大数据笔记(七)——Mapreduce程序的开发
一.分析Mapreduce程序开发的流程
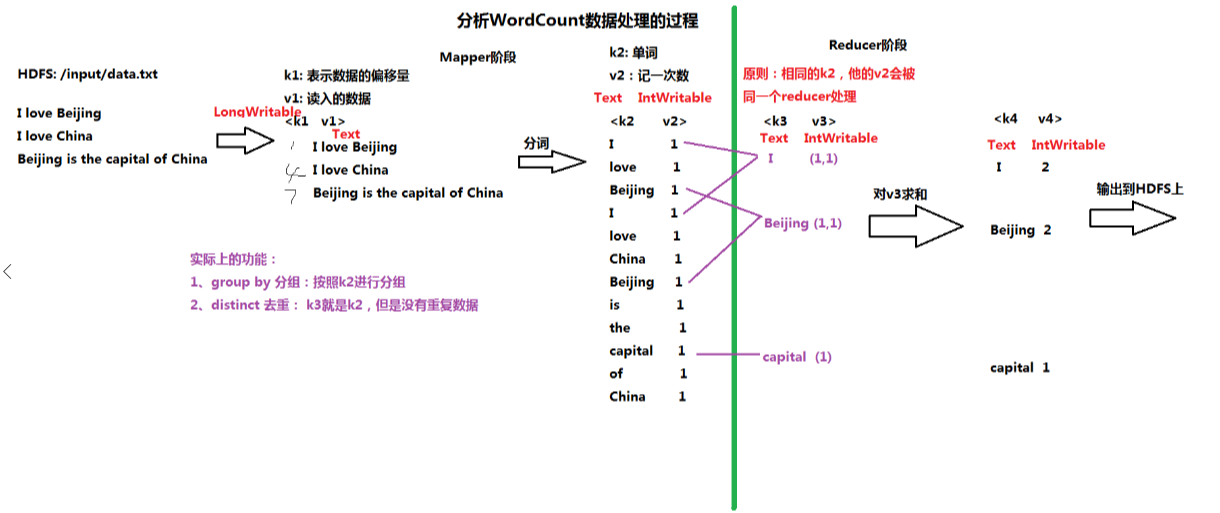
1.图示过程
输入:HDFS文件 /input/data.txt
Mapper阶段:
K1:数据偏移量(以单词记)V1:行数据
K2:单词 V2:记一次数
Reducer阶段 :
K3:单词(=K2) V3:V2计数的集合
K4:单词 V4:V3集合中元素累加和
输出:HDFS
2.开发WordCount程序需要的jar
/root/training/hadoop-2.7.3/share/hadoop/common
/root/training/hadoop-2.7.3/share/hadoop/common/lib /root/training/hadoop-2.7.3/share/hadoop/mapreduce
/root/training/hadoop-2.7.3/share/hadoop/mapreduce/lib
3.WordCountMapper.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException { //Context代表Mapper的上下文 上文:HDFS 下文:Mapper
//取出数据: I love beijing
String data = v1.toString(); //分词
String[] words = data.split(" "); //输出K2 V2
for (String w : words) {
context.write(new Text(w), new LongWritable(1));
} } }
4.WordCountReducer.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override
protected void reduce(Text k3, Iterable<LongWritable> v3,
Context context) throws IOException, InterruptedException {
//context 代表Reduce的上下文 上文:Mapper 下文:HDFS
long total = 0;
for (LongWritable l : v3) {
//对v3求和
total = total + l.get();
} //输出K4 V4
context.write(k3, new LongWritable(total));
} }
5.WordCountMain.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMain { public static void main(String[] args) throws Exception {
//创建一个job = mapper + reducer
Job job = Job.getInstance(new Configuration());
//ָ指定任务的入口
job.setJarByClass(WordCountMain.class); //ָ指定任务的mapper和输出的数据类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);//指定k2
job.setMapOutputValueClass(LongWritable.class);//指定v2
//ָ指定任务的reducer和输出的数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//ָ指定输入的路径(map)、输出的路径(reduce)
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//ִ执行任务
job.waitForCompletion(true);
}
}
打包,传到HDFS上:

运行任务:
hadoop jar wc.jar /input/data.txt /output/day0228/wc
日志信息:
18/03/01 00:14:00 INFO client.RMProxy: Connecting to ResourceManager at bigdata11/192.168.153.11:8032
18/03/01 00:14:01 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/03/01 00:14:01 INFO input.FileInputFormat: Total input paths to process : 1
18/03/01 00:14:01 INFO mapreduce.JobSubmitter: number of splits:1
18/03/01 00:14:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1519833888534_0001
18/03/01 00:14:02 INFO impl.YarnClientImpl: Submitted application application_1519833888534_0001
18/03/01 00:14:02 INFO mapreduce.Job: The url to track the job: http://bigdata11:8088/proxy/application_1519833888534_0001/
18/03/01 00:14:02 INFO mapreduce.Job: Running job: job_1519833888534_0001
18/03/01 00:14:16 INFO mapreduce.Job: Job job_1519833888534_0001 running in uber mode : false
18/03/01 00:14:16 INFO mapreduce.Job: map 0% reduce 0%
18/03/01 00:14:24 INFO mapreduce.Job: map 100% reduce 0%
18/03/01 00:14:31 INFO mapreduce.Job: map 100% reduce 100%
查看结果:
hdfs dfs -ls /output/day0228/wc

hdfs dfs -cat /output/day0228/wc/part-r-00000

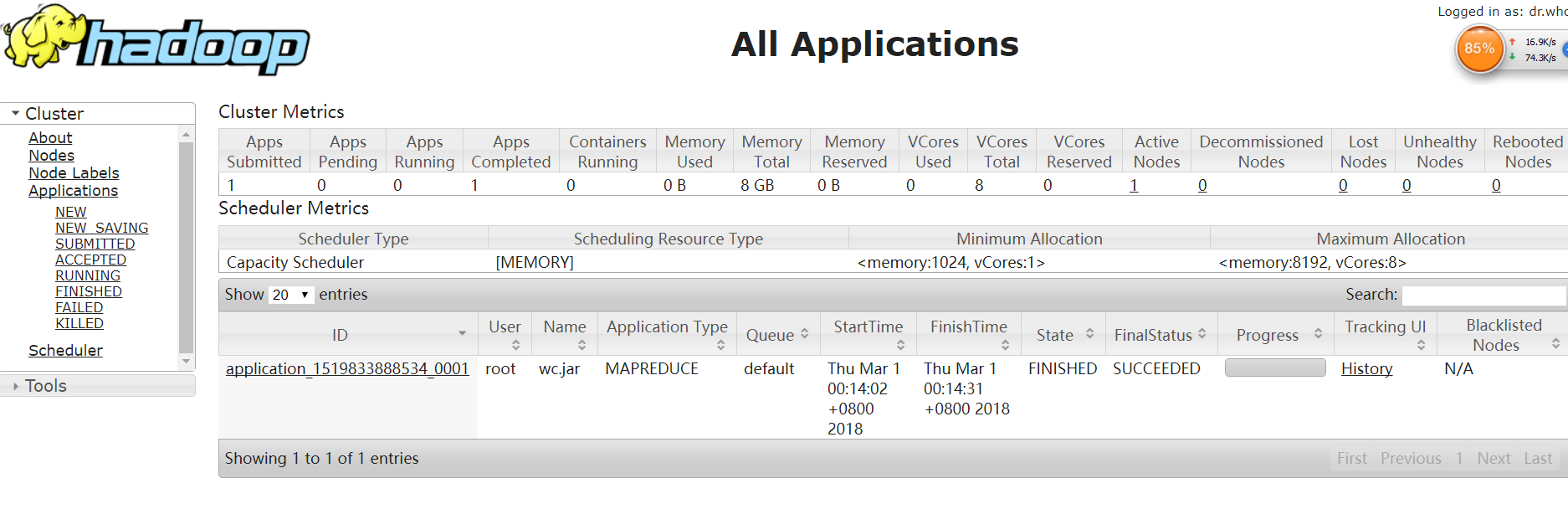
Web Console通过8088端口查看:
大数据笔记(七)——Mapreduce程序的开发的更多相关文章
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- 大数据笔记(十)——Shuffle与MapReduce编程案例(A)
一.什么是Shuffle yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle 因为mapreduce程序运 ...
- 大数据笔记(八)——Mapreduce的高级特性(A)
一.序列化 类似于Java的序列化:将对象——>文件 如果一个类实现了Serializable接口,这个类的对象就可以输出为文件 同理,如果一个类实现了的Hadoop的序列化机制(接口:Writ ...
- 基于Hbase数据的Mapreduce程序环境开发
一.实验目标 编写Mapreduce程序,以Hbase表数据为Map输入源,计算结果输出到HDFS或者Hbase表中. 在非CDH5的Hadoop集群环境中,将编写好的Mapreduce程序整个工程打 ...
- 大数据基础总结---MapReduce和YARN技术原理
Map Reduce和YARN技术原理 学习目标 熟悉MapReduce和YARN是什么 掌握MapReduce使用的场景及其原理 掌握MapReduce和YARN功能与架构 熟悉YARN的新特性 M ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
- 大数据IDEA调试flink程序
Flink在IDEA中开发是一件比较困难的事情,网上没有参考资料,就算就业说的太过笼统,不知道是会了不说还是不会瞎说,为了解决flink这个问题,本人特别做了一遍开发的简单说明.主要考虑两个问题,1. ...
随机推荐
- OI那些事——AFO
\(OI\)那些事--\(AFO\) 世界上从此少了一个\(Oier\)也不会有人知道,也许只有某个人在某年某月某日翻到了Eternal 风度的博客才会发现:哇,这哥们怎么\(Noip\)就退役了 两 ...
- Django中Model进阶操作
一.字段 AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列,必须填入参数 pr ...
- Consul服务发现在windows下简单使用
目录 基本介绍: 服务连接: 客户端: 系列章节: 回到顶部 基本介绍: 安装: 下载地址:https://www.consul.io/downloads.html 运行: consul agent ...
- 深入了解RabbitMQ工作原理及简单使用
深入了解RabbitMQ工作原理及简单使用 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchange介绍 ...
- scala学习笔记(7)
1.包 --------------------------------------- Scala中的包和Java或者C++中命名空间的目的是相同的:管理大型程序中的名称. package a{ pa ...
- UEditor使用报错Cannot set property 'innerHTML' of undefined
仿用UEditor的setContent的时候报错,报错代码如下Uncaught TypeError: Cannot set property ‘innerHTML’ of undefined.调试u ...
- nginx在windows下配置反向代理
转自:https://blog.csdn.net/comeonyangzi/article/details/72466310 下载地址:http://nginx.org/download/ 下载后直接 ...
- redHat 安装mono 错误
make[6]: * [do-install] Error 2 make[6]: Leaving directory /root/lindexi/mono-2.11.3/mcs/class/Syste ...
- Linux系统性能测试工具(七)——网络性能工具之iperf
本文介绍关于Linux系统(适用于centos/ubuntu等)的网络性能测试工具-iperf.磁盘io性能测试工具包括: iperf: netperf 参考链接:https://www.cnblog ...
- centos 7 安装 nginx 或 apache,及其比较
来自 知乎 陈湛翀 的回答:https://www.zhihu.com/question/19571087/answer/12313829 nginx 和 apache 比较 nginx 相对 apa ...