21
3 24 14 7 26
4 28 18 13 33
In [63]: df01.pct_change()#计算百分数变化
Out[63]:
0 1 2 3
0 NaN NaN NaN NaN
1 0.250000 0.500000 -0.666667 0.333333
2 0.400000 -0.666667 0.000000 -0.125000
3 0.142857 7.000000 1.000000 -0.285714
4 -0.500000 -0.500000 2.000000 0.400000
In [64]: df01.var()
Out[64]:
0 3.3
1 7.3
2 4.3
3 1.3
dtype: float64
In [65]: df01.std()
Out[65]:
0 1.816590
1 2.701851
2 2.073644
3 1.140175
dtype: float64
In [66]: df01.describe()
Out[66]:
0 1 2 3
count 5.00000 5.000000 5.000000 5.000000
mean 5.60000 3.600000 2.600000 6.600000
std 1.81659 2.701851 2.073644 1.140175
min 4.00000 1.000000 1.000000 5.000000
25% 4.00000 2.000000 1.000000 6.000000
50% 5.00000 3.000000 2.000000 7.000000
75% 7.00000 4.000000 3.000000 7.000000
max 8.00000 8.000000 6.000000 8.000000
pandas:相关系数与协方差
相关系数(Correlation coefficient):反映两个样本/样本之间的相互关系以及之间的相关程度。在COV的基础上进行了无量纲化操作,也就是进行了标准化操作。
协方差(Covariance, COV):反映两个样本/变量之间的相互关系以及之间的相关程度。
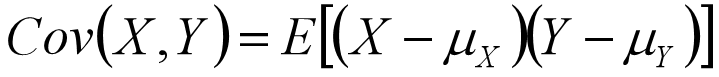
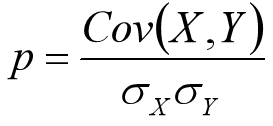
通俗理解协方差:如果有X,Y两个变量,每时刻的"X值与均值只差"乘以"Y值与其均值只差"得到一个乘积,再对这每时刻的乘积求和并求出均值。
如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明方向程度越高。
pandas:唯一值、值计数以及成员资格
unique方法用于获取Series中的唯一值数组(去重数据后的数组)
value_counts方法用于计算一个Series中各值的出现频率
isin方法用于判断矢量化集合的成员资格,可用于选取Series中或者DataFrame中列中数据的子集
相关系数与协方差
In [76]:
df01 = pd.DataFrame({
'GDP':[400,500,600,700],
'forgin_trade':[300,200,300,500,],
'year':['2012','2013','2014','2015']
})
df01
Out[76]:
GDP forgin_trade year
0 400 300 2012
1 500 200 2013
2 600 300 2014
3 700 500 2015
In [74]:
df01.cov()#协方差
Out[74]:
GDP forgin_trade
GDP 16666.666667 -8333.333333
forgin_trade -8333.333333 9166.666667
In [77]:
df01.corr()
Out[77]:
GDP forgin_trade
GDP 1.000000 0.718185
forgin_trade 0.718185 1.000000
In [81]:
#唯一值
ser01 = pd.Series(['a','b','c','d','a','b','c','d'])
ser01
ser02 = ser01.unique()
print(ser02.dtype)
object
In [85]:
#值计数
ser01 = pd.Series(['a','b','c','d','a','b','c','d','b','c','d'])
ser01.value_counts()
Out[85]:
c 3
b 3
d 3
a 2
dtype: int64
In [88]:
#成员资格
ser01.isin(['b','c'])
ser01[ser01.isin(['b','c'])]#过滤
Out[88]:
1 b
2 c
5 b
6 c
8 b
9 c
dtype: object
pandas:层次索引
在某一个方向拥有多个(两个及两个以上)索引级别
通过层次化索引,pandas能够以较低维度形式处理高纬度的数据
通过层次化索引,可以按照层次统计数据
层次索引包括Series层次索引和DataFrame层次索引
pandas:按照层次索引进行统计数据
层次索引 In [99]: data = pd.Series([988.44,95678,32455,2345,4346],
index = [
['2001','2001','2001','2002','2002'],
['苹果','香蕉','西瓜','香蕉','西瓜']
])
print(data)
data['2001']
2001 苹果 988.44
香蕉 95678.00
西瓜 32455.00
2002 香蕉 2345.00
西瓜 4346.00
dtype: float64
Out[99]:
苹果 988.44
香蕉 95678.00
西瓜 32455.00
dtype: float64
In [118]: df = pd.DataFrame({
'year':[2001,2001,2002,2002,2003],
'fruit':['apple','banana','apple','banana','apple'],
'production':[2345,3245,5567,4356,5672]
})
df
Out[118]:
fruit production year
0 apple 2345 2001
1 banana 3245 2001
2 apple 5567 2002
3 banana 4356 2002
4 apple 5672 2003
In [119]: df2 = df.set_index(['year','fruit'])
df2
Out[119]:
production
year fruit
2001 apple 2345
banana 3245
2002 apple 5567
banana 4356
2003 apple 5672
In [121]: df2.ix[2001,'apple']
Out[121]:
production 2345
Name: (2001, apple), dtype: int64
In [122]: df2.sum(level = 'year')
Out[122]:
production
year
2001 5590
2002 9923
2003 5672
In [123]: df2.mean(level='fruit')
Out[123]:
production
fruit
apple 4528.0
banana 3800.5
In [124]: df2.min(level=['year','fruit'])
Out[124]:
production
year fruit
2001 apple 2345
banana 3245
2002 apple 5567
banana 4356
2003 apple 5672
Python之路-pandas包的详解与使用的更多相关文章
- python之路2(基础详解)
python一切都是对象: 列子:
- python pandas字符串函数详解(转)
pandas字符串函数详解(转)——原文连接见文章末尾 在使用pandas框架的DataFrame的过程中,如果需要处理一些字符串的特性,例如判断某列是否包含一些关键字,某列的字符长度是否小于3等等 ...
- python+requests接口自动化测试框架实例详解
python+requests接口自动化测试框架实例详解 转自https://my.oschina.net/u/3041656/blog/820023 摘要: python + requests实 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- 沉淀,再出发:python中的pandas包
沉淀,再出发:python中的pandas包 一.前言 python中有很多的包,正是因为这些包工具才使得python能够如此强大,无论是在数据处理还是在web开发,python都发挥着重要的作用,下 ...
- (转)python标准库中socket模块详解
python标准库中socket模块详解 socket模块简介 原文:http://www.lybbn.cn/data/datas.php?yw=71 网络上的两个程序通过一个双向的通信连接实现数据的 ...
- python数据分析数据标准化及离散化详解
python数据分析数据标准化及离散化详解 本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下 标准化 1.离差标准化 是对原始数据的线性变换,使结果映射到[0 ...
- python中requests库使用方法详解
目录 python中requests库使用方法详解 官方文档 什么是Requests 安装Requests库 基本的GET请求 带参数的GET请求 解析json 添加headers 基本POST请求 ...
随机推荐
- linux运维、架构之路-CentOS7
一.CentOS7介绍 1.CentOS7使用起来最大的变化就是服务管理 2.systemd是linux下的一种init软件,开发目标是提供更优秀的框架以表示系统服务间的依赖关系,并依此实现系统初始化 ...
- JavaScript算数运算符和一元运算符
算数运算符 加法运算符(Addition): x + y 减法运算符(Subtraction): x - y 乘法运算符(Multiplication): x * y 除法运算符(Division): ...
- Linq in not in\like not like
别人的博客 http://blog.163.com/lesheng@126/blog/static/357364652010102111051668/ using System.Data.Linq.S ...
- C++ 对象间通信框架 V2.0 ××××××× 之(五)
类定义: ======================================================================= // MemberFuncPointer.h: ...
- bootstrap动态调用select下拉框
html代码: <label for="classify" class="col-sm-2 control-label">填报部门:</lab ...
- 利用python进行数据分析--pandas入门2
随书练习,第五章 pandas入门2 # coding: utf-8 # In[1]: from pandas import Series,DataFrame import pandas as pd ...
- 谷歌 AXURE RP EXTENSION拓展问题
我们打开某种文件页面是 会提示我们下载 AXURE RP EXTENSION 拓展. 其实我们可以直接用ie浏览器打开即可,不用下载
- Django项目执行时No Module Named ' ' 问题的解决情况
出现这种问题的情况大致都是因为该模块未安装,使用 pip install xxx 进行安装,即可解决此类问题. 出现ModuleNotFoundError: No module named 'rest ...
- ORACLE Physical Standby DG 之switch over
DG架构图如下: 计划,切换之后的架构图: DG切换: 主备切换:这里所有的数据库数据文件.日志文件的路径是一致的 [旧主库]主库primarydb切换为备库standby3主库检查switchove ...
- MVC2: 路由 及 遇到问题记录
MVC 路由 重定向 问题记录 1)MVC 路由 入口方法: (Global.asax)Application_Start()--->(App_Start/RouteConfig.cs)Regi ...