Mysql - 查询之关联查询
查询这块是重中之重, 关系到系统反应时间. 项目做到后期, 都是要做性能测试和性能优化的, 优化的时候, 数据库这块是一个大头.
sql格式: select 列名/* from 表名 where 条件 group by 列 having 条件 order by 列 asc/desc;
这里牵涉到一个查询执行顺序的问题.
单表查询执行顺序:
select sex, count(Sex) as count from tch_teacher where id > 15 group by Sex having count > 5 order by Sex asc limit 1;
1-> from 表 : 首先拿到表tch_teacher
2-> where 条件 : 根据where后面的条件筛选一遍数据集合A
3-> group by 分组 : 对筛选出的数据A, 根据group by后面的列进行分组, 得到数据集B
4-> having 筛选 : 对数据集B进行进一步筛选, 得到数据集C
5-> select 数据 : 这里有四步
第一步 : 根据select后面的列名, 去数据集C中取数据. 得到数据集D
第二步 : 对数据集D中的数据进行去重操作(这一步是建立在 sql中有distinct 情况下), 得到数据集E
第三步 : 对数据集E进行排序操作, 得到数据集F
第四步 : 对数据集F进行截取数据操作, 得到最终的数据集(执行 limit 10 操作)
在多表的时候, 优化器在优化的时候, 会有些区别, 有些地方, 会用到where条件, 然后才连表
一、连表查询
1. 交叉连接 -- 笛卡尔乘积 cross join
select * from tch_teacher cross join tch_contact
这种连接方式, 没见人用过. 如果tch_teacher,tch_contact表各有10条数据, 那么连接的结果, 就是 10 x 10 = 100 条数据.
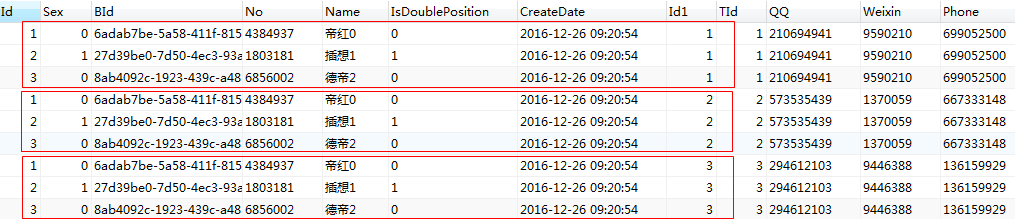
在mysql 中, cross join 后面是可以跟 on 和 where 的, 加上之后, 其实跟 inner join 是一样的
2. 内连接 -- inner join
内连接在不加on的情况下, 也是去求笛卡尔乘积. 不加on的用法并不推荐使用, 容易造成内存溢出的情况. 加on的时候, 在连表的时候, 就会对数据进行筛选, 以此来缩减有效数据范围
select * from tch_teacher inner join tch_contact
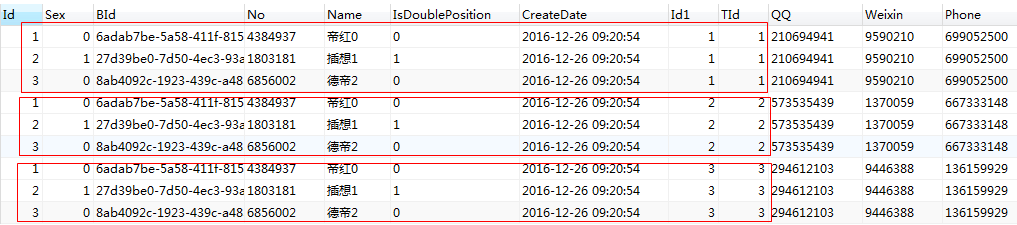
从上面的sql和图片来看, inner join 的时候, 可以不加on, 也能得到一个结果, 而且这个结果和交叉连接的结果是一样的.
这里还有另外两种写法:
select * from tch_teacher,tch_contact select * from tch_teacher join tch_contact
得到的结果是一样的.
3. 外连接 -- left/right join on
这里我特意加了一个on在上面, 因为不加on是会报错的.
left join 称之为左连接, 连接以左侧表数据为准, 当右表没有数据与之匹配的时候, 则会用null填补
right join 称之为右连接, 与 left join 相反, 这个是以右表为准
先看下效果吧
select * from tch_teacher left join tch_contact on tch_teacher.Id = tch_contact.TId;

select * from tch_teacher right join tch_contact on tch_teacher.Id = tch_contact.TId;

其实这里还有一个full join , 不过mysql里面的full join, 着实有些让人无语, 反正我没这么用过, 略过不表了.
这里我做了一个小测试, 这里的数据, tch_contact的tid值, 我取的是0~100000之间的随机数
select * from tch_teacher inner join tch_contact on tch_teacher.Id = tch_contact.TId ; select * from tch_teacher LEFT join tch_contact on tch_teacher.Id = tch_contact.TId ;
| tch_teacher | tch_contact | inner join(s) | 结果 | left join(s) | 结果 |
| 十万 | 十万 | 0.499 | 99999 | 0.526 | 137017 |
| 十万+5000 | 十万 | 0.345 | 99999 | 0.565 | 142017 |
| 十万-5000 | 十万 | 0.472 | 94949 | 0.534 | 130124 |
这里面的值, 是我反复运行之后, 在一些离散值里面, 取得比较靠近中心点的值.
4. 自己连自己
mysql里面, 有一个比较好用的功能, 就是自己连自己. 我再tch_teacher表里面加入一列, CreateBy, 存放的是这个表的Id值
select a.*, b.Name as CreateByName from tch_teacher a
left join tch_teacher b on a.createby = b.id
能得到以下结果:

二、union查询
除了把几个表通过内部关系拼成一个表结果, 还可以, 把多个表的查询表结果拼成一个表结果. 所使用的方法就是union.
这里要注意的是, 列的顺序. 如果害怕列的顺序不一致不好排查, 可以把表结果的列名都重命名为相同的.
select Id, Sex, BId, `No`, Name, CreateDate from tch_teacher union select 0 as Id, Sex, BId, `No`, Name, CreateDate from tch_teacher_temp
union是会对最后的表结果进行去重操作的, 如果我不想去重, 只想快速得到拼接的结果, 可以使用 union all 来拼接.
参考:
Mysql - 查询之关联查询的更多相关文章
- Mysql多表表关联查询 inner Join left join right join
Mysql多表表关联查询 inner Join left join right join
- MySQL如何执行关联查询
MySQL中‘关联(join)’ 一词包含的意义比一般意义上理解的要更广泛.总的来说,MySQL认为任何一个查询都是一次‘关联’ --并不仅仅是一个查询需要到两个表的匹配才叫关联,索引在MySQL中, ...
- mysql如何执行关联查询与优化
mysql如何执行关联查询与优化 一.前言 在数据库中执行查询(select)在我们工作中是非常常见的,工作中离不开CRUD,在执行查询(select)时,多表关联也非常常见,我们用的也比较多,那么m ...
- mysql系列九、mysql语句执行过程及运行原理(分组查询和关联查询原理)
一.背景介绍 了解一个sql语句的执行过程,了解一部分都做了什么,更有利于对sql进行优化,因为你知道它的每一个连接.where.分组.子查询是怎么运行的,都干了什么,才会知道怎么写是不合理的. 大致 ...
- MySQL查询(关联查询)
一.mysql查询与权限 (一)数据库关联查询 **内连接查询(inner join)** 查询两个表共有的数据,交集 SELECT * FROM tb1 INNER JOIN tb2 ON 条件 所 ...
- Mongoose如何实现统计查询、关联查询
[问题]Mongoose如何实现统计查询.关联查询 发布于 4 年前 作者 a272121742 13025 次浏览 最近业务上提出一个需求,要求能做统计,我们设计的文档集,统计可能跨越的文档会 ...
- JDBC MySQL 多表关联查询查询
public static void main(String[] args) throws Exception{ Class.forName("com.mysql.jdbc.Driver&q ...
- MySQL 如何执行关联查询
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/51 当前mysql执行的策略很简单:mysql对任何关联都执行嵌 ...
- MySQL多表关联查询与存储过程
-- **************关联查询(多表查询)**************** -- 需求:查询员工及其所在部门(显示员工姓名,部门名称) -- 1.1 交叉连接查询(不推荐.产生笛卡尔乘积 ...
- Mysql子查询、关联查询
mysql中update.delete.install尽量不要使用子查询 一.mysql查询的五种子句 where(条件查询).having(筛选).group by(分组).orde ...
随机推荐
- WPF 有用博客地址
增加智能感知的RichTextBox扩展控件(WPF) WPF自定义控件与样式(3)-TextBox & RichTextBox & PasswordBox样式.水印.Label标签. ...
- 12、Struts2表单重复提交
什么是表单重复提交 表单的重复提交: 若刷新表单页面, 再提交表单不算重复提交. 在不刷新表单页面的前提下: 多次点击提交按钮 已经提交成功, 按 "回退" 之后, 再点击 &qu ...
- Nginx反向代理,负载均衡,redis session共享,keepalived高可用
相关知识自行搜索,直接上干货... 使用的资源: nginx主服务器一台,nginx备服务器一台,使用keepalived进行宕机切换. tomcat服务器两台,由nginx进行反向代理和负载均衡,此 ...
- jQuery可拖拽3D万花筒旋转特效
这是一个使用了CSS3立体效果的强大特效,本特效使用jQuery跟CSS3 transform来实现在用户鼠标按下拖动时,环形图片墙可以跟随鼠标进行3D旋转动画. 效果体验:http://hovert ...
- 太多选择——企业如何选择合适的BI工具?
在没认清现状前,企业当然不能一言不合就上BI. BI不同于一般的企业管理软件,不能简单归类为类似用于提高管理的ERP和WMS,或用于提高企业效率的OA.BPM.BI的本质应该是通过展现数据,用于加强企 ...
- Android—基于微信开放平台v3SDK,开发微信支付填坑。
接触微信支付之前听说过这是一个坑,,,心里已经有了准备...我以为我没准跳坑出不来了,没有想到我填上了,调用成功之后我感觉公司所有的同事都是漂亮的,隔着北京的大雾霾我仿佛看见了太阳~~~好了,装逼结束 ...
- 嵌入式&iOS:回调函数(C)与block(OC)传 参/函数 对比
C的回调函数: callBack.h 1).声明一个doSomeThingCount函数,参数为一个(无返回值,1个int参数的)函数. void DSTCount(void(*CallBack)(i ...
- git命令行操作
从本地上传代码到仓库(假设已经建好仓库): 1.初始化: git init 2.将所有文件加入缓存区: git add * 3.提交当前工作空间的修改内容: git commit -m 'commit ...
- 好用的Markdown编辑器一览 readme.md 编辑查看
https://github.com/pandao/editor.md https://pandao.github.io/editor.md/examples/index.html Editor.md ...
- 四、可空类型Nullable<T>到底是什么鬼
值类型为什么不可以为空 首先我们都知道引用类型默认值都是null,而值类型的默认值都有非null. 为什么引用类型可以为空?因为引用类型变量都是保存一个对象的地址引用(就像一个url对应一个页面),而 ...