R_Studio(学生成绩)使用cbind()函数对多个学期成绩进行集成
“Gary1.csv”、“Gary2.csv”、“Gary3.csv”中保存了一个班级学生三个学期的成绩
对三个学期中的成绩数据进行集成并重新计算综合成绩和排名,并按排名顺序排布(学号9位数111304001~11304047)
Gary1.csv中数据

Gary2.csv中数据
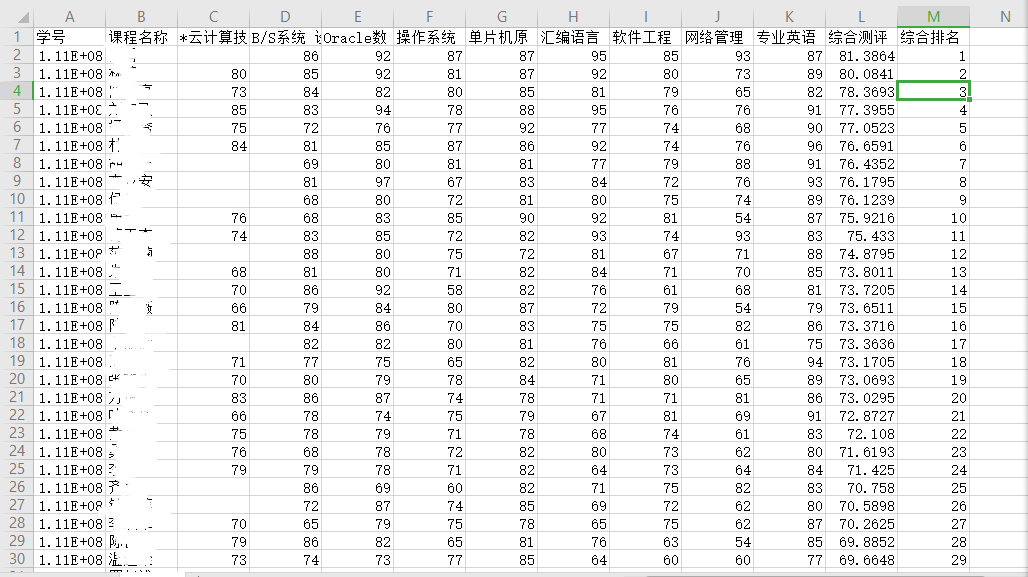
Gary3.csv中数据
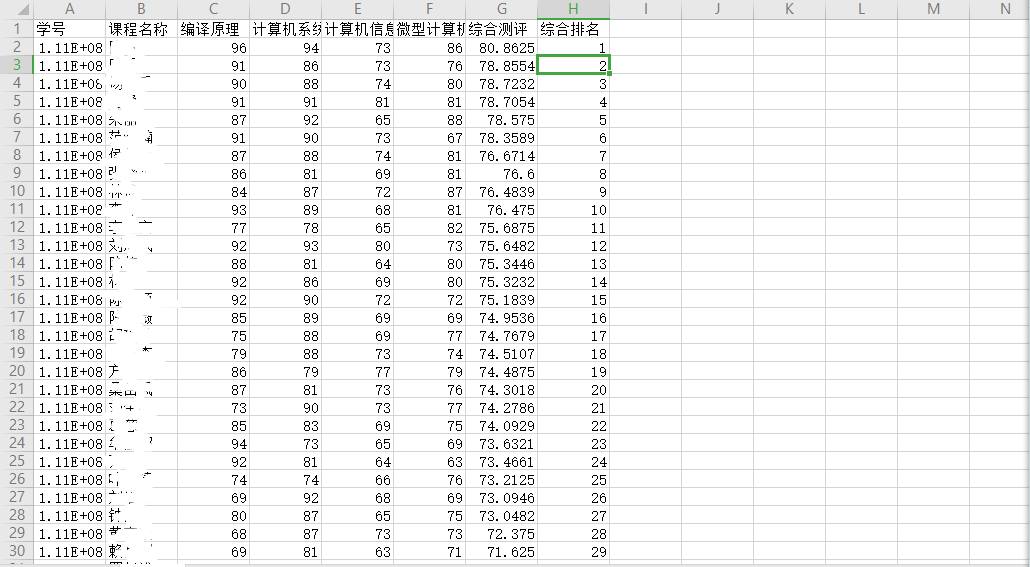
cbind是根据列进行合并 (要求:所有数据行数相等)
rbind是根据行进行合并 (要求:所有数据列数相同)

#打开工作目录文件
setwd('D:\\data') list.files() inputfile1=read.csv(file="Gary1.csv",header=TRUE)
inputfile2=read.csv(file="Gary2.csv",header=TRUE)
inputfile3=read.csv(file="Gary3.csv",header=TRUE) #删除inputfile1中的综合成绩和排名,删除inputfile2中的学号、姓名、综合成绩和排名
result=cbind(inputfile1[,-c(,)],inputfile2[,-c(,,,)]) #数据集列合并 #同理
result2=cbind(result,inputfile3[,-c(,,,)]) #对学生成绩进行相加,得到一组数据(我自己测试学生成绩是从第三列到第二十二列的)
#相加成绩保存到evaluation中
evaluation=apply(result2[,:], ,mean,na.rm=TRUE) #apply函数一般有三个参数
#第一个参数代表矩阵对象
#第二个参数代表要操作矩阵的维度 1表示对行进行处理,2表示对列进行处理
#第三个参数就是处理数据的函数
#apply会分别一行或一列处理该矩阵的数据。 #将evaluation用“综合测评”添加到resule2中,将结果用result11保存
result11=data.frame(result2,'综合测评'=evaluation) #对result11中按综合测评成绩进行decreasing减少量排名
result22=result11[order(result11$综合测评,decreasing = TRUE), ] result33=data.frame(result22,'测评排名'=order(result22$综合测评,decreasing = TRUE)) result33
Gary.R
实现过程
apply函数三个参数:
第一个参数代表矩阵对象
第二个参数代表要操作矩阵的维度 1表示对行进行处理,2表示对列进行处理
第三个参数就是处理数据的函数
读取文件数据保存到inputfile中
inputfile1=read.csv(file="Gary1.csv",header=TRUE)
inputfile2=read.csv(file="Gary2.csv",header=TRUE)
inputfile3=read.csv(file="Gary3.csv",header=TRUE)
删除inputfile1中的综合成绩和排名,删除inputfile2,inputfuke3中的学号、姓名、综合成绩和排名(合并数据后这些数据多余了)
result=cbind(inputfile1[,-c(,)],inputfile2[,-c(,,,)]) #数据集列合并 result2=cbind(result,inputfile3[,-c(,,,)])
计算学生成绩并将所得结果添加到学生表中
evaluation=apply(result2[,3:22], 1,mean,na.rm=TRUE) #将evaluation用“综合测评”添加到resule2中,将结果用result11保存
result11=data.frame(result2,'综合测评'=evaluation) #对result11中按综合测评成绩进行decreasing减少量排名
result22=result11[order(result11$综合测评,decreasing = TRUE), ] result33=data.frame(result22,'测评排名'=order(result22$综合测评,decreasing = TRUE)) result33
当R数据中存在NA时,使用对数据的mean()函数时需要注意NA问题
y<-mean(x)
对学生成绩异常值检测 传送门
修改上列代码28行
evaluation=apply(result2[,3:22], 1,mean)

补充:merge()函数 传送门
merge 连接两个数据,官方参考文档语法
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"),
incomparables = NULL, ...)
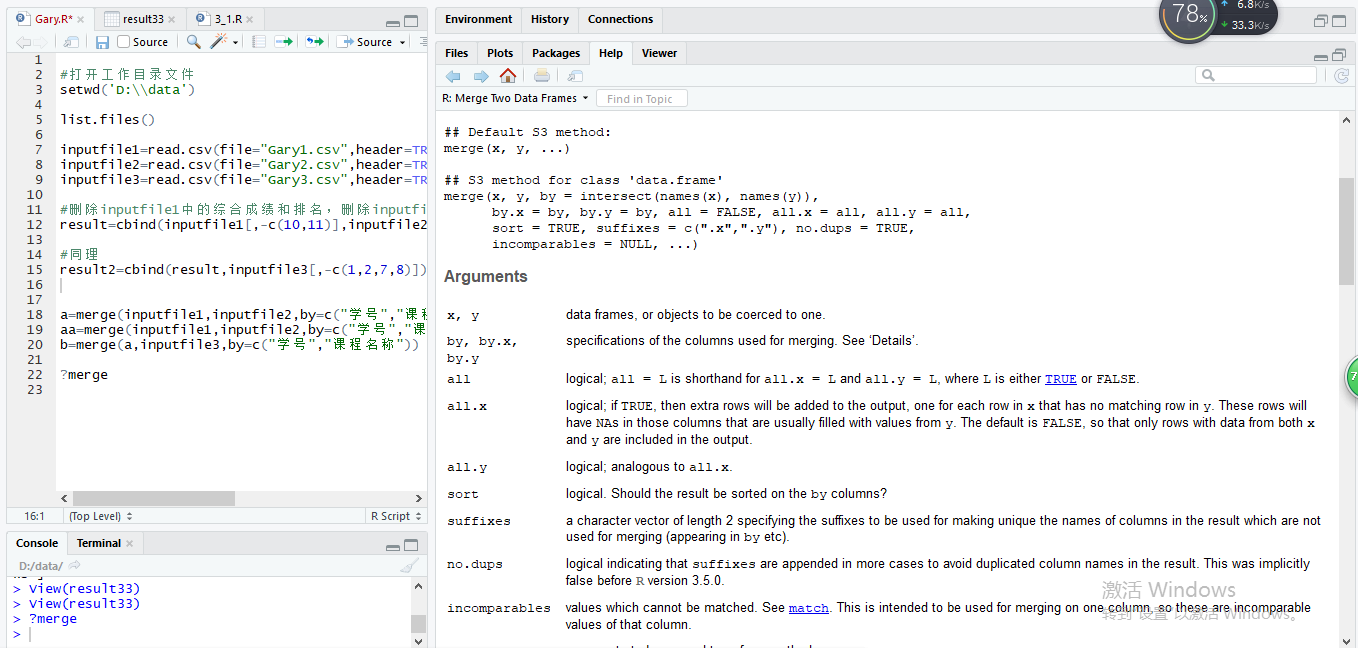
merge()函数是对数据进行交并补运算,三张表进行数据合并时可先合并第一第二张表,再用所合成结果对第三张表进行合成
测试a和aa中值的不同
setwd('D:\\data')
list.files()
inputfile1=read.csv(file="Gary1.csv",header=TRUE)
inputfile2=read.csv(file="Gary2.csv",header=TRUE)
inputfile3=read.csv(file="Gary3.csv",header=TRUE)
#删除inputfile1中的综合成绩和排名,删除inputfile2中的学号、姓名、综合成绩和排名
result=cbind(inputfile1[,-c(10,11)],inputfile2[,-c(1,2,12,13)]) #数据集列合并
#同理
result2=cbind(result,inputfile3[,-c(1,2,7,8)])
a=merge(inputfile1,inputfile2,by=c("学号","课程名称"))
aa=merge(inputfile1,inputfile2,by=c("学号","课程名称","综合排名"))
b=merge(a,inputfile3,by=c("学号","课程名称"))
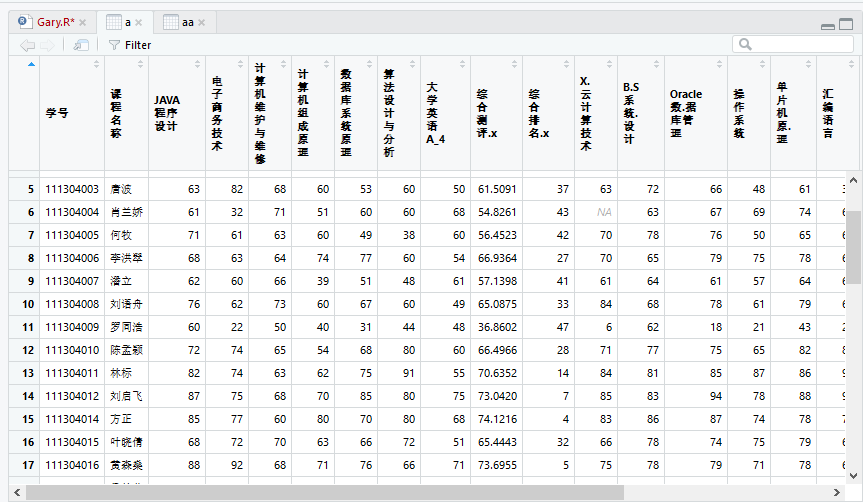
发现aa中存在一个人成绩存在多个综合测评、综合排名的缺陷,把a也添加到by=c("学号","课程名称","综合排名")当中
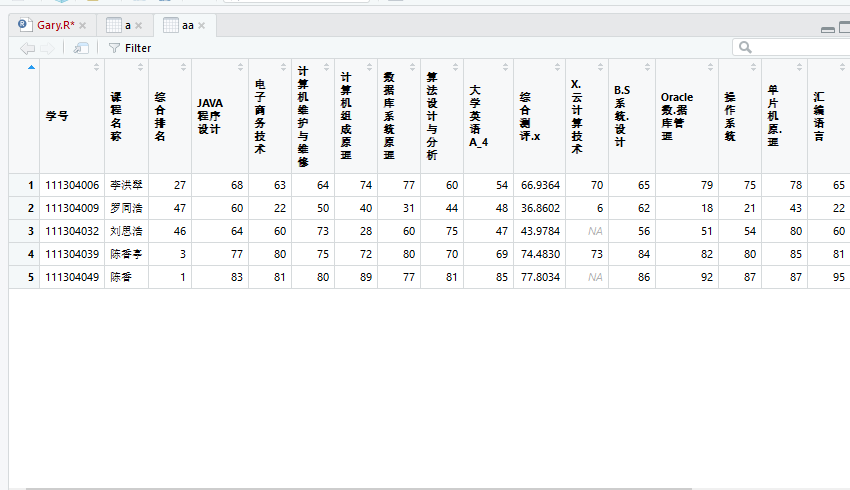
只要第一个学期和第二个学期综合排名不一样时,不显示合并成功的数据!!!
merge()函数对数据的操作还是挺严格的!!!
R_Studio(学生成绩)使用cbind()函数对多个学期成绩进行集成的更多相关文章
- python课后练习当前目录下有一个文件名为score3.txt的文本文件, 存放着某班学生的学号和其两门专业课的成绩。
题目: 当前目录下有一个文件名为score3.txt的文本文件, 存放着某班学生的学号和其两门专业课的成绩.分 别用函数实现以下功能: (1) 定义函数function1,计算每个学生的平均分(取 整 ...
- 【PTA】5-1 输入一个正整数n,再输入n个学生的姓名和百分制成绩,将其转换为两级制成绩后输出。
5-1 输入一个正整数n,再输入n个学生的姓名和百分制成绩,将其转换为两级制成绩后输出.要求定义和调用函数set_grade(stu, n),其功能是根据结构数组stu中存放的学生的百分制成绩scor ...
- sqlserver 查询各个学生语文、数学、英语、历史课程成绩
-- 建表 插入数据 USE 你自己的数据库; CREATE TABLE Member( MID ) PRIMARY KEY, MName ) ); CREATE TABLE Course( FID ...
- Java初学者作业——编写JAVA程序,在控制台输入一位学生的英语考试成绩,根据评测规则,输出对应的成绩等级。定义方法实现学生成绩的评测功能。
返回本章节 返回作业目录 需求说明: 编写JAVA程序,在控制台输入一位学生的英语考试成绩,根据评测规则,输出对应的成绩等级.要求:定义方法实现学生成绩的评测功能. 学生的英语考试成绩进行评测,评测规 ...
- Java初学者作业——编写Java程序,根据输入的某个班级的学员成绩,计算该班级学员的平均成绩,要求输入班级的人数。
返回本章节 返回作业目录 需求说明: 编写Java程序,根据输入的某个班级的学员成绩,计算该班级学员的平均成绩,要求输入班级的人数. 实现思路: 声明变量sum.count以及avg用于存储总成绩.班 ...
- R_Studio(学生成绩)对两个班级学生成绩进行集合,重新计算学生综合测评成绩并对学生按综合测评成绩进行排名
对成绩表"11_1_1.csv" "11_2_1.csv"进行集成,并重新计算4门课程的平均分为综合测评,增加“排名”属性,并按排名排序 "11_1_ ...
- R_Studio(学生成绩)对数据缺失值md.pattern()、异常值分析(箱线图)
我们发现这张Gary.csv表格存在学生成绩不完全的(五十三名学生,三名学生存在成绩不完整.共四个不完整成绩) 79号大学语文.高等数学 96号中国近代史纲要 65号大学体育 (1)NA表示数据集中的 ...
- R_Studio(学生成绩)数据相关性分析
对“Gary.csv”中的成绩数据进行统计量分析 用cor函数来计算相关性,method默认参数是用pearson:并且遇到缺失值,use默认参数everything,结果会是NA 相关性分析 当值r ...
- R_Studio(学生成绩)绘制频率分布直方图、分布饼图、折线比较图
对“Gary.csv”中的成绩数据进行分布分析 (1)按0-59,60-69,70-79,80-89,90-100分组绘制高级语言程序设计成绩的频率分布直方图. (2)按0-59,60-69,70-7 ...
随机推荐
- vim /etc/security/limits.conf中的hard和soft
转自:https://blog.csdn.net/zxljsbk/article/details/89153690 "soft" 和 "hard" 的区别sof ...
- C中的函数指针的用法
include<stdio.h> typedef int (*Cal)(int a,int b);//定义一个函数指针,第一个int是指向函数的返回值的类型,后面括号里面的两个int是指指 ...
- C#中的编译为什么不叫Compile而叫build
是因为Build包含了compile,build既compile了你自己的代码,又把你compile的Assembly和引用别人的Assembly放在一起buiid.
- ACM的一点基础知识
所摘内容来自于XJTU小学期ACM培训PPT log 默认以2为底 计算机一秒可以看作1e8次 保证数据计算精度及数据所需必要大小 a=1LL*a*a%p//在计算时通过乘以1LL,临时将Int转化为 ...
- JS根据一个经纬度及距离角度,算出另外一个经纬度
var mapNumberUtil = {}; /** * 根据一个经纬度及距离角度,算出另外一个经纬度 * @param {*} lng 经度 113.3960698 * @param {*} la ...
- Vue初始化一个项目
@1 npm install -g @vue/cli-init vue init webpack projectName @2 cnpm install -g @vue/cli vue create ...
- 转载:Linux目录文件的权限查看与修改
######################################## ...
- 多线程编程-- part5.1 互斥锁之公平锁-获取锁
基本概念 1.AQS:AbstractQueuedSynchronizer类 AQS是java中管理“锁”的抽象类,锁的许多公共方法都是在这个类中实现.AQS是独占锁(例如,ReentrantLock ...
- 织梦DEDEcms5.7解决arclist标签调用副栏目文章
使用arclist标签调用文章的时候才发现,根本无法调用相关文章. 下面给出解决办法,希望帮到需要的人. 找到/include/taglib/arclist.lib.php文件然后打开.然后在大约30 ...
- 指针、数组与sizeof运算符
指针.数组与sizcof运算符 (1)sizeof是c语言的一个运算符(主要sizeof不是函数,虽然用法很像函数),sizeof的作用是用来返同()里面的变量或者数据类型占用的内存字节数. (2)s ...