简单谈谈Netty的高性能之道
传统RPC 调用性能差的三宗罪
网络传输方式问题:传统的RPC 框架或者基于RMI 等方式的远程服务(过程)调用采用了同步阻塞IO,当客户端的并发压力或者网络时延增大之后,同步阻塞IO 会由于频繁的wait 导致IO 线程经常性的阻塞,由于线程无法高效的工作,IO 处理能力自然下降。下面,我们通过BIO 通信模型图看下BIO 通信的弊端:
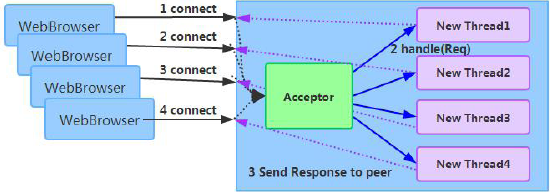
采用BIO 通信模型的服务端,通常由一个独立的Acceptor 线程负责监听客户端的连接,接收到客户端连接之后为客户端连接创建一个新的线程处理请求消息,处理完成之后,返回应答消息给客户端,线程销毁,这就是典型的一请求一应答模型。该架构最大的问题就是不具备弹性伸缩能力,当并发访问量增加后,服务端的线程个数和并发访问数成线性正比,由于线程是JAVA 虚拟机非常宝贵的系统资源,当线程数膨胀之后,系统的性能急剧下降,随着并发量的继续增加,可能会发生句柄溢出、线程堆栈溢出等问题,并导致服务器最终宕机。
序列化方式问题:Java 序列化存在如下几个典型问题:
- Java 序列化机制是Java 内部的一种对象编解码技术,无法跨语言使用;例如对于异构系统之间的对接,Java 序列化后的码流需要能够通过其它语言反序列化成原始对象(副本),目前很难支持;
- 相比于其它开源的序列化框架,Java 序列化后的码流太大,无论是网络传输还是持久化到磁盘,都会导致额外的资源占用;
- 序列化性能差(CPU 资源占用高)。
线程模型问题:由于采用同步阻塞IO,这会导致每个TCP 连接都占用1 个线程,由于线程资源是JVM 虚拟机非常宝贵的资源,当IO 读写阻塞导致线程无法及时释放时,会导致系统性能急剧下降,严重的甚至会导致虚拟机无法创建新的线程。
高性能的三个主题:
- 传输:用什么样的通道将数据发送给对方,BIO、NIO 或者AIO,IO 模型在很大程度上决定了框架的性能。
- 协议:采用什么样的通信协议,HTTP 或者内部私有协议。协议的选择不同,性能模型也不同。相比于公有协议,内部私有协议的性能通常可以被设计的更优。
- 线程:数据报如何读取?读取之后的编解码在哪个线程进行,编解码后的消息如何派发,Reactor 线程模型的不同,对性能的影响也非常大。
Netty 惊人的性能数据:
通过使用Netty(NIO 框架)相比于传统基于Java 序列化+BIO(同步阻塞IO)的通信框架,性能提升了8 倍多。通过选择合适的NIO 框架,精心的设计Reactor 线程模型,达到上述性能指标是完全有可能的。
1.异步非阻塞通信:
在IO 编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者IO 多路复用技术进行处理。IO 多路复用技术通过把多个IO 的阻塞复用到同一个select 的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O 多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程的运行,降低了系统的维护工作量,节省了系统资源。JDK1.4 提供了对非阻塞IO(NIO)的支持,JDK1.5_update10 版本使用epoll 替代了传统的select/poll,极大的提升了NIO 通信的性能。JDK NIO 通信模型如下所示:
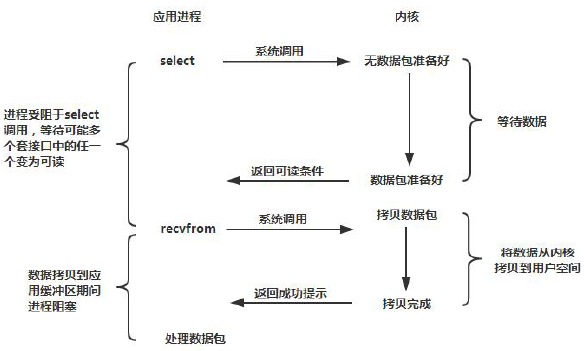
与Socket 类和ServerSocket 类相对应,NIO 也提供了SocketChannel 和ServerSocketChannel 两种不同的套接字通道实现。这两种新增的通道都支持阻塞和非阻塞两种模式。阻塞模式使用非常简单,但是性能和可靠性都不好,非阻塞模式正好相反。开发人员一般可以根据自己的需要来选择合适的模式,一般来说,低负载、低并发的应用程序可以选择同步阻塞IO 以降低编程复杂度。但是对于高负载、高并发的网络应用,需要使用NIO 的非阻塞模式进行开发。Netty 架构按照Reactor 模式设计和实现。
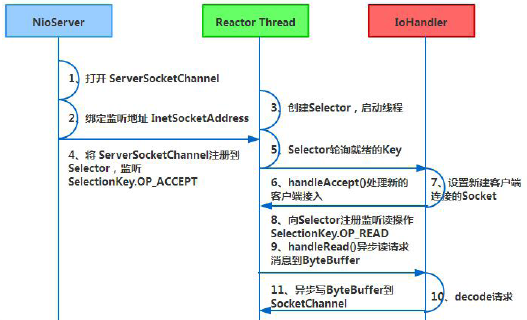
它的服务端通信序列图如下:
客户端通信序列图如下:
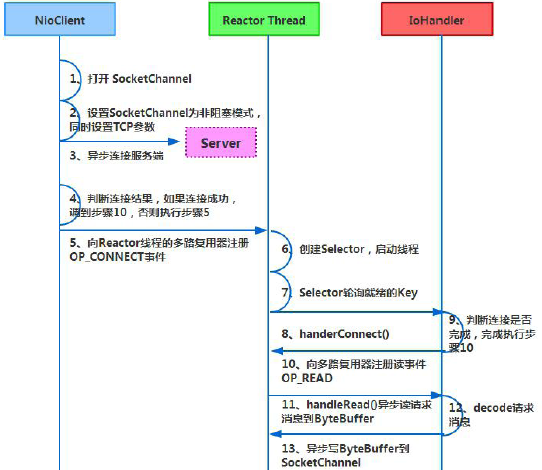
Netty 的IO 线程NioEventLoop 聚合了多路复用器Selector,可以同时并发处理成百上千个客户端Channel,由于读写操作都是非阻塞的,这就可以充分提升IO 线程的运行效率,避免由于频繁IO 阻塞导致的线程挂起。另外,由于Netty采用了异步通信模式,一个IO 线程可以并发处理N 个客户端连接和读写操作,这从根本上解决了传统同步阻塞IO 一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。
2.零拷贝
Netty 的“零拷贝”主要体现在如下三个方面:
- 1) Netty 的接收和发送ByteBuffer 采用DIRECT BUFFERS,使用堆外直接内存进行Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行Socket 读写,JVM 会将堆内存Buffer 拷贝一份到直接内存中,然后才写入Socket 中。相比于堆 外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。当进行Socket IO 读写的时候,为了避免从堆内存拷贝一份副本到直接内存,Netty 的ByteBuf 分配器直接创建非堆内存避免缓冲区的二次拷贝,通过“零拷贝”来提升读写性能。
- 2) Netty 提供了组合Buffer 对象,可以聚合多个ByteBuffer 对象,用户可以像操作一个Buffer 那样方便的对组合Buffer进行操作,避免了传统通过内存拷贝的方式将几个小Buffer 合并成一个大的Buffer。
- 3) Netty 的文件传输采用了transferTo()方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write()方式导致的内存拷贝问题。对于很多操作系统它直接将文件缓冲区的内容发送到目标Channel 中,而不需要通过拷贝的方式,这是一种更加高效的传输方式,它实现了文件传输的“零拷贝”
3.内存池
三个维度:
- Pooled与UnPooled(池化与非池化)
- UnSafe和非UnSafe(底层读写与应用程序读写)
- Heap和Direct(堆内存与堆外内存)
随着JVM 虚拟机和JIT 即时编译技术的发展,对象的分配和回收是个非常轻量级的工作。但是对于缓冲区Buffer,情况却稍有不同,特别是对于堆外直接内存的分配和回收,是一件耗时的操作。为了尽量重用缓冲区,Netty 提供了基于内存池的缓冲区重用机制。下面我们一起看下Netty ByteBuf 的实现:
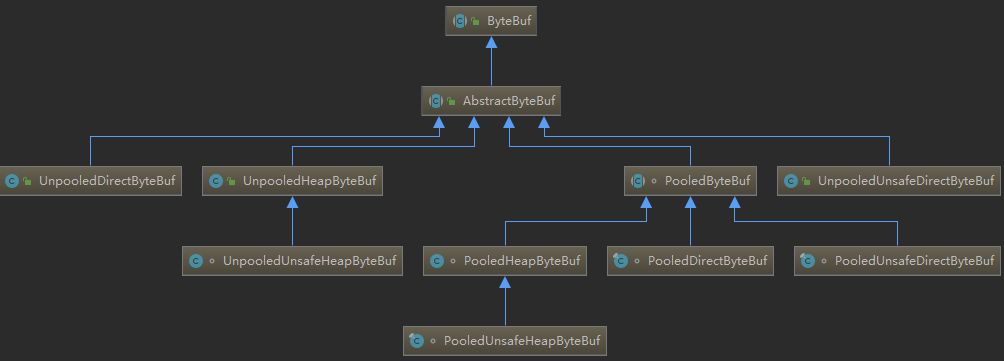
Netty 提供了多种内存管理策略,通过在启动辅助类中配置相关参数,可以实现差异化的定制。下面通过性能测试,我们看下基于内存池循环利用的ByteBuf 和普通ByteBuf 的性能差异。
用例一,使用内存池分配器创建直接内存缓冲区:
final byte[] CONTENT = new byte[];
int loop = ;
long startTime = System.currentTimeMillis();
ByteBuf poolBuffer = null;
for (int i = ; i < loop; i++) {
poolBuffer = PooledByteBufAllocator.DEFAULT.directBuffer();
poolBuffer.writeBytes(CONTENT);
poolBuffer.release();
}
long endTime = System.currentTimeMillis();
System.out.println("内存池分配缓冲区耗时" + (endTime - startTime) + "ms.");
用例二,使用非堆内存分配器创建的直接内存缓冲区:
long startTime2 = System.currentTimeMillis();
ByteBuf buffer = null;
for (int i = ; i < loop; i++) {
buffer = Unpooled.directBuffer();
buffer.writeBytes(CONTENT);
buffer.release();
}
endTime = System.currentTimeMillis();
System.out.println("非内存池分配缓冲区耗时" + (endTime - startTime2) + "ms.");
性能测试经验表明,采用内存池的ByteBuf 相比于朝生夕灭的ByteBuf,性能高了不少(性能数据与使用场景强相关)。下面我们一起简单分析下Netty 内存池的内存分配:
public ByteBuf directBuffer(int initialCapacity, int maxCapacity) {
if (initialCapacity == && maxCapacity == ) {
return this.emptyBuf;
} else {
validate(initialCapacity, maxCapacity);
return this.newDirectBuffer(initialCapacity, maxCapacity);
}
}
继续看newDirectBuffer 方法,我们发现它是一个抽象方法,由AbstractByteBufAllocator 的子类负责具体实现,代码如下:

代码跳转到PooledByteBufAllocator 的newDirectBuffer 方法,从Cache 中获取内存区域PoolArena,调用它的allocate方法进行内存分配:
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = (PoolThreadCache)this.threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
Object buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ? UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) : new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer((ByteBuf)buf);
}
PoolArena 的allocate 方法如下:
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
PooledByteBuf<T> buf = this.newByteBuf(maxCapacity);
this.allocate(cache, buf, reqCapacity);
return buf;
}
我们重点看newByteBuf 的实现,它同样是个抽象方法:
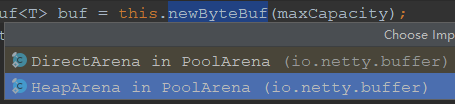
由子类DirectArena 和HeapArena 来实现不同类型的缓冲区分配,由于测试用例使用的是堆外内存,因此重点分析DirectArena 的实现:如果没有开启使用sun 的unsafe:
protected PooledByteBuf<ByteBuffer> newByteBuf(int maxCapacity) {
return (PooledByteBuf)(HAS_UNSAFE ? PooledUnsafeDirectByteBuf.newInstance(maxCapacity) : PooledDirectByteBuf.newInstance(maxCapacity));
}
则执行PooledDirectByteBuf 的newInstance 方法,代码如下:
static PooledDirectByteBuf newInstance(int maxCapacity) {
PooledDirectByteBuf buf = (PooledDirectByteBuf)RECYCLER.get();
buf.reuse(maxCapacity);
return buf;
}
通过RECYCLER 的get 方法循环使用ByteBuf 对象,如果是非内存池实现,则直接创建一个新的ByteBuf 对象。从缓冲池中获取ByteBuf 之后,调用AbstractReferenceCountedByteBuf 的setRefCnt 方法设置引用计数器,用于对象的引用计数和内存回收(类似JVM 垃圾回收机制)。而 Unpooled.directBuffer(1024) 则是每次都要new
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
4.高效的Reactor 线程模型
常用的Reactor 线程模型有三种,分别如下:
Reactor 单线程模型;
Reactor 多线程模型;
主从Reactor 多线程模型
Reactor 单线程模型,指的是所有的IO 操作都在同一个NIO 线程上面完成,NIO 线程的职责如下:
- 作为NIO 服务端,接收客户端的TCP 连接;
- 作为NIO 客户端,向服务端发起TCP 连接;
- 读取通信对端的请求或者应答消息;
- 向通信对端发送消息请求或者应答消息。
Reactor 单线程模型示意图如下所示:
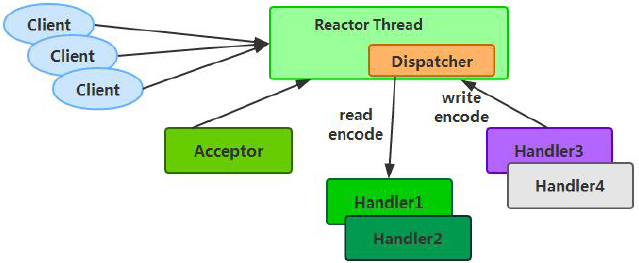
由于Reactor 模式使用的是异步非阻塞IO,所有的IO 操作都不会导致阻塞,理论上一个线程可以独立处理所有IO 相关的操作。从架构层面看,一个NIO 线程确实可以完成其承担的职责。例如,通过Acceptor 接收客户端的TCP 连接请求消息,链路建立成功之后,通过Dispatch 将对应的ByteBuffer 派发到指定的Handler 上进行消息解码。用户Handler可以通过NIO 线程将消息发送给客户端。对于一些小容量应用场景,可以使用单线程模型。但是对于高负载、大并发的应用却不合适,主要原因如下:
- 一个NIO 线程同时处理成百上千的链路,性能上无法支撑,即便NIO 线程的CPU 负荷达到100%,也无法满足海量消息的编码、解码、读取和发送;
- 当NIO 线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了NIO 线程的负载,最终会导致大量消息积压和处理超时,NIO 线程会成为系统的性能瓶颈;
- 可靠性问题:一旦NIO 线程意外跑飞,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
为了解决这些问题,演进出了Reactor 多线程模型,下面我们一起学习下Reactor 多线程模型。Rector 多线程模型与单线程模型最大的区别就是有一组NIO 线程处理IO 操作,它的原理图如下:

Reactor 多线程模型的特点:
- 有专门一个NIO 线程-Acceptor 线程用于监听服务端,接收客户端的TCP 连接请求;
- 网络IO 操作-读、写等由一个NIO 线程池负责,线程池可以采用标准的JDK 线程池实现,它包含一个任务队列和N个可用的线程,由这些NIO 线程负责消息的读取、解码、编码和发送;
- 1 个NIO 线程可以同时处理N 条链路,但是1 个链路只对应1 个NIO 线程,防止发生并发操作问题。
在绝大多数场景下,Reactor 多线程模型都可以满足性能需求;但是,在极特殊应用场景中,一个NIO 线程负责监听和处理所有的客户端连接可能会存在性能问题。例如百万客户端并发连接,或者服务端需要对客户端的握手消息进行安全认证,认证本身非常损耗性能。在这类场景下,单独一个Acceptor 线程可能会存在性能不足问题,为了解决性能问题,产生了第三种Reactor 线程模型-主从Reactor 多线程模型。
主从Reactor 线程模型的特点是:
服务端用于接收客户端连接的不再是个1 个单独的NIO 线程,而是一个独立的NIO线程池。Acceptor 接收到客户端TCP 连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel 注册到IO 线程池(sub reactor 线程池)的某个IO 线程上,由它负责SocketChannel 的读写和编解码工作。Acceptor线程池仅仅只用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor 线程池的IO线程上,由IO 线程负责后续的IO 操作。它的线程模型如下图所示:
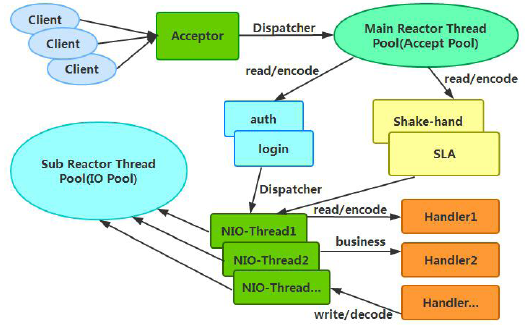
利用主从NIO 线程模型,可以解决1 个服务端监听线程无法有效处理所有客户端连接的性能不足问题。因此,在Netty的官方demo 中,推荐使用该线程模型。事实上,Netty 的线程模型并非固定不变,通过在启动辅助类中创建不同的EventLoopGroup 实例并通过适当的参数配置,就可以支持上述三种Reactor 线程模型。正是因为Netty 对Reactor 线程模型的支持提供了灵活的定制能力,所以可以满足不同业务场景的性能诉求。
5.无锁化的串行设计理念
在大多数场景下,并行多线程处理可以提升系统的并发性能。但是,如果对于共享资源的并发访问处理不当,会带来严重的锁竞争,这最终会导致性能的下降。为了尽可能的避免锁竞争带来的性能损耗,可以通过串行化设计,即消息的处理尽可能在同一个线程内完成,期间不进行线程切换,这样就避免了多线程竞争和同步锁。
为了尽可能提升性能,Netty 采用了串行无锁化设计,在IO 线程内部进行串行操作,避免多线程竞争导致的性能下降。表面上看,串行化设计似乎CPU 利用率不高,并发程度不够。但是,通过调整NIO 线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。Netty 的串行化设计工作原理图如下:
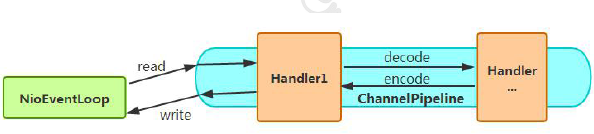
Netty 的NioEventLoop 读取到消息之后,直接调用ChannelPipeline 的fireChannelRead(Object msg),只要用户不主动切换线程,一直会由NioEventLoop 调用到用户的Handler,期间不进行线程切换,这种串行化处理方式避免了多线程操作导致的锁的竞争,从性能角度看是最优的。
6.高效的并发编程
Netty 的高效并发编程主要体现在如下几点:
- volatile 的大量、正确使用;
- CAS 和原子类的广泛使用;
- 线程安全容器的使用;
- 通过读写锁提升并发性能。
7.高性能的序列化框架
影响序列化性能的关键因素总结如下:
- 序列化后的码流大小(网络带宽的占用);
- 序列化&反序列化的性能(CPU 资源占用);
- 是否支持跨语言(异构系统的对接和开发语言切换)。
Netty 默认提供了对Google Protobuf 的支持,通过扩展Netty 的编解码接口,用户可以实现其它的高性能序列化框架,例如Thrift 的压缩二进制编解码框架。下面我们一起看下不同序列化&反序列化框架序列化后的字节数组对比:
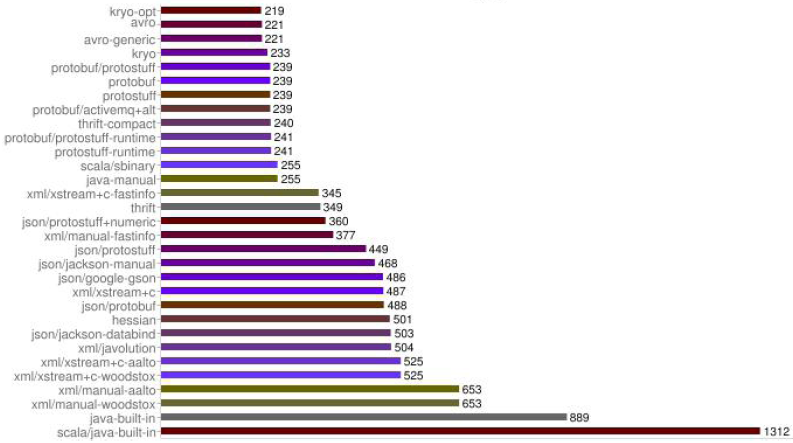
从上图可以看出,Protobuf 序列化后的码流只有Java 序列化的1/4 左右。正是由于Java 原生序列化性能表现太差,才催生出了各种高性能的开源序列化技术和框架(性能差只是其中的一个原因,还有跨语言、IDL 定义等其它因素)。
8.灵活的TCP 参数配置能力
合理设置TCP 参数在某些场景下对于性能的提升可以起到显著的效果,例如SO_RCVBUF 和SO_SNDBUF。如果设置不当,对性能的影响是非常大的。下面我们总结下对性能影响比较大的几个配置项:
- SO_RCVBUF 和SO_SNDBUF:通常建议值为128K 或者256K;
- SO_TCPNODELAY:NAGLE 算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算法;
- 软中断:如果Linux 内核版本支持RPS(2.6.35 以上版本),开启RPS 后可以实现软中断,提升网络吞吐量。RPS根据数据包的源地址,目的地址以及目的和源端口,计算出一个hash 值,然后根据这个hash 值来选择软中断运行的cpu,从上层来看,也就是说将每个连接和cpu 绑定,并通过这个hash 值,来均衡软中断在多个cpu 上,提升网络并行处理性能。
Netty 在启动辅助类中可以灵活的配置TCP 参数,满足不同的用户场景。相关配置接口定义如下:
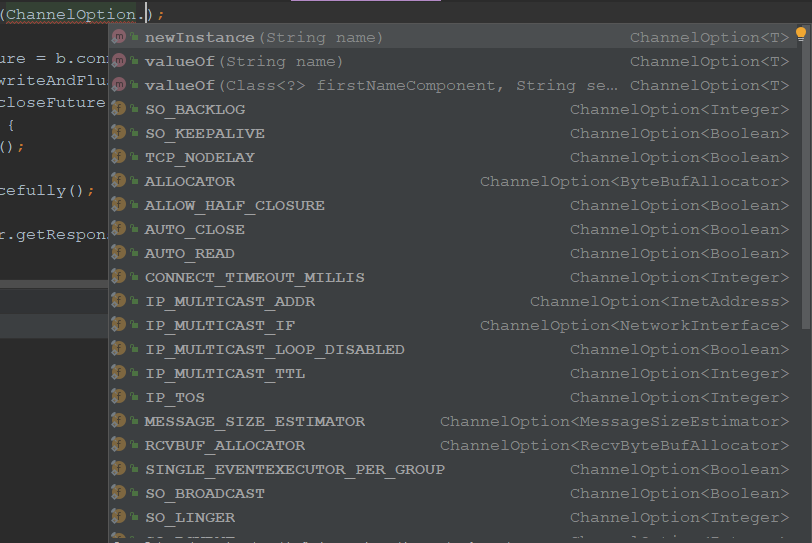
基本上对于Netty的高性能是由以上主要的八点所共同支撑的。
简单谈谈Netty的高性能之道的更多相关文章
- Netty(RPC高性能之道)原理剖析
1,Netty简述 Netty 是一个基于 JAVA NIO 类库的异步通信框架,用于创建异步非阻塞.基于事件驱动.高性能.高可靠性和高可定制性的网络客户端和服务器端 RPC高性能分析,请参考文章“[ ...
- 一篇文章,读懂 Netty 的高性能架构之道
原文 Netty是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机 ...
- Netty 系列之 Netty 高性能之道
1. 背景 1.1. 惊人的性能数据 最近一个圈内朋友通过私信告诉我,通过使用 Netty4 + Thrift 压缩二进制编解码技术,他们实现了 10 W TPS(1 K 的复杂 POJO 对象)的跨 ...
- Netty系列之Netty高性能之道
转载自http://www.infoq.com/cn/articles/netty-high-performance 1. 背景 1.1. 惊人的性能数据 最近一个圈内朋友通过私信告诉我,通过使用Ne ...
- Netty高性能之道
1. 背景 1.1. 惊人的性能数据 最近一个圈内朋友告诉我,通过使用Netty4 + Thrift压缩二进制编解码技术,他们实现了10W TPS(1K的复杂POJO对象)的跨节点远程服务调用.相比于 ...
- 转:Netty系列之Netty高性能之道
1. 背景 1.1. 惊人的性能数据 最近一个圈内朋友通过私信告诉我,通过使用Netty4 + Thrift压缩二进制编解码技术,他们实现了10W TPS(1K的复杂POJO对象)的跨节点远程服务调用 ...
- Netty(RPC高性能之道)原理剖析
转载:http://blog.csdn.net/zhiguozhu/article/details/50517551 1,Netty简述 Netty 是一个基于 JAVA NIO 类库的异步通信框架, ...
- 一篇文章,读懂Netty的高性能架构之道
一篇文章,读懂Netty的高性能架构之道 Netty是由JBOSS提供的一个java开源框架,是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架, ...
- 读懂Netty的高性能架构之道
Netty是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机制,用 ...
随机推荐
- VMware Workstation安装CentOs7固定ip地址
今天发现之前hypervisor配置的CentOs7连接不了了,该死的加密系统和杀毒软件又搞事情了,于是决定试下VMware虚拟机,下载安装后,发现可以连上CentOS7界面,很开心,于是决定把之前的 ...
- Informatica ODBC的使用
1.在服务器端配置odbc.ini 注意:添加环境变量才能生效 2.测试连通性 3.使用
- 五、Ubuntu 16.04 安装PyCharm
方法一,在终端用指令通过第三方源安装pycharm. 本文通过第三方源安装PyCharm,好处是升级方便. 添加源: $ sudo add-apt-repository ppa:mystic-m ...
- 【LGR-062】洛谷10月月赛 III div.2 (A-C)
前言 100+100+46+0=246pts 300多名 以后每次比赛都要有进步哦!qwq 小D与笔试 水题 Code #include<algorithm> #include<io ...
- [洛谷 P1013] NOIP1998 提高组 进制位
问题描述 著名科学家卢斯为了检查学生对进位制的理解,他给出了如下的一张加法表,表中的字母代表数字. 例如: L K V E L L K V E K K V E KL V V E KL KK E E K ...
- php range()函数 语法
php range()函数 语法 作用:创建一个包含指定范围的元素的数组.dd马达哪家好 语法:range(low,high,step) 参数: 参数 描述 low 必需.规定数组的最低值. hig ...
- [CF846B]Math Show题解
暴力一下就好啦! 枚举一下一共做多少次任务,剩下的时间将子任务排序,从头开始能取多少取多少就行了. 贴个代码 #include <cstdio> #include <algorith ...
- 二叉搜索树第k个节点
/* struct TreeNode { int val; struct TreeNode *left; struct TreeNode *right; TreeNode(int x) : val(x ...
- linux的shell脚本运行python程序
可以说和windows里的bat是一样的. python3 /opt/pyweibo/get_user_info.py 104501 104502 104503
- drawChild中画阴影,裁剪出圆角
我们在EasyConstraintLayout中初始化paint,并且关闭硬件加速,然后在drawChild中实现阴影逻辑,最终代码如下. public class EasyConstraintLay ...