kafka具体解释四:Kafka的设计思想、理念
版权声明:本文为博主原创文章,未经博主同意不得转载。 https://blog.csdn.net/suifeng3051/article/details/37606001
本节主要涉及到例如以下主要内容:
- Kafka设计基本思想
- Kafka中的数据压缩
- Kafka消息转运过程中的可靠性
- Kafka集群镜像复制
- Kafka 备份机制
一、kafka由来
在Linkedin开发Kafka之初,把关注重点集中在了这几个方面:
- 为生产者和消费者提供一个通用的API
- 消息的持久化
- 高吞吐量。能够满足百万级别消息处理
- 对分布式和高扩展性的支持
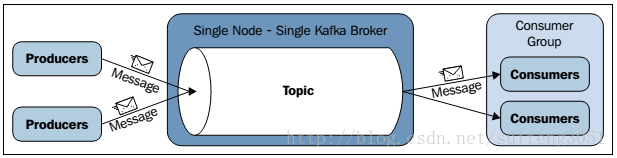
压缩的优点就是降低传输的数据量,减轻对网络传输的压力,在对大数据处理上。瓶颈往往体如今网络上而不是CPU(压缩和解压会耗掉部分CPU资源)。
- 一个消息发送失败
- 一个消息被发送多次
- 最理想的情况:exactly-once ,一个消息发送成功且仅发送了一次
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc3VpZmVuZzMwNTE=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt="" />
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc3VpZmVuZzMwNTE=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt="" />
kafka具体解释四:Kafka的设计思想、理念的更多相关文章
- kafka 名词解释(四)
为什么要了解这些名词的解释呢?因为在学一个新的知识或者领域的时候,我们需要知道它所定义的概念和名词意思,因为只有这样我们才能理解和掌握这个新的知识点,才能更加系统的掌握这个技术. 一.名词解释 1.b ...
- Kafka详解四:Kafka的设计思想、理念
问题导读 1.Kafka的设计基本思想是什么?2.Kafka消息转运过程中是如何确保消息的可靠性的? 本节主要从整体角度介绍Kafka的设计思想,其中的每个理念都可以深入研究,以后我可能会发专题文章做 ...
- Kafka/Metaq设计思想学习笔记 转
转载自: http://my.oschina.net/geecoodeer/blog/194829 本文没有特意区分它们之间的区别,仅仅是列出其中笔者认为好的设计思想,供后续设计参考. 目前笔者并没有 ...
- kafka之二:Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- Kafka具体解释二、怎样配置Kafka集群
Kafka集群配置比較简单,为了更好的让大家理解.在这里要分别介绍以下三种配置 单节点:一个broker的集群 单节点:多个broker的集群 多节点:多broker集群 一.单节点单broker实例 ...
- 中间件 | kafka简介、使用场景、设计原理、主要配置及集群搭建
开源Java学习 公众号 一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性 ...
- kafka学习(四)kafka安装与命令行调用
文章更新时间:2020/06/07 一.安装JDK 过程就不过多介绍了... 二.安装Zookeeper 安装过程可以参考此处~ 三.安装并配置kafka Kafka下载地址 http://kafk ...
随机推荐
- PHP文件操作基本代码
PHP中提供了一系列的I/O函数,能简捷地实现我们所需要的功能,包括文件系统操作和目录操作(如“复制[copy]”).下面兄弟连PHP培训 小编给大家介绍的是基本的文件读写操作:(1)读文件 ;(2) ...
- 三维显示插件——C++
Qt 3D 构建自己的C/C++插件开发框架——系列:https://blog.csdn.net/chgaowei/article/details/4545211 如何使用Qt 3D开发3D场景程序: ...
- js返回上一页并刷新的几种方法
1.返回上一页 1)<a href="javascript:history.go(-1)"></a> 2)<a href="javascri ...
- 阿里云CentOS 7.3安装Redis详细步骤
############ 准备 ############### 从Redis官网下载Linux redis3.2.6版本,我下载的redis-3.2.6.tar.gz(目前最新稳定版),下载到/u ...
- lunwenzhunbei
1,android sensors introduction http://developer.android.com/guide/topics/sensors/sensors_overview.ht ...
- SpringBoot项目的前端+thymeleaf模板引擎
SpringBoot项目创建之后,后台的框架是SpringMVC.但前端的resource和template目录都是空的.这个时候需要创建前台页面. 习惯上,我们会创建JSP,但是,SpringBoo ...
- Matlab 读取文件夹里所有的文件
(image = dir('D:\gesture\*.*'); % dir是指定文件夹得位置,他与dos下的dir用法相同. 用法有三种: 1. dir 是指工作在当前文件夹里 2. dir name ...
- Qualcomm 8X camera过程解析【转】
本文转载自:http://blog.csdn.net/gabbzang/article/details/19906687 http://www.01yun.com/mobile_development ...
- Gym 100942A Three seamarks
题目链接: http://codeforces.com/problemset/gymProblem/100942/A ----------------------------------------- ...
- 剑指 Offer——最小的 K 个数
1. 题目 2. 解答 2.1. 方法一--大顶堆 参考 堆和堆排序 以及 堆的应用,我们将数组的前 K 个位置当作一个大顶堆. 首先建堆,也即对堆中 [0, (K-2)/2] 的节点从上往下进行堆化 ...