JVM调优学习 【更新中】
JVM调优(jdk1.8)
老生常谈,面试吹牛的的最佳谈资,在接下来的几天里,我找了点资料来对其进行一波学习;
本地环境是不需要对我们的虚拟机进行优化的,一般在生产环境下,也就是Linux下才有对JVM优化的需求
JVM的运行参数
参数的类型有三种
在JVM中有很多的参数是可以设置的,这些参数我们把它分为三类
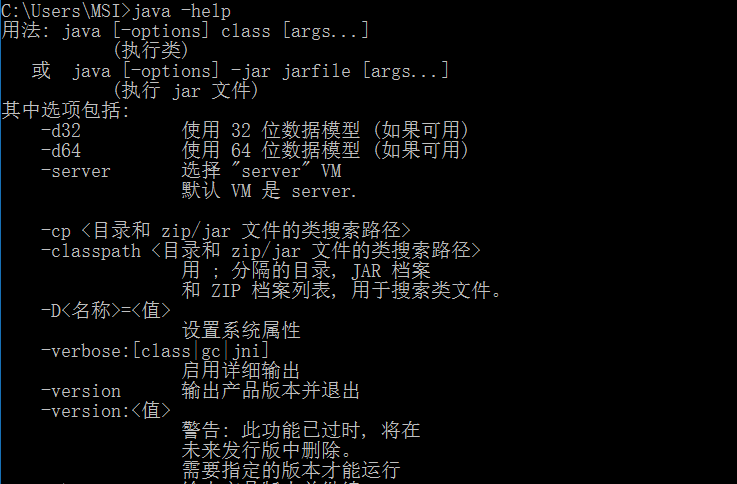
标准参数(比较稳定的,在未来的版本更迭中,都不会丢失的,非标准的参数不能保证)
-X参数(也就是非标准的 java -X 查看所有的参数)
-XX参数(也是非标准参数,这种类型的参数一般都是用于JVM的调优改动)
java -help:查看命令,我们可以在里面找到上面所说的三种类型的的影子
Demo:标准参数
java -version :查看jvm的版本
java -showversion :查看kvm版本信息,并执行其后的其他命令(常用)
-D:设置系统参数,相当于上下文,我们可以添加K和V进去,然后拿到K的值
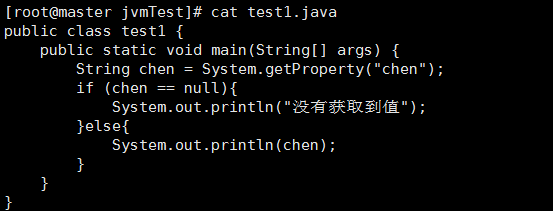
首先我们去Linux上写一个测试类如下所示:
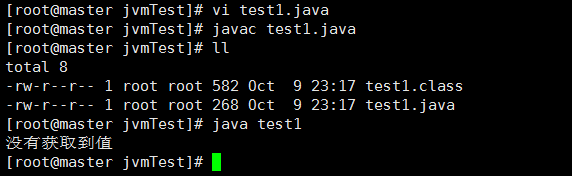
然后我们去编译并运行它:
可见是没有值的,下面我们就对“chen”这个K,设置Value,让他被获取到:
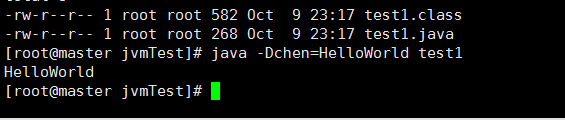
java -Dchen=HelloWorld test1:意思为设置系统属性”chen“,为其赋值为HelloWorld,然后再运行test1文件,
最后输出结果已经可以发现,系统属性设置生效
-server 和 -client 模式
server模式的话,jvm的初始化堆空间会大一些,启动慢,但是后续的运行就非常的丝滑
client模式的话,jvm初始化的堆空间就会小一点,启动非常快,但是运行相对较卡
这个都是了解部分,以为jvm在启动的时候会根据硬件和系统自动给我选择最合适的模式
现在的机器基本都是64位的系统吧,64位的系统只支持server模型,只要机器给力都是选择server模式
Demo:-X参数 [ 调优参数]
我们可以通过java -X 这个命令去获取所有-x的参数列表

-Xms和-Xmx参数设置堆内存的初始化大小和最大大小
-Xmx2048m:表示设置JVM的最大堆内存为2048兆
-Xms512m:表示设置JVM的初始化堆内存为512兆
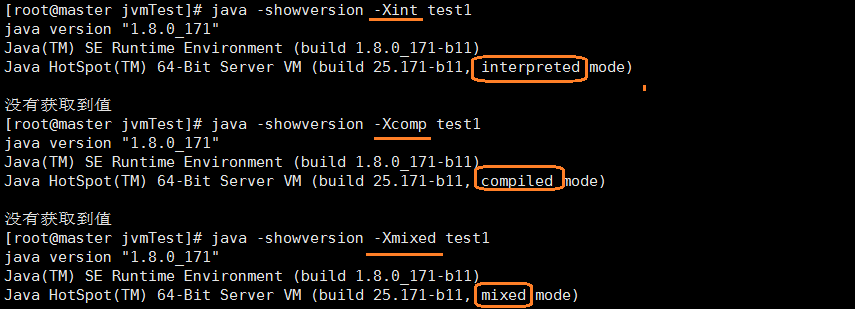
-Xint、-Xcomp、-Xmixed,这三个参数的配置
-Xint,解释模式,会强制jvm逐行执行所有的字节码,运行速度很明显的变慢
-Xcomp,编译模式,jvm在第一次使用时会把所有的字节码编译成本地代码(会卡一下),带来最大的优化效果
-Xmixed,混合模式,将解释模式与编译模式进行混合使用,由jvm自己决定,默认使用该模式
编译模式下会卡顿一下再弹出结果,这个值得注意一下,但这也是一种优化,后面执行就会非常流畅
Demo:-XX参数 [调优参数]
上面已经说到,-XX也是非标准参数,主要用于jvm的调优和debug的操作
-XX参数的使用分为两种方式,一种boolean类型,一种非boolean类型
boolean类型
-XX[+/-]<name> :表示启动或者禁用某个属性,+:启动,-:禁用
如:-XX:+DisableExplicitGC:表示开启禁用手动调用gc操作,也就是说System.gc无效
非boolean类型
-XX:<name>=<value> :表示name的值为Value
如:-XX:NewRatio=1 :表示新生代和老年代的比值
查看当前JVM的运行参数
运行Java命令时打印出运行参数
执行:java -XX:+PrintFlagsFinal test1
会得到一堆信息配置的信息,大部分的信息我们都看不懂,但还是有一点需要说明
在我们得到的信息列表中都是KV结构的,V一般分为true/false或者为属性值这两种方式
k=V,这种通过=符号表示的,是使用的默认值
k:=V,这种方式表示已经被我们改动,是使用的我们给定的参数
查看正在运行的java进程的参数
启动一个tomcatu用于测试,下面我们通过jinfo命令查看所有的运行参数信息
jinfo -flags <进程id>:进程ID,我们可以通过ps -ef | grep tomcat 拿到,下面我们一起来看看
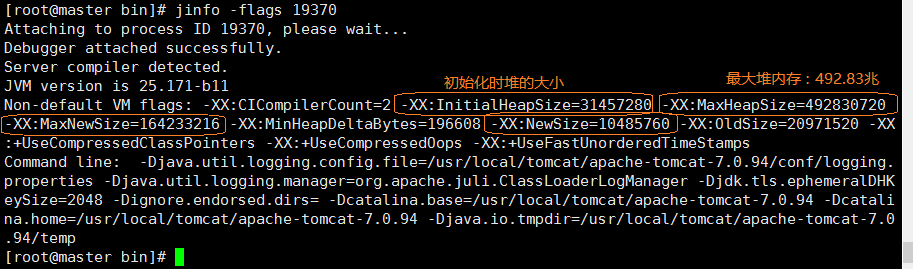
通过上面这张体,可以发现,很多参数被被打印了,虽然我们大部分都不知道他的意思,但我们仔细读读还是有那么两个我们在上面讲过的
如果我们只想单一的查看某个运行参数的值,我们可以通过下面这种方式获取:
jinfo -flag <参数名称> <进程id>,比如我们去获取最大的堆内存空间大小:


JVM的内存模型
内存模型在线分析 【1.8】
你也可以 :回顾往日学习:jvm内存模型
首先我们需要知道的是,了解JVM的内存模型对于JVM调优有什么帮助?
[JDK1.7] :年轻带——老年代——永久代 (统一被JVM虚拟机管理)
[JDK1.8]: 年轻带——老年代——元空间(元空间被操作系统本地内存内管理)
总体上划分为了三个板块,每个板块中都会再进行细度划分,但都有一个伸缩区的存在,且占有大量内存空间
我们在JVM内存模型中的优化主要就是针对这个伸缩区的大小进行根据项目进行调整,实现优化效果
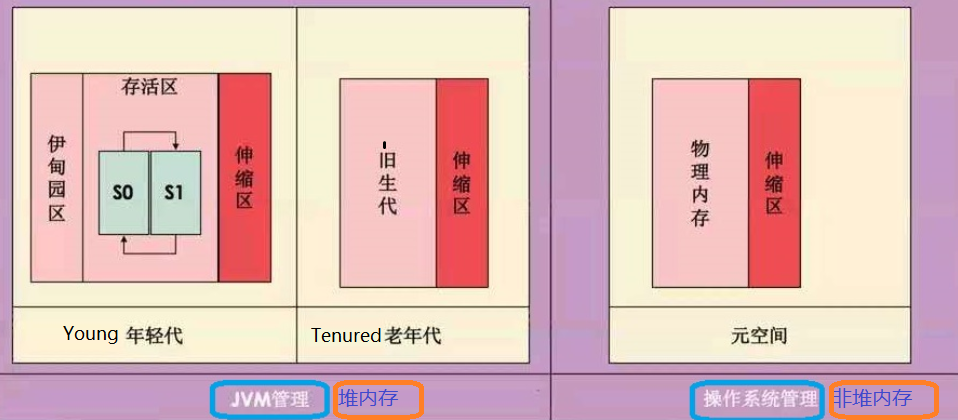
jdk1.8的内存模型:
【年轻代】:被细分为三个区域[Eden区、两个大小严格相同的Survivor区、伸缩区]
Eden区用于存放刚刚创建的对象,空间占满了就会触发GC,有些对象在GC后仍然保留了下来,进入存活区
存活取有两个严格相同大小的空间,某一时刻,只有一个是在被使用的,比如图中的S0用来存放Eden过来的对象
当S0空间不足,触发GC时,就会把仍然存活的对象复制到S1,然后把S0的内存空间给刷掉
根据JVM的策略,再存活取经过几次GC后,然后存在的对象就会被存放到老年代中去
【老年代】:被细分为 [旧生代、伸缩区]
主要保存生命周期较长的对象,用于分撒年轻的储存压力
当我创建的是一个比较大的对象时,会跳过年轻带直接进入老年代储存
【元空间】:替换了1.7中的永久代,被细分为[CCS、CodeCache]
CodeCache:存放类,class等数据
CCS:类的压缩指针,默认不开启,不做使用
【伸缩区 Virtual区】:最大内存和初始内存的差值,就是伸缩区,这就是我们优化的目标所在
为什么废除1.7的永久代和使用寄存在本地内存中的元空间
因为永久代内存经常不够用且有发生内存泄漏的隐患,爆出内存空间不足的错误
基于此,将永久代废弃,采用基于本地内存空间的元空间
使用jstat查看堆内存的使用情况
jstat:可以查看堆内存中各部分的使用量,以及加载类的数量
格式:jstat -命令现象 进程id 运用如下所示
查看class加载统计
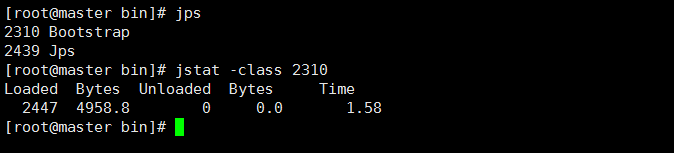
Loaded:Tomcat启动一共加载的class数量
Bytes:所占用的空间大小
Unloaded:未加载数量
Bytes:未加载占用空间大小
Time:加载所耗时间
查看编译统计

Compiled:编译数量
Failed:失败数量
Invalid:不可用数量
Time:编译所耗时间
FailedType:失败类型
FailedMethod:失败的方法
查看垃圾回收统计(重点)
我们可以通过使用 jstat -gc 2310 1000 5
这种命令来多次查看,比如上面这个命令的意思为:一秒执行一次,一共执行五次

眼睛都给我看瞎了,卧槽!
soc:第一个 Survivor区的大小
s1c:第二个 Survivor区的大小(严格规定大小一致)
s0u:第一个 Survivor区的使用大小
s1u:第二个 Survivor区的使用大小
EC:Eden区的大小(KB)
EU:Eden区的使用大小
OC:Old区大小(KB)
OU:Old使用大小
MC:方法区大小(KB)
MU:方法区使用大小
CCSC:压缩类空间大小(KB)
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
jmap的使用以及内存溢出的分析
jmap相比jstat可以获取到更多详细的数据
查看内存的使用情况
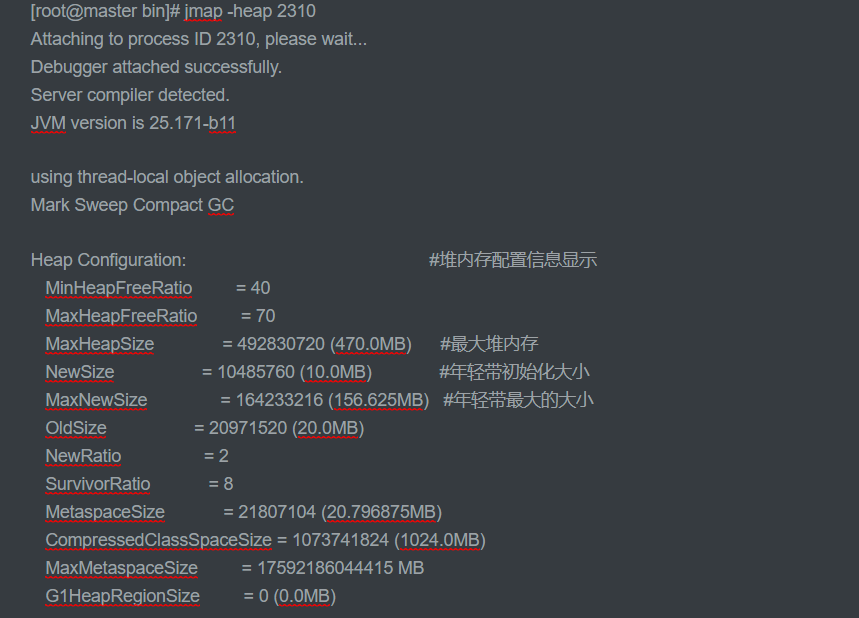
jmap -heap 进程id,如下所示
不能粘贴文本,格式会乱,我截了部分图做一个说明:
查看内存中对象数量以及大小
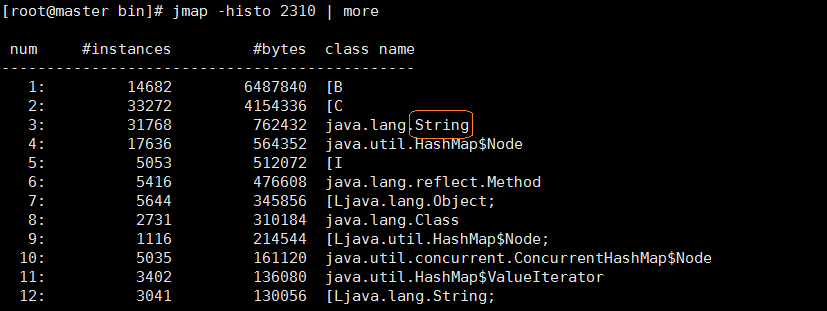
jmap -histo 2310 | more :查看所有对象,包括活跃以及非活跃对象的相关信息
jmap-histo:live 2310 | more :查看活跃的对象详细
其他你不认识,String总该认识吧。通过上面的命令,我们知道String在Tomcat这个进程中一共创建了31768个对象,占用内存762432K大小,至于其他的让我们慢慢写来
B :byte
C:char
D:double
F:float
I: int
J: long
Z: boolean
[ :数组,可以上面配合使用
[L + 类名 :其他对象
可见,byte数组创建的UI底下那个不是最多的,但是所占用的内存开销确是最大的
将内存使用情况dump到文件中
什么意思呢?dump:转储
也就是将我们的内存的使用情况输出到文件中,然后我们对其进行分析
jmap -dump:format=b,file=指定转储文件绝对路径 进程id

通过jhat对dmup的文件进行分析
上面我们已经通过dump命令,将我们的Tomcat的 内存使用情况转储到了本地dump.dat文件中
下面我们通过jhat对该文件进行分析,jhat用法如下:jhat -port 自定义端口号 dump文件绝对路径
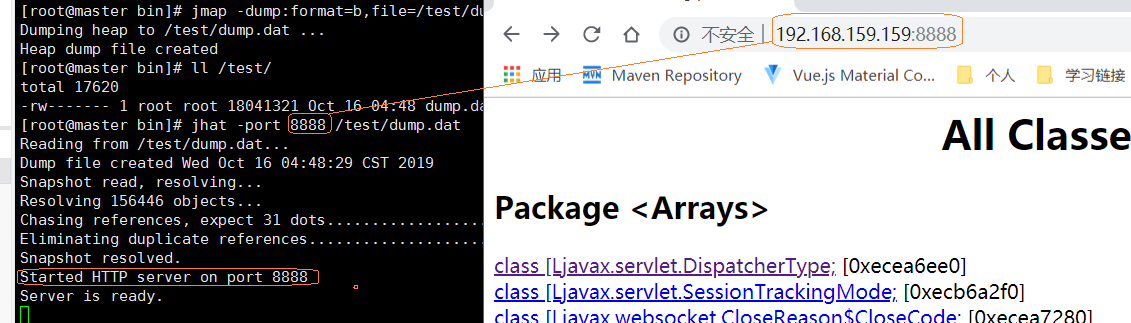
上面可以看到,我本地已经对其进行了访问,每个对象都是以包的方式集结在一起,所以如果想要看我们自己写的代码的话,去找包就能找到,点击进去我发现我的功力还不够,看不出什么名堂来,
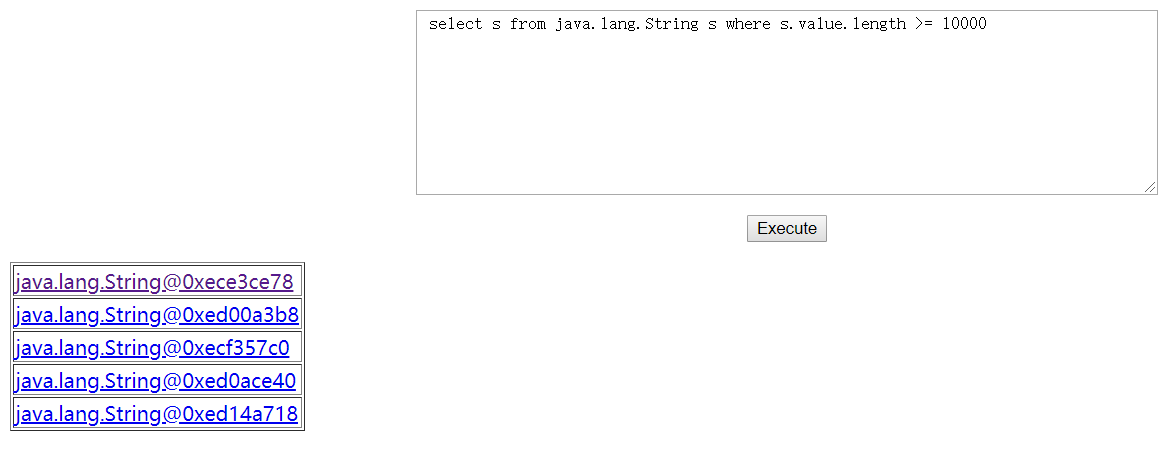
下面讲另一个东西,我们直接网页翻到最底部:最后一行数据:[Execute Object Query Language (OQL) query]
OQL:这是一种检索语言,有点像sql,我们点进去,查看相关的帮助文档:
测试一把,我们调整检索条件? 把字符长度调整到1W去,再次检索
可以发现,很多都是配置文件,Tomcat内部将配置文件读取后赋值给了一个String对象

通过MAT工具对dump文件进行分析
JVM调优学习 【更新中】的更多相关文章
- JVM调优- 学习笔记(转)
http://blog.csdn.net/fenglibing/article/details/6321453 GC学习笔记 这是我公司同事的GC学习笔记,写得蛮详细的,由浅入深,循序渐进,让人一看就 ...
- java虚拟机学习-JVM调优总结-分代垃圾回收详述(9)
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的.因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率. 在Java程序运行的过程中,会产生大量的对象, ...
- JVM调优浅谈
1.数据类型 java虚拟机中,数据类型可以分为两类:基本类型和引用类型.基本类型的变量保存原始值,即:它代表的值就是数值本身,而引用类型的变量保存引用值.“引用值”代表了某个对象的引用,而不是对象本 ...
- JVM调优总结(4):分代垃圾回收
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的.因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率. 在Java程序运行的过程中,会产生大量的对象, ...
- JVM调优浅谈(转)
1.数据类型 java虚拟机中,数据类型可以分为两类:基本类型和引用类型.基本类型的变量保存原始值,即:它代表的值就是数值本身,而引用类型的变量保存引用值.“引用值”代表了某个对象的引用,而不是对象本 ...
- 一文带你深入了解JVM性能调优以及对JVM调优的全面总结
目录 JVM调优 概念 基本垃圾回收算法 垃圾回收面临的问题 分代垃圾回收详述1 分代垃圾回收详述2 典型配置举例1 典型配置举例2 新一代的垃圾回收算法 调优方法 反思 一.JVM调优的一些概念 数 ...
- JVM调优小结
JVM调优浅谈 https://www.cnblogs.com/andy-zhou/p/5327288.html 1.数据类型 java虚拟机中,数据类型可以分为两类:基本类型和引用类型. 基本类 ...
- JVM调优总结(四)-分代垃圾回收详述
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的.因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率. 在Java程序运行的过程中,会产生大量的对象, ...
- JVM调优-Java垃圾回收之分代回收
为什么要进行分代回收? JVM使用分代回收测试,是因为:不同的对象,生命周期是不一样的.因此不同生命周期的对象采用不同的收集方式. 可以提高垃圾回收的效率. Java程序运行过程中,会产生大量的对象, ...
随机推荐
- php操作redis--生存时间篇
常用函数:expireAt,expire,ttl 应用场景:登陆生效时间,验证码有效时间等 设置某个键的有效时间,如当天有效(以时间戳的方式设置) $expireTime = mktime('23', ...
- apue 第19章 伪终端
伪终端是指对于一个应用程序而言,他看上去像一个终端,但事实上它并不是一个真正的终端. 进程打开伪终端设备,然后fork.子进程建立一个新的会话,打开一个相应的伪终端从设备.复制输入.输出和标准错误文件 ...
- JavaScript 工作原理之十一-渲染引擎及性能优化小技巧
原文请查阅这里,略有删减,本文采用知识共享署名 4.0 国际许可协议共享,BY Troland. 本系列持续更新中,Github 地址请查阅这里. 这是 JavaScript 工作原理的第十一章. 迄 ...
- Android_开发片段(Part 1)
1.maven环境配置时也跟java类似,进行我的电脑环境的设置,cmd查询:mvn -version 2.在新建AVD时,要注意AVD的版本(API),版本太低或者太高,经常不能运行项目或者在运行项 ...
- Apache2.2+mod_encoding解决URL中文编码问题
我们经常在论坛上看到这样的求救贴: 为什么我看不了网站上中文文件名的文件?这时一定会有好心的大侠告诉说,到IE6的工具,Internet选项, 高级里,把"总是以UTF-8发送URL&quo ...
- (4)C++ 复合类型-指针
篇幅长从 https://www.cnblogs.com/buchizaodian/p/11511256.html 提取出来 七.指针和自由存储空间 1.寻址运算符 * #include<io ...
- PAT甲级——A1145 HashingAverageSearchTime【25】
The task of this problem is simple: insert a sequence of distinct positive integers into a hash tabl ...
- 13-vim-复制和粘贴-01-复制和粘贴
1.vi中提供有一个被复制文本的缓冲区 复制命令会将选中的文字保存在缓冲区. 删除命令删除的文字会被保存在缓冲区 在需要的位置,使用粘贴命令可以将缓冲区的文字插入到光标所在位置. vi中的文本缓冲区同 ...
- idea部署tomcat项目时,在项目里打断点不能拦截
以下内容都是基于我自己的项目(如未解决道友们的问题,请别介意) idea部署tomcat项目时,在项目里打断点不能拦截,工作中遇到的问题,记录一下(tomcat6) 当项目的以下内容配置完毕后,启动项 ...
- tomcat+nginx 单机部署多应用LINUX
1.首先虚拟机上安装nginx 和tomcat,这里安装就不赘述了. nginx安装可以参考https://www.linuxidc.com/Linux/2016-09/134907.htm,相关配置 ...