贾扬清谈大数据&AI发展的新挑战和新机遇
摘要:2019云栖大会大数据&AI专场,阿里巴巴高级研究员贾扬清为我们带来《大数据AI发展的新机遇和新挑战》的分享。本文主要从人工智能的概念开始讲起,谈及了深度学习的发展和模型训练,以及数据的爆发增长,着重阐述了算法、数据和算力的闭环。
以下是精彩视频内容整理:
作为一个研究者的身份,在这么多年AI的科研工作之中,有哪些有意思的事情?
说到人工智能,从十几年前我开始做人工智能的时候,我当时认为毕业可能就失业了,我们永远不会像做数据库、系统、架构的人那样容易找到工作。到了2012年之后,我发现人工智能能够找到工作了,不光如此,而且大家还非常想要人工智能方面的人才。从2013年开始,我们常常从各路媒体口中听到人工智能的未来已来。我现在仍然在做人工智能的研究,我认为人工智能的未来也没有那么快到来。所以回想人工智能的这些东西,我一直在想,人工智能困难不困难?我们对于人工智能困难程度的估计是怎么样的?

通过翻阅历史书我得知,最早提出人工智能概念的人是麦卡锡,这个预言是做什么呢?让机器使用语言让它来解决现在还只有人能够解决的问题。最重要的一点,既然是一个智能企业,那么它能够自我进化,大家觉得努力一个夏天,就能够取得重大的进展,这是1956年发生的事情。现在我们知道,除了产生了一些人工智能的定义,剩下的什么都没有发生。

到了1966年,我们听到一句话:我们有非常好的想法,只差一个程序了。当时有一个教授提出了MIT的夏季视觉计划,要有效的利用夏天实习生来搭建计算机视觉系统的核心来识别物体与背景,以及物体的种类。1966年的夏天过去了,什么都没有发生,1966年我们没有看到无人车,现在也没有看到无人车。
为什么实现人工智能那么困难?人的大脑在功耗上来说只有20W,一个手机是5W的功率,所以人可以做非常多的事情,那么,为什么实现人工智能要那么困难?我最开始做人工智能的时候是从计算机视觉起家的,让我们大概来看一下计算机视觉在这几年做了什么事情。

2012年深度学习流行之前,计算机视觉各种方法都采取了简单的特征来解决问题,处理各种图像,手工计算图像猜测最有用的特征是边,所以我们当时手写了很多的算法,从图片中拿一个小块出来,算一下左边的像素值是多少,右边的像素值是多少,有差别就会有一个竖边,用这样简单的竖边、横边、45度边等手工设计特征来做图像识别。
我们显然知道人在做图像识别的时候,用这样的特征是远远不够的,我们看上面的这个图,它多半能够有一点效果,但是用这样的特征来做自动驾驶系统,我们不敢做,不知道大家敢不敢。
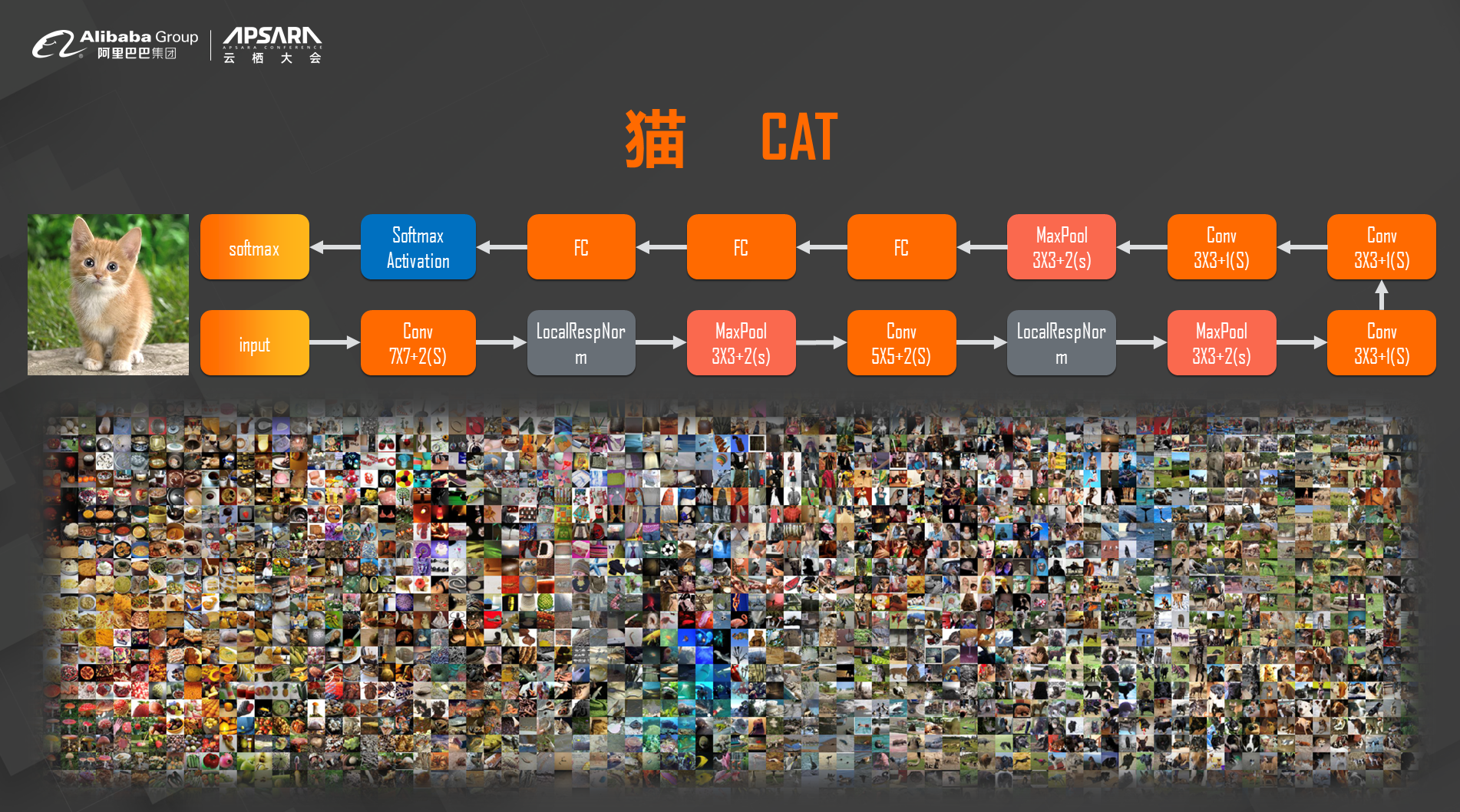
2012年开始提出了用更加深度的神经网络和数据驱动的训练来形成更加复杂的、类似于人的视觉系统的计算机视觉模型的想法。它的想法是说,模型像人的大脑一样是分层的,我的收入通过每一层来提取更复杂的信息来形成抽象的概念,每一层神经网络中间都有很多的参数,这些参数是通过大量数据训练来形成的。这样的深度学习方法能够给我们带来非常灵活的设计和非常多的不同领域的应用,从计算机系统到语音到自然处理,几乎所有能够感知到的领域都能够用到深度学习来解决掉。深度学习是机器学习的一部分,并没有像神经网络那么牛,但是在这么多年之中,我们发现并沉淀了很多非常好的算法,比如说决策数和线性模型,它们的计算量不需要有深度学习那么大,但是它们在非常多的领域有非常棒的表现。

我们在Flink之中实现特别多的浅层学习模型或者说传统学习模型,今天无论是传统学习还是深度学习,尤其是最近几年的深度学习,给我们带来了算法上非常大的潜力。我们回想一下,最开始手工设计的图像特征,我们发现它最大的限制并不在于我们能够处理多大的数据,有多大的算力,反而是我们的算法本身就是简单的。通过深度学习,通过其它的计算学习算法的进化,我们的算法能够处理更多的数据,可以学到更加复杂的决策,越来越多算法的复杂性就对算力提出了巨大的需求,这个说起来不太有体感,我们还是拿图像来做一个例子。

深度学习系统或者说今天所提到的人脸识别、车识别、物体识别,都是基于深度神经网络来做的。在2015年的时候,当时有人提出了一个Resnet模型,能够达到非常好的正确率。那么,Resnet训练一次需要在120万张图片之中进行10的18次方的计算。我当时有一次去伦敦的时候算了一下,如果所有伦敦的人每秒钟能够算一次计算的话,全伦敦需要4千年来训练模型。咱们中国有人多的优势,但也不能这么用。所以通过传统的高性能方式,我们可以把大量的GPU通过高速的网络互联起来,让这些GPU做两件事情:一是每一个GPU领一堆小图片去算一下模型,看每个参数应该怎么样进化,二是通过高速互联,使得GPU可以很快同步模型,确定这个模型应该往这里走或者往那里走,这在传统的高性能计算领域都有非常好的积累,所以今天我们在阿里的平台上通过Eflops+PAI可以实现在3分钟之内训练出这样的resnet模型。最初训练深度学习的时候大概需要7天的时间,Resnet的计算量增加了10倍,在增加的基础上还可以通过软硬件协同的方式,把训练的时间从10天降低为3分钟,所以这就是AI系统和大数据结合所带来的价值。
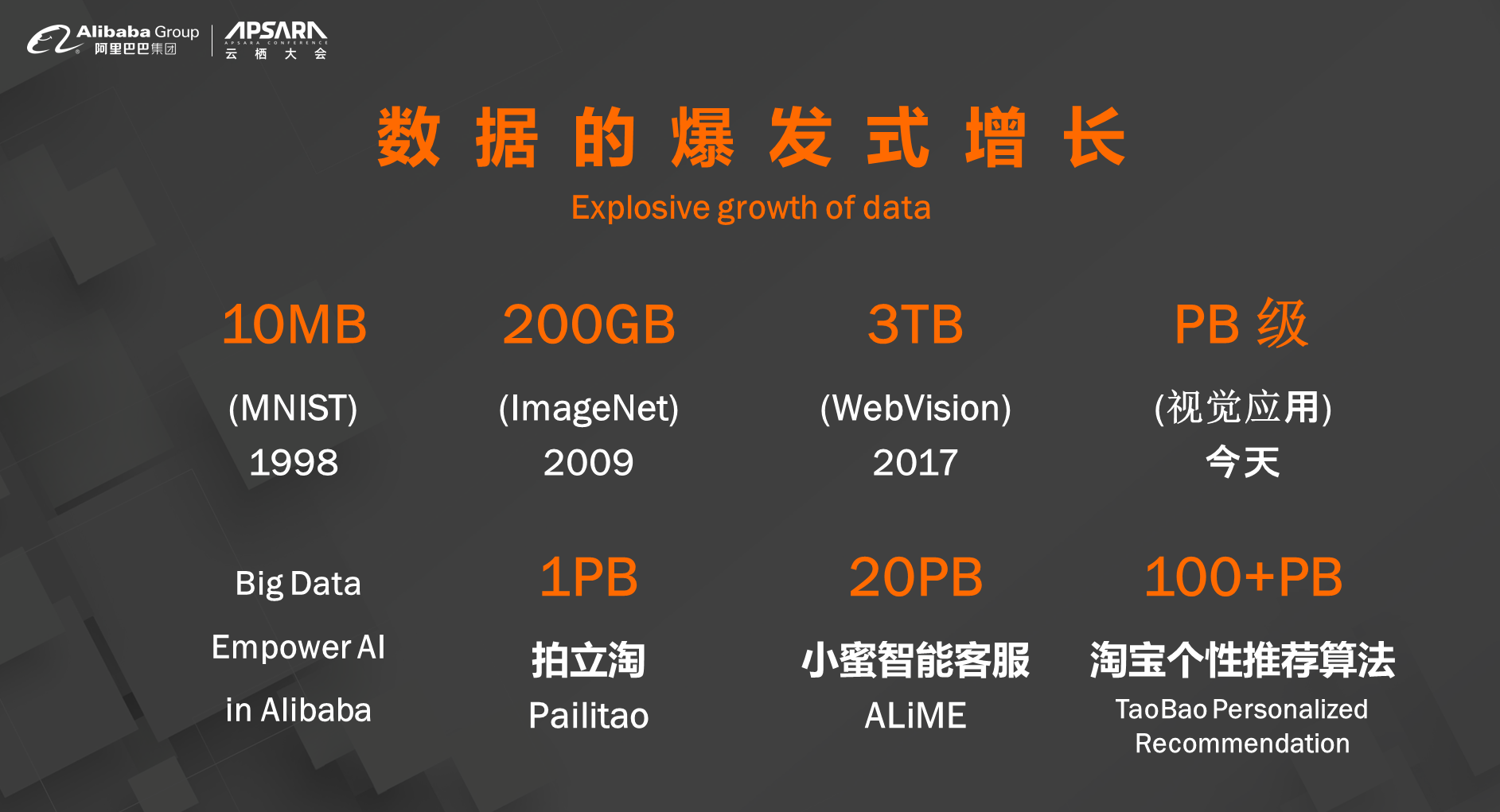
我们刚才说120万张图片的数据集,在实际的应用之中,我们发现数据的数量是呈指数级的增长,而且是成千上万倍差别的,拍立淘是阿里巴巴用来让用户用手机拍一个图片来看在淘宝之中相似的图片是怎么样的,拍立淘模型训练需要一个PB左右的图像,和现在的图像相比,大了非常多,计算量也大了许多。在我们今天有了大量数据的情况下,不仅是数据量给我们带来了很大的挑战,而且数据的质量也给我们带来了很大的挑战。我们在实验室当中做计算机视觉、语言、图像等等工作的时候,这些数据是比较简单的,我们可以想象一下怎么样存储图片?就是有一个文件夹放一个图片在里面就可以了,但是在实际应用中,我们在做推荐系统的时候,这些数据一定程度上是比较脏的,不是说它比较差,而是它本身需要大量的处理,很多核心推荐算法的来源是用户购买的行为,哪些行为存在log里边,我们需要来理解这个log,通过比较复杂的数据链路来清洗数据,所以我们说算力算法数据的合成是AI的三个要素。
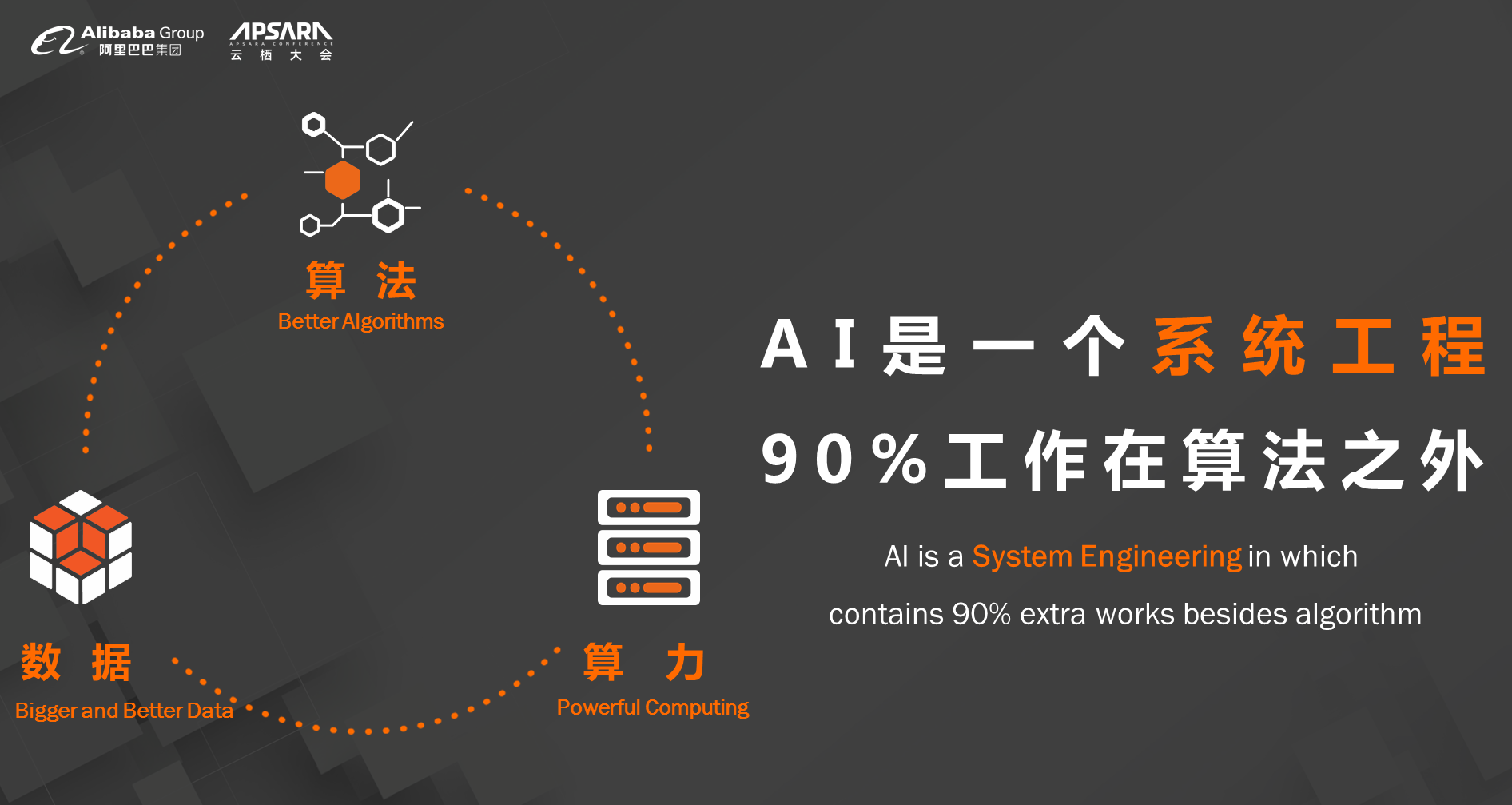
我们在讲AI的时候会提到算力算法和数据的闭环,但是其实90%的工作是在算法之外的,或者说数据算力之外的,我们在考虑AI系统的时候,谷歌在十几年前就提出了这样的理论,机器学习这件事情就像是一个高息的贷款,最开始觉得非常美好,但是在实际落地的时候,我们需要付的利息或干的事情是非常多的。
我在Facebook工作时,做过手机端的深度学习的训练,手机端的学习是非常多的,模型的压缩、模型的部署、运行速度调优等一系列的东西。有一天早上8点钟我到了办公室,看到有些同学在他的桌子上放了一个测试的手机,它的背后贴了一个小贴纸,贴纸说:昨天还好好的,今天发现重新训练的模型不对了。很多做过深度学习的同学有这样的感觉,今天我们在做深度学习的部署和推理的时候,其实不光是跑一个GPU跑一个训练那么简单,从最开始如何来设置我们的模型和数据输入的链路,数据怎么样去提取特征,到后面怎么样来管理资源,最后怎么来部署,怎么样来管理自己在模型上的想法等等,这是一个非常大的系统工程,不光是说我拿一个CNN的算法放在手机上就行了,今天AI在要落地的时候,不光是有算法,而是要有一系列系统工程的内容。
大数据和AI峰会就是想要给大家分享我们在处理大数据和AI的时候所遇到的问题,所想到的一些心得,所沉淀下来的方法论和能够给大家提供的一系列工具和想法。

飞天大数据平台和AI平台是支撑阿里巴巴所有的应用,我们也和社区、合作伙伴有非常紧密的联系。今天由我抛砖引玉的简单讲了讲一些想法,我希望在各位嘉宾的分享之中,能够更加详细的和大家探讨大数据和AI在将来的走法,我们应该怎么样把算法、数据和算力的闭环真正和产业结合起来落到实处去,这是我想要给大家分享的内容。
详细了解飞天大数据平台&飞天AI平台核心产品
EB级云智能数据仓库 MaxCompute
一站式大数据智能开发云平台 DataWorks
实时计算云原生版本
在PAI平台,快速便捷拥有云端PyTorch体验
开源大数据生态 E-MapReduce
双11福利来了!先来康康#怎么买云服务器最便宜# [并不简单]参团购买指定配置云服务器仅86元/年,开团拉新享三重礼:1111红包+瓜分百万现金+31%返现,爆款必买清单,还有iPhone 11 Pro、卫衣、T恤等你来抽,马上来试试手气:https://www.aliyun.com/1111/2019/home?utm_content=g_1000083110
本文作者:晋恒
本文为云栖社区原创内容,未经允许不得转载。
贾扬清谈大数据&AI发展的新挑战和新机遇的更多相关文章
- 2016中国大数据技术大会( BDTC ) 共商大数据时代发展之计
中国大数据技术大会(BDTC)的前身是Hadoop中国云计算大会(HadoopinChina,HiC).从2008年仅60余人参加的技术沙龙发展到当下数千人的技术盛宴,目前已成为国内最具影响力.规模最 ...
- [Hadoop 周边] 浅谈大数据(hadoop)和移动开发(Android、IOS)开发前景【转】
原文链接:http://www.d1net.com/bigdata/news/345893.html 先简单的做个自我介绍,我是云6期的,黑马相比其它培训机构的好偶就不在这里说,想比大家都比我清楚: ...
- 浅谈大数据和hadoop家族
按照时间的早晚从大数据出现之前的时代讲到现在.暂时按一个城市来比喻吧,反正Landscape的意思也大概是”风景“的意思. 早在大数据概念出现以前就存在了各种各样的关于数学.统计学.算法.编程语言的研 ...
- 浅谈大数据与hadoop家族
按照时间的早晚从大数据出现之前的时代讲到现在.暂时按一个城市来比喻吧,反正Landscape的意思也大概是”风景“的意思. 早在大数据概念出现以前就存在了各种各样的关于数学.统计学.算法.编程语言的研 ...
- 【T-BABY 夜谈大数据】基于内容的推荐算法
这个系列主要也是自己最近在研究大数据方向,所以边研究.开发也边整理相关的资料.网上的资料经常是碎片式的,如果要完整的看完可能需要同时看好几篇文章,所以我希望有兴趣的人能够更轻松和快速地学习相关的知识. ...
- 任何抛开业务谈大数据量的sql优化都是瞎扯
周三去某在线旅游公司面试.被问到了一个关于数据量大的优化问题.问题是:一个主外键关联表,主表有一百万数据,外键关联表有一千万的数据,要求做一个连接. 本人接触过单表数据量最大的就是将近两亿行历史数据( ...
- 浅谈大数据神器Spark中的RDD
1.究竟什么是RDD呢? 有人可能会回答是:Resilient Distributed Dataset.没错,的确是如此.但是我们问这个实际上是想知道RDD到底是个什么东西?以及它到底能干嘛?好的,有 ...
- zz独家专访AI大神贾扬清:我为什么选择加入阿里巴巴?
独家专访AI大神贾扬清:我为什么选择加入阿里巴巴? Natalie.Cai 拥有的都是侥幸,失去的都是人生 关注她 5 人赞同了该文章 本文由 「AI前线」原创,原文链接:独家专访AI大神贾扬清:我 ...
- 大数据与 AI 生态中的开源技术总结
本文由云+社区发表 作者:堵俊平 在数据爆炸与智能革命的新时代,新的平台与应用层出不穷,开源项目推动了前沿技术和业界生态快速发展.本次分享将以技术和生态两大视角来看大数据和人工智能技术的发展,通过分析 ...
随机推荐
- boost serialization
Archive An archive is a sequence of bytes that represented serialized C++ objects. Objects can be ad ...
- boost exception
boost exception provides a new exception type, that lets you add data to an exception after it has b ...
- fedora下编译运行java傻瓜入门级教程
操作步骤: 编译运行环境的搭建 fedora下默认安装为GNU公司的JDK,如下所示 $java -version java version "1.7.0_25" OpenJDK ...
- Bugku | 数字验证正则绕过
语法: int preg_match_all (字符串$ pattern ,字符串$ subject [,数组和$ matches [,整数$ flags = PREG_PATTERN_ORDER [ ...
- 初步认识pug
一.初步认识pug 1.所谓的pug就是我们之前说的jade,也就是一种通过缩进的方式来编写代码的过程,在编译的过程中,我们不需要考虑标签是否闭合的问题.此外,用这种编译方式,加快了我们写代码的速度, ...
- jQuery-resize和scroll的性能优化
## 下面是进行测试和研究怎么实现的用的 Document 改变页面大小试试 Document 滚动滚动条试试
- 114、TensorFlow设备放置
# creates a variable named v and places it on the second GPU device import tensorflow as tf #with tf ...
- rm -rf无法删除文件解决方法
# 列出 file.sh 文件的属性 lsattr file.sh # 列出当前目录下所有文件以及文件夹的属性 lsattr # 为 file.sh 文件增加 i 标识 chattr +i file. ...
- play framework 在idea简单运行配置(mac为例)
文章目录 play 最基本的构建 在idea中配置 配置jdk相关 配置play 运行 运行 play 最基本的构建 https://blog.csdn.net/dataiyangu/article/ ...
- Hibernate 异常org.hibernate.LazyInitializationException: could not ini...
错误页面提示 could not initialize proxy - no Session 控制台 org.hibernate.LazyInitializationException: could ...