个推基于 Zipkin 的分布式链路追踪实践

作者:个推应用平台基础架构高级研发工程师 阿飞
• 开源,社区活跃
• 支持多种语言,Nodejs,Lua,Java都有开源实现,而我们的服务主要是这三种语言实现的
• 提供查询API,方便二次开发
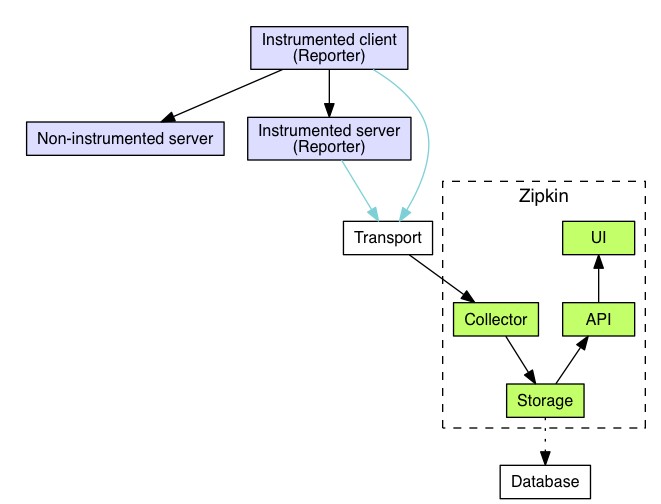
(引用自Zipkin官网:https://zipkin.io/pages/architecture.html)
其中:
• Instrumented client和Instrumented server需要集成在分布式系统的具体服务中,采集跟踪信息,调用Transport,把跟踪信息发送给Zipkin的Server。
• Transport是Zipkin对外提供的接口,支持HTTP、Kafka、Scribe等通信方式。
• Zipkin即Zipkin server,主要包括四个模块:
Collector: 用于接收各个应用服务传输的追踪信息;
Storage:Zipkin的后端存储,支持In-Memory、MySql、Elasticsearch和Cassandra;
API:提供对外的查询接口;
UI:提供对外的Web界面。
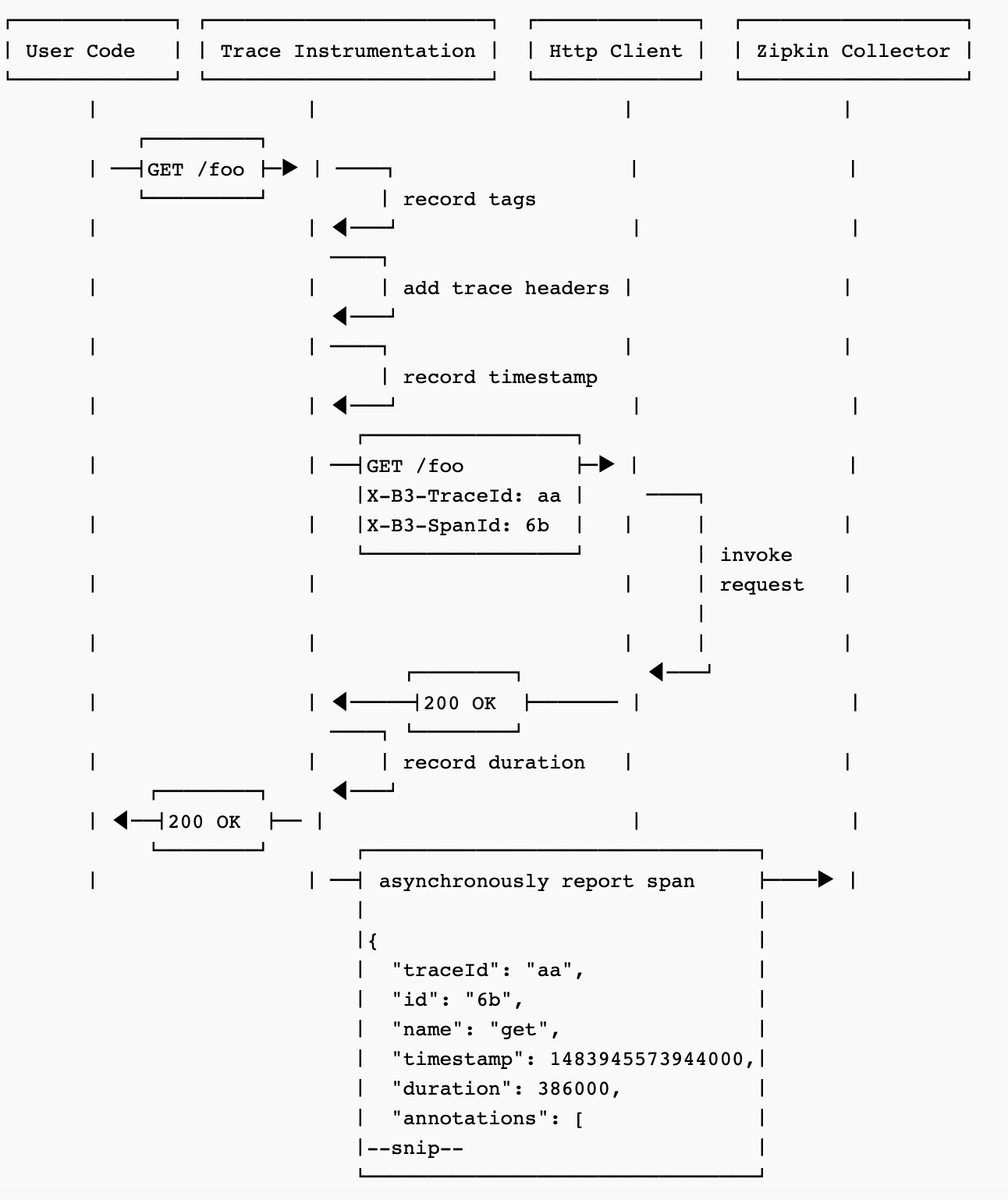
Http Tracing的时序图
(引用自Zipkin官网:https://zipkin.io/pages/architecture.html)
以上是Http Tracing的时序图,用户的请求/foo首先被Trace Instrumentationlan拦截,记录下Tags,时间戳,同时在Header里增加Trace信息,然后再流转到后端服务进行处理,处理完成后,正常响应,Trace Instrumentationlan拦截响应,记录处理延时后,将Response正常返回给调用方,同时异步地将Trace的Span发送给Zipkin Server。Span中的traceId是在整个调用链路上唯一的ID,用于唯一标识一条调用链。
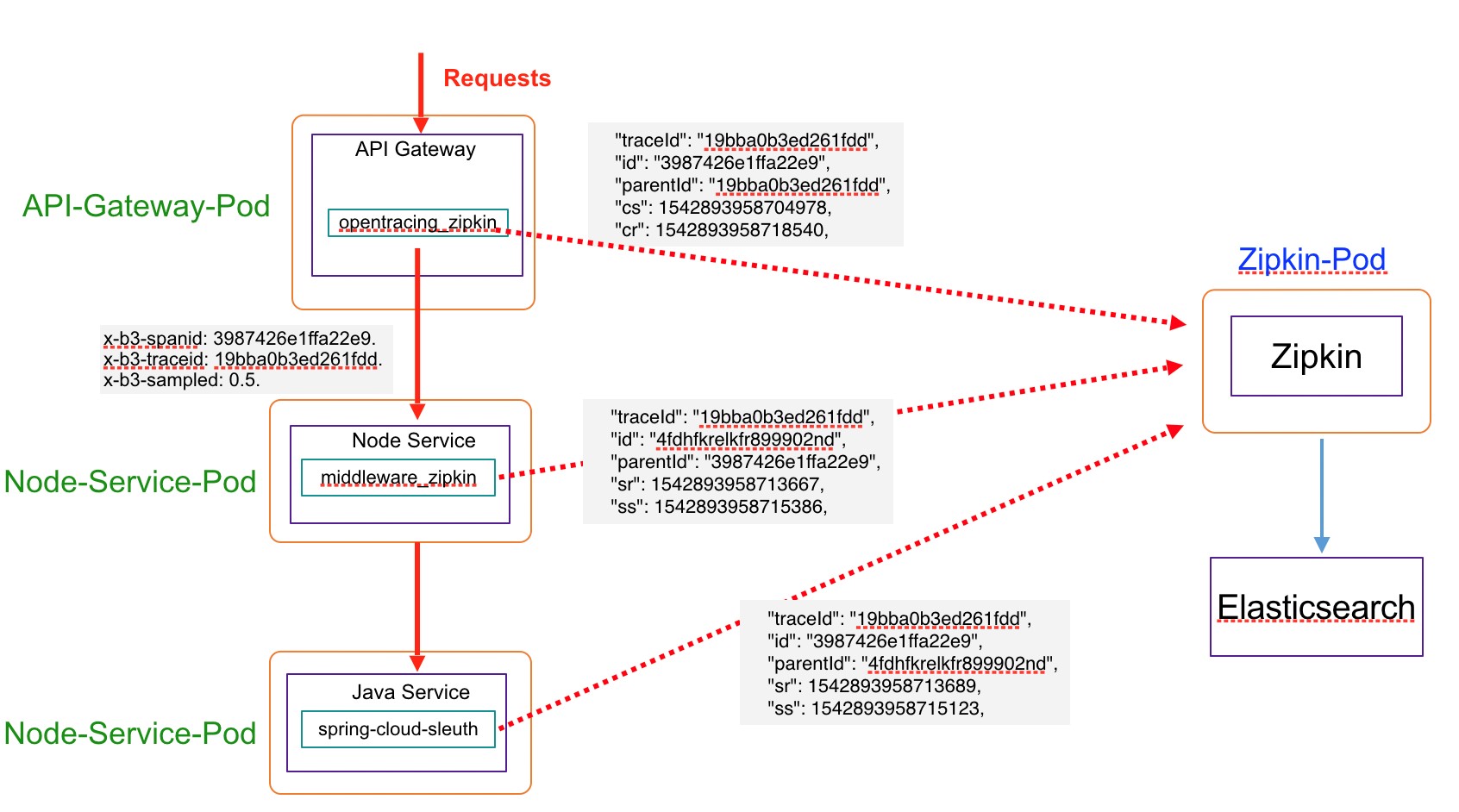
个推基于Zipkin的分布式链路追踪系统的整体架构
其中,Zipkin也容器化部署在Kubernetes集群中,简化了Zipkin的搭建和部署。如下图所示,通过Zipkin可以很方便地追踪请求的调用链路,整个调用链上各个服务的处理耗时,响应状态,服务间的调用关系都可以方便地在Zipkin中进行查询。Zipkin对于分析整个系统的性能瓶颈,定位故障也都有很大的帮助。
Zipkin的Web界面
个推基于 Zipkin 的分布式链路追踪实践的更多相关文章
- Laravel + go-micro + grpc 实践基于 Zipkin 的分布式链路追踪系统 摘自https://mp.weixin.qq.com/s/JkLMNabnYbod-b4syMB3Hw?
分布式调用链跟踪系统,属于监控系统的一类.系统架构逐步演进时,后期形态往往是一个平台由很多不同的服务.组件构成,用户请求过来后,可能会经过其中多个服务,如图 不过,出问题时往往很难排查,如整个请求变慢 ...
- 基于Dapper的分布式链路追踪入门——Opencensus+Zipkin+Jaeger
微信搜索公众号 「程序员白泽」,进入白泽的编程知识分享星球 最近做了一些分布式链路追踪有关的东西,写篇文章来梳理一下思路,或许可以帮到想入门的同学.下面我将从原理到demo为大家一一进行讲解,欢迎评论 ...
- Net和Java基于zipkin的全链路追踪
在各大厂分布式链路跟踪系统架构对比 中已经介绍了几大框架的对比,如果想用免费的可以用zipkin和pinpoint还有一个忘了介绍:SkyWalking,具体介绍可参考:https://github. ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
- 分布式链路追踪之Spring Cloud Sleuth+Zipkin最全教程!
大家好,我是不才陈某~ 这是<Spring Cloud 进阶>第九篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得 ...
- 带入gRPC:分布式链路追踪 gRPC + Opentracing + Zipkin
在实际应用中,你做了那么多 Server 端,写了 N 个 RPC 方法.想看看方法的指标,却无处下手? 本文将通过 gRPC + Opentracing + Zipkin 搭建一个分布式链路追踪系统 ...
随机推荐
- 100+ Python挑战性编程练习(2)
熟能生巧,多撸代码多读书 https://github.com/zhiwehu/Python-programming-exercises/blob/master/100+%20Python%20cha ...
- Docker之单多/机容器管理
Compose是用于定义和运行多容器Docker应用程序的工具.通过Compose,您可以使用YAML文件来配置应用程序的服务.然后,使用一个命令,就可以从配置中创建并启动所有服务. Docker-C ...
- 如何在ubuntu上安装 搜狗输入法(已经成功)
转自:https://blog.csdn.net/qq_37589838/article/details/81208409 本文链接:https://blog.csdn.net/qq_37589838 ...
- PCIeのType0与Type1型配置请求与BAR(基地址寄存器)
PCIe中存在两种配置空间Type0&type1,TYPE0对应非桥设备(Endpoint),Type1对应桥设备(Root和Switch端口中的P2P桥)因为Root每个端口总都含有一个P2 ...
- ECMAScript 6 学习笔记(一)
ECMAScript 6简介 ECMAScript 6.0(以下简称ES6)是JavaScript语言的下一代标准,已经在2015年6月正式发布了.它的目标,是使得JavaScript语言可以用来编写 ...
- k3 cloud的单据存储在业务对象表中
k3 cloud的单据存储在业务对象表中,表名为T_META_OBJECTTYPE,查询表名和对应的表: select FNAME,FBASEOBJECTID from T_META_OBJECTTY ...
- css厂商前缀
在vue中写css,不要加厂商前缀,vue-cli会在打包时自动生成
- Pygame播放背景音乐与音效
1.播放背景音乐 pygame.mixer.music.load() 加载MP3格式 加入pygame.mixer.init()即可 第十一行第一个参数:播放次数(n>0),n=0时播放1次,- ...
- Python RSA操作
公钥加密.私钥解密 # -*- coding: utf-8 -*- import rsa # rsa加密 def rsaEncrypt(str): # 生成公钥.私钥 (pubkey, privkey ...
- Python自动化学习--异常提示
举例:打开一个不存在的文件时: >>open("abc.txt","r")会提示错误 Traceback (most recent call las ...