cuda编程-矩阵乘法(2)
采用shared memory加速
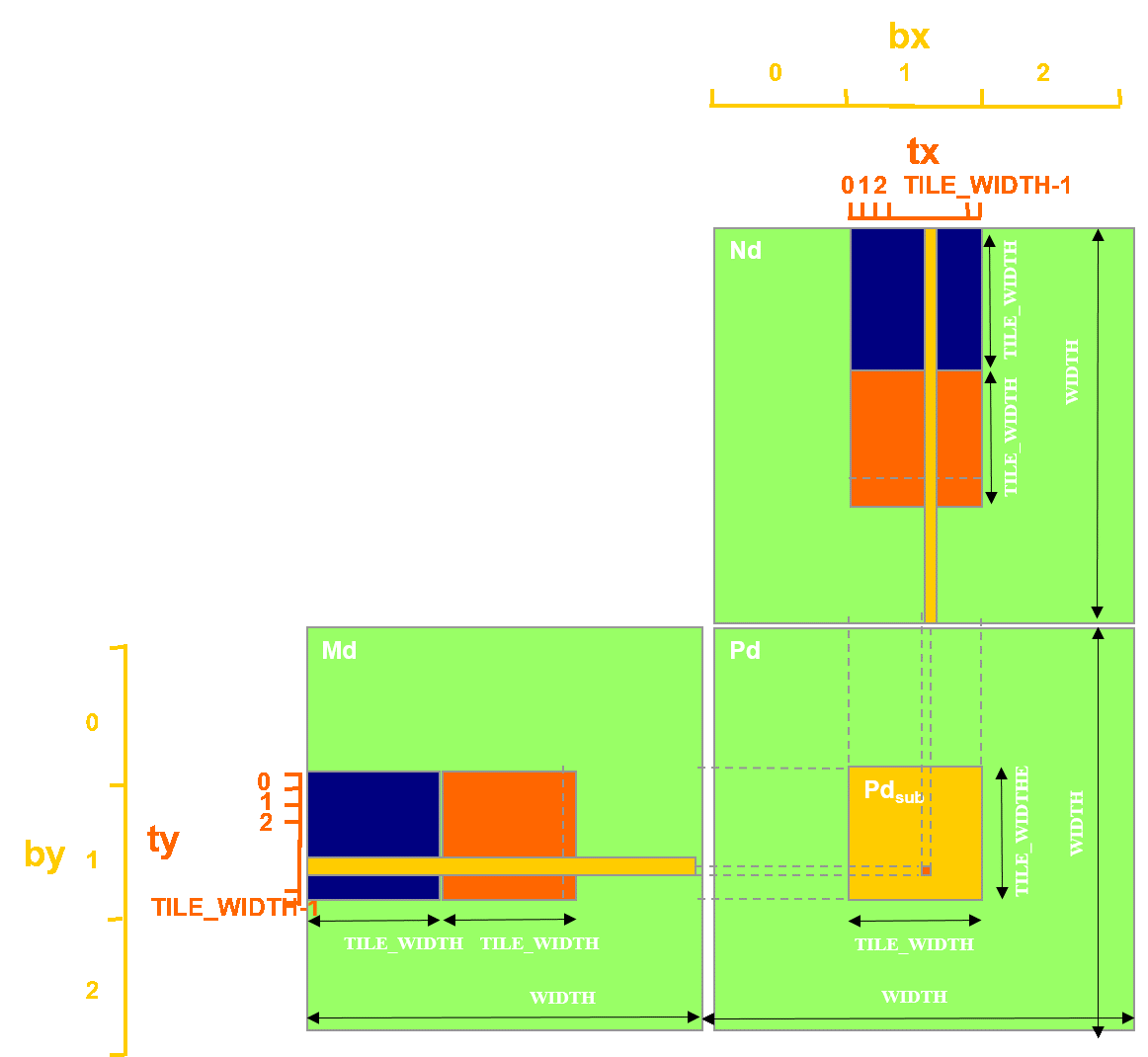
代码
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <algorithm>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include "functions.h" #define TILE_SIZE 16 __global__ void matrixMulKernel(float *C, float *A, float *B, int width, int height){
__shared__ float tile_A[TILE_SIZE][TILE_SIZE];
__shared__ float tile_B[TILE_SIZE][TILE_SIZE];
unsigned int tx = threadIdx.x;
unsigned int ty = threadIdx.y;
unsigned int gx = blockIdx.x * TILE_SIZE + tx;
unsigned int gy = blockIdx.y * TILE_SIZE + ty;
if (gx >= width || gy >= height)
return; // Load shared memory
int tile_num = (width + TILE_SIZE - ) / TILE_SIZE;
float sum = ;
for (int i = ; i < tile_num; ++i){
int bound = min(width, TILE_SIZE);
for (int j = tx; j < bound; j += blockDim.x){
tile_A[ty][j] = A[gy * width + i * bound + j];
}
for (int j = ty; j < bound; j += blockDim.y){
tile_B[j][tx] = B[(i * bound + j) * width + gx];
}
//Synchronize to make sure the sub-matrices are loaded before starting the computation
__syncthreads(); for (int j = ; j < bound; ++j){
sum += tile_A[ty][j] * tile_B[j][tx];
}
//Synchronize to make sure that the preceding computation is done before loading two new
//sub-matrices of M and N in the next iteration
__syncthreads();
}
C[gy*width + gx] = sum;
} void constantInit(float *data, int size, float val){
for (int i = ; i < size; ++i){
data[i] = val;
}
} void matrixMul(){
int dev_id = ;
cudaSetDevice(dev_id); // Allocate host memory for matrices A and B
int width = ;
int height = ;
unsigned int size = width * height;
unsigned int mem_size = sizeof(float)* size;
float *h_A = (float *)malloc(mem_size);
float *h_B = (float *)malloc(mem_size);
float *h_C = (float *)malloc(mem_size); // Initialize host memory
const float valB = 0.01f;
constantInit(h_A, size, 1.0f);
constantInit(h_B, size, valB); // Allocate device memory
float *d_A, *d_B, *d_C;
cudaMalloc((void **)&d_A, mem_size);
cudaMalloc((void **)&d_B, mem_size);
cudaMalloc((void **)&d_C, mem_size); // Memcpy
cudaMemcpy(d_A, h_A, mem_size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, mem_size, cudaMemcpyHostToDevice); // Config dim
dim3 block(TILE_SIZE, TILE_SIZE);
dim3 grid((width + block.x - ) / block.x, (height + block.y - ) / block.y);
matrixMulKernel <<<grid, block >>>(d_C, d_A, d_B, width, height); // Memcpy device to host
cudaMemcpy(h_C, d_C, mem_size, cudaMemcpyDeviceToHost); // Check
printf("Checking computed result for correctness: ");
bool correct = true;
// test relative error by the formula // |<x, y>_cpu - <x,y>_gpu|/<|x|, |y|> < eps
double eps = .e-;
// machine zero
for (int i = ; i < (int)(width * height); i++) {
double abs_err = fabs(h_C[i] - (width * valB));
double dot_length = width;
double abs_val = fabs(h_C[i]);
double rel_err = abs_err / abs_val / dot_length;
if (abs_err > eps) {
printf("Error! Matrix[%05d]=%.8f, ref=%.8f error term is > %E\n", i, h_C[i], (float)(width*height), eps);
correct = false;
}
}
printf("%s\n", correct ? "Result = PASS" : "Result = FAIL");
}
合并访存:tile_A按行存储,tile_B按列存储,sum=row_tile_A * row_tile_B
__global__ void matrixMulKernel(float *C, float *A, float *B, int width, int height){
__shared__ float tile_A[TILE_SIZE][TILE_SIZE];
__shared__ float tile_B[TILE_SIZE][TILE_SIZE];
unsigned int tx = threadIdx.x;
unsigned int ty = threadIdx.y;
unsigned int gx = blockIdx.x * TILE_SIZE + tx;
unsigned int gy = blockIdx.y * TILE_SIZE + ty;
if (gx >= width || gy >= height)
return;
// Load shared memory
int tile_num = (width + TILE_SIZE - ) / TILE_SIZE;
float sum = ;
for (int i = ; i < tile_num; ++i){
tile_A[tx][ty] = A[gy * width + i * TILE_SIZE + tx];
tile_B[ty][tx] = B[(i * TILE_SIZE + ty) * width + gx];
//Synchronize to make sure the sub-matrices are loaded before starting the computation
__syncthreads();
for (int j = ; j < TILE_SIZE; ++j){
sum += tile_A[j][ty] * tile_B[j][tx];
}
//Synchronize to make sure that the preceding computation is done before loading two new
//sub-matrices of M and N in the next iteration
__syncthreads();
}
C[gy*width + gx] = sum;
}
cuda编程-矩阵乘法(2)的更多相关文章
- cuda编程-矩阵乘法(1)
本方法采用简单的单线程计算每组行和列乘加运算 代码如下: #include <stdio.h> #include <stdlib.h> #include <iostrea ...
- cuda(2) 矩阵乘法优化过程
Created on 2013-8-5URL : http://blog.sina.com.cn/s/blog_a502f1a30101mjch.html@author: zhxfl转载请说明出处 # ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
- CUDA编程之快速入门【转】
https://www.cnblogs.com/skyfsm/p/9673960.html CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架 ...
- 详解CUDA编程
CUDA 是 NVIDIA 的 GPGPU 模型,它使用 C 语言为基础,可以直接以大多数人熟悉的 C 语言,写出在显示芯片上执行的程序,而不需要去学习特定的显示芯片的指令或是特殊的结构.” 编者注: ...
- CUDA 矩阵乘法终极优化指南
作者:马骏 | 旷视 MegEngine 架构师 前言 单精度矩阵乘法(SGEMM)几乎是每一位学习 CUDA 的同学绕不开的案例,这个经典的计算密集型案例可以很好地展示 GPU 编程中常用的优化技巧 ...
- OpenCL 矩阵乘法
▶ 矩阵乘法,按照书里的内容进行了几方面的优化,包括局部内存,矢量数据类型,寄存器,流水线等. ● 最直接的乘法.调用时 main.c 中使用 size_t globalSize[] = { rowA ...
- 【Cuda编程】加法归约
目录 cuda编程并行归约 AtomicAdd调用出错 gpu cpu下时间计算 加法的归约 矩阵乘法 矩阵转置 统计数目 平方和求和 分块处理 线程相邻 多block计算 cuda编程并行归约 At ...
- CUDA编程(十)使用Kahan's Summation Formula提高精度
CUDA编程(十) 使用Kahan's Summation Formula提高精度 上一次我们准备去并行一个矩阵乘法.然后我们在GPU上完毕了这个程序,当然是非常单纯的把任务分配给各个线程.也没有经过 ...
随机推荐
- 常用的一些markdown格式
现在工作中,大家都习惯使用markdown写文档.按照其语法来,直接出样式,确实很方便. mac上我使用了macdown工具,只要支持markdown的差不多都一样. 自己经常习惯用的几个语法规则,记 ...
- Ubuntu Server 16.04修改IP、DNS、hosts
本文记录下Ubuntu Server 16.04修改IP.DNS.hosts的方法 -------- 1. Ubuntu Server 16.04修改IP sudo vi /etc/network/i ...
- BZOJ3561 DZY Loves Math VI 莫比乌斯反演
传送门 看到\(gcd\)相关先推式子(默认\(N \leq M\)): \(\begin{align*} \sum\limits_{i=1}^N \sum\limits_{j=1}^M (lcm(i ...
- numpy.loadtxt()
简介 np.loadtxt()用于从文本加载数据. 文本文件中的每一行必须含有相同的数据. loadtxt(fname, dtype=<class 'float'>, comments=' ...
- GC调优入门笔记
想给项目代码做做调优但有许多疑惑,比如有哪些参数要调.怎么调.使用什么工具.调优的效果如何定量测量等.发现Oracle的这份资料不错,简洁直接,回答了我的许多问题,给了许多很实用的大方向上的指导.将其 ...
- quartz获取缓存中所有运行中的Job
原文地址:https://blog.csdn.net/zzm8421/article/details/77769203 Quartz 2.1.5: public static void getAllJ ...
- c++入门之 深入cin
cin 表示输入流,但是究其本质,又能认识到什么呢?先上代码: #include "iostream" };//c++11中使用{}进行重新命名 int main() { usin ...
- Bad Hair Day POJ - 3250 (单调栈入门题)
Some of Farmer John's N cows (1 ≤ N ≤ 80,000) are having a bad hair day! Since each cow is self-cons ...
- ad2017安装以及破解
1.破Ad破解https://wenku.baidu.com/view/5e23a78e2e3f5727a5e962dd.html 2. Ad 汉化https://jingyan.baidu.com/ ...
- 使用HDTune规避硬盘上损坏的扇区
如何使用HDTune扫描磁盘上的错误在网上已经有很多帖子了,但扫描到之后如何用HDTune来规避硬盘上损坏的扇区呢? HDTune并不能直接规避,而是需要重新划分磁盘的卷.HDTune一行有50个小方 ...