day6 note 字典的增删改查(以及setdefault用法补充)
今天的内容主要是join的用法和字典的用法,由于已经有前面的列表作为基础,所以还比较简单,不过因为昨天的作业比较难也比较多,所以作业的讲解占用的时间比较长。我需要好好消化一下作业的部分。
思维导图:

前一天内容回顾:
1:list:li = [1,2,3,5,'a'] 增加:append:末尾加入==追加 insert:插入,在任意位置,insert(index,'内容') extend:迭代着加入,'asc' ----> a,s,c [1,2,3] ---->1,2,3 删除:pop 按索引删除,有返回值 remove:按元素删除 del:del li[0] del li[1:4] del li clear:清空 改:li[0] = 'fdfgdg' li[1:3] = 'abcd' li = [1,a,b,c,d,5,'a'] 查询:按索引,切片,for while等都可以查出。 方法:count 没有切片 sort从小到大,正序,sort(reverse = True)倒叙排序 reverse:反转 index:找出元素的索引位置 可以切片 li = [1,2,[3,4,'taibai','a'],3,5,'a'] li[2][2]=li[2][2].captize
2,元祖。只读,不能更改,儿子不能改,孙子可以改。 可以切片。 3,range(4,12) = [4,5,。。。。11]
py2:xrange range py3:range
前一天作业内容讲解:
li = [1,3,2,'a',4,'b',5,'c']
# print(li[-1])
# print(li[7:])
#
lis = [2,1,'k',['qwe',20,['k1',['tt',3,'']],89],'ab','adv']
'''
1)将列表lis中的’tt’变成大写(用两种方式)。
2)将列表中的数字3变成字符串’100’(用两种方式)。
3)将列表中的字符串’1’变成数字101(用两种方式)。
'''
# lis[3][2][1][0] = 'TT'
# new_str = lis[3][2][1][0].upper()
# lis[3][2][1][0] = new_str
# lis[3][2][1][1] = '100'
# lis[3][2][1][1] = str(lis[3][2][1][1] + 97)
# lis[3][2][1][2] = 101
# print(lis)
# lis[3][2][1][2] = int(lis[3][2][1][2]) + 100
# lis[3][2][1][2] = int(str(10) + lis[3][2][1][2])
lis = str([2,3,'k',['qwe',20,['k1',['tt',3,'']],89],'ab','adv'])
# print(lis,type(lis))
# lis = lis.replace('3','100')
# print(lis)
# li = lis.split(',')
# print(li,type(li))
'''
4,请用代码实现:
li = [‘alex’,’eric’,’rain]
利用下划线将列表的每一个元素拼接成字符串"alex_eric_rain"
'''
#format li = ['alex','eric','rain']
# info = '{}_{}_{}'.format(li[0],li[1],li[2])
# print(info) # li = ['alex','eric','rain']
# msg = ""
# is_first = True
# for item in li:
# if is_first:
# tmp = item
# print(tmp)
# is_first =False
# else:
# tmp = "_" + item
# print(tmp) #'_eric'
# msg += tmp # 'alex_eric'
# print(msg)
# print(msg)
# li = ['alex','eric','rain']
# sb='alex'
# for i in li[1:]:
# sb=sb+"_"+i
# print(sb)
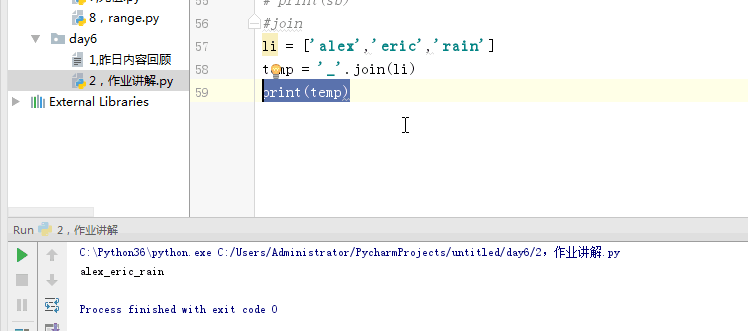
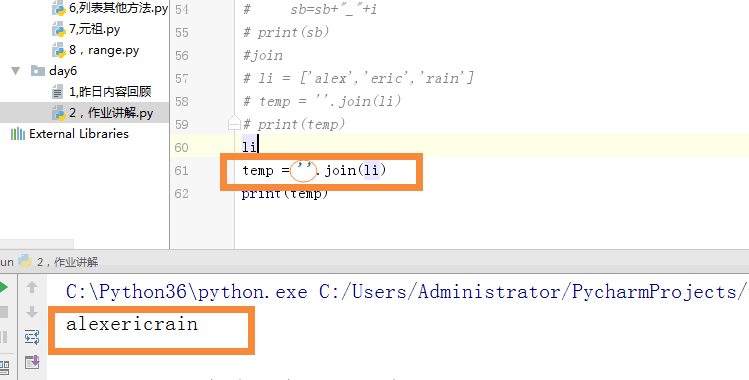
#join
# li = ['alex','eric','rain']
# str(li)
# temp = ''.join(li)
# print(temp)
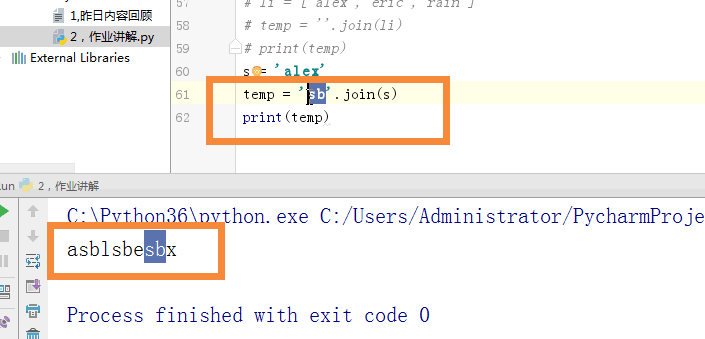
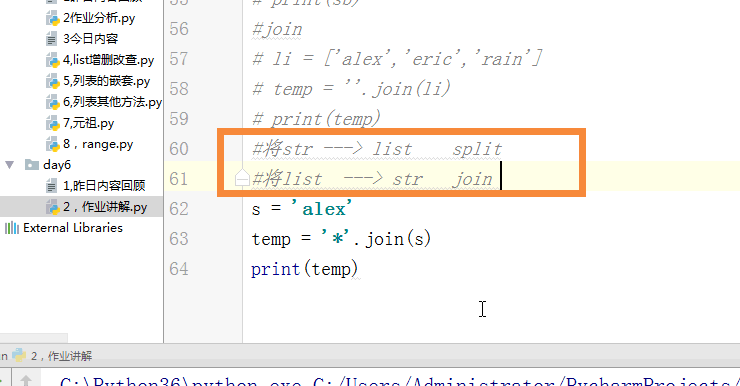
#将str ---> list split
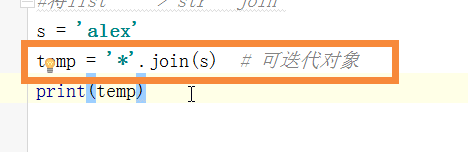
#将list ---> str join
# s = 'alex'
# temp = '*'.join(s) # 可迭代对象
# print(temp)
# li = [1,2]
# li = str(li)
# print(li[1],type(li[1]))
'''
5,查找列表li中的元素,移除每个元素的空格,
并找出以’A’或者’a’开头,并以’c’结尾的所有元素,并添加到一个新列表中,最后循环打印这个新列表。
li = [‘taibai ’,’alexC’,’AbC ’,’egon’,’ Ritian’,’ Wusir’,’ aqc’]
'''
# li = [' taibai ','alexC','AbC ','egon',' Ritian',' Wusir',' aqc']
# l1 = []
# for i in li:
# j = i.strip()
# # if j[0].upper() == 'A' and j[-1] == 'c':
# if j.startswith('A') and j[-1] == 'c':
# l1.append(j)
#
# for k in l1:
# print(k)
# li = ["苍老师","东京热",'武藤兰','波多野结衣']
# new_li = []
# info = input('请输入你的评论') # 苍老师,fdsa东京热
# for i in li:
# if info.find(i) != -1:
# l = len(i)
# info = info.replace(i,'*'*l) #***,fdsa东京热
# new_li.append(info)
# print(new_li) """
7,有如下列表li = [1,3,4’,alex’,[3,7,8,’taibai’],5,’ritian’]
循环打印列表中的每个元素,遇到列表则再循环打印出它里面的元素。
我想要的结果是(用三种方法实现)
"""
li = [1,3,4,'alex',[3,7,8,'taibai'],5,2]
# print('********',li.index([3,7,8,'taibai']))
# new_li = []
# for i in li:
# if type(i) == list: # i == [3,7,8,'taibai']
# index_list = li.index(i) # index_list == li.index([3,7,8,'taibai']) == 4
# new_li = li[:index_list] # new_li = [1,3,4,'alex',]
# new_li.extend(li[index_list]) # [1,3,4,'alex',].extend([3,7,8,'taibai'])
# # new_li = [1,3,4,'alex',3,7,8,'taibai']
# new_li = new_li.extend(li[index_list+1:]) # li[index_list+1:] ==[5,2]
#new_li = [1,3,4,'alex',3,7,8,'taibai',5,2]
# for j in new_li:
# print(j)
# li = [1,2,3]
# l2 = ['a','b','c']
# l3 = li+l2
# print(l3)
l = [1,2,3,'']
l[1] = ['',3,'alex']
print(l) #[1,['2',3,'alex'],3,'4'] [1,'2',3,'alex',3,'4']
l[1:2] = ['',3,'alex']
print(l) li = [1,3,4,'alex',[3,7,8,'taibai'],5,2]
for i in li: ####方法一
if type(i) == list:
index_list = li.index(i) # 4 i = [3,7,8,'taibai']
li[index_list:index_list+1] = i # li[4:5] = [3,7,8,'taibai']
# li = [1,3,4,'alex',3,7,8,'taibai',5,2]
# print(i)
# for j in li:
# print(j)
当天内容讲解:join的使用方法.join可以把列表转换成字符串,得到的字符串可以进行字符串的一切变化和运算。
字典的用法:
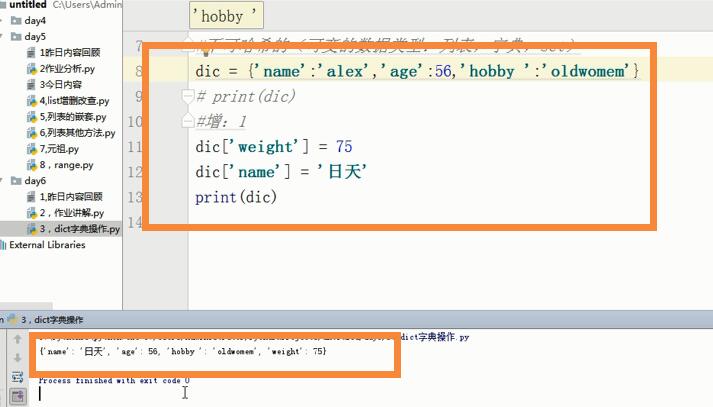
增加的方法有两种,第一种就是在直接在原字典下面叠加字典的格式如下图:叠加后直接打印。当键与原字典相同时自动覆盖,否则直接加在原字典末尾位置。
另一种是用setdefault,例:dic.setdefault('被增加的内容') 如果被增加的内容里有原字典的元素,则覆盖原元素,否则直接增加。
删除用pop,按照键去删除,然后返回删除的内容。如果删除的内容是原字典不存的,会报错,除非设置报错的返回值,如下图:
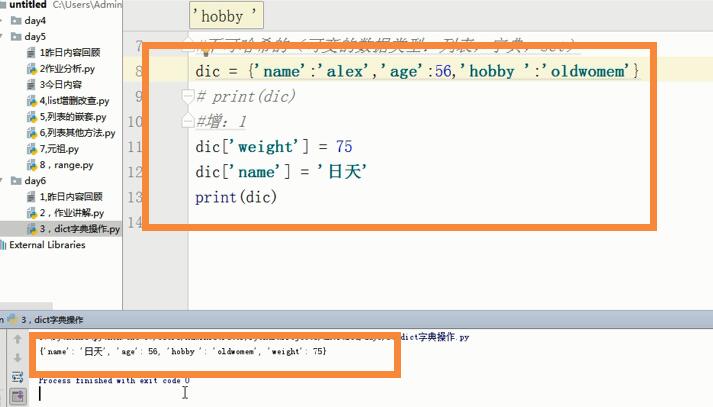
dic = {}
dic['weight'] = 75
dic['name'] = '日天'
print(dic)
{'weight': 75, 'name': '日天'}
删除用pop,按照键去删除,然后返回删除的内容。如果删除的内容是原字典不存的,会报错,除非设置报错的返回值,如下图: 
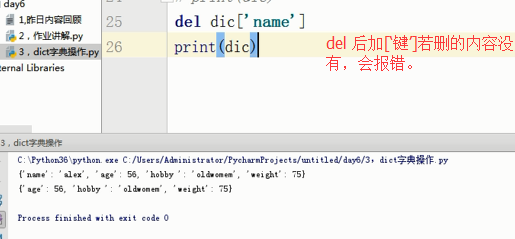
还有删除的方法,clear,清空字典;del dic[‘被删的键’],如果被删的键没有,会报错。
另外有一个方法是随机删除---popitem,几乎不用。
改的方法:直接在原列表下叠加dic[‘键’]=的值如图:直接打印dic得到结果。
dic = {'name':'alex','age':56,'hobby ':'oldwomem'}
dic['name']='jinxing'
print(dic)
{'name': 'jinxing', 'age': 56, 'hobby ': 'oldwomem'}
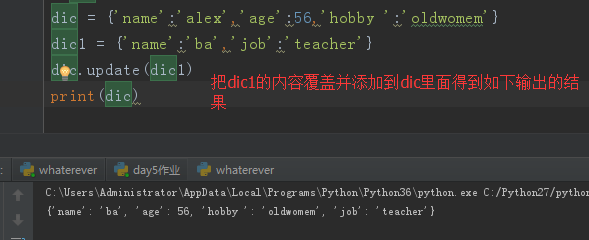
用update改:原有的内容不会改变,否则直接添加。
查的方法:
最直接的方法直接print(dic[‘键’])如果键没有,会报错;还有用get查 :如下图
get直接加get(“键”),若键不存在返回‘none’,不报错。

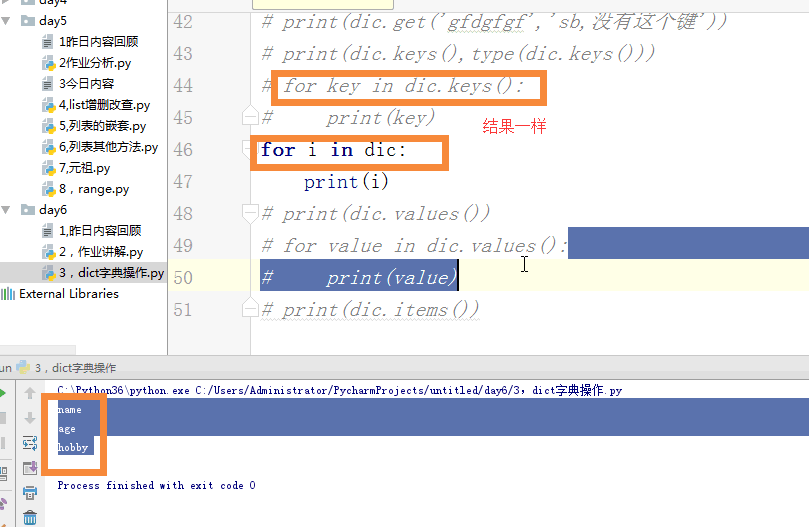
用for循环查询:
#1,字典无序。2,数据关联性强,3键值对。唯一一个映射的数据类型。
# dic = {'name':'jinxin','age':20}
# dic = {'py8期':['晓梅','方胜君',],'py6期':['zhangsan','lisi','wangwu']}
# li = ['alex','taibai','ritian']
# print(dic['name'])
#字典的键必须是可哈希的(不可变的数据类型:字符串,数字,布尔值,元祖)并且是唯一的
#不可哈希的(可变的数据类型:列表,字典,set)
dic = {'name':'alex','age':56,'hobby ':'oldwomem'}
# print(dic)
#增:1
dic['weight'] = 75
# dic['name'] = '日天'
# print(dic) # null
#setdefault 有键值对不做任何改变,没有键值对才添加
# dic.setdefault('k')
# dic.setdefault('name','v')
# print(dic)
#删 pop
# print(dic.pop('name'))
# print(dic.pop('fdsafdsa',None))
# dic.popitem()
# print(dic)
# dic.clear() # 清空
# print(dic)
# del dic['name']
# print(dic)
dic = {'name':'alex','age':56,'hobby ':'oldwomem'}
dic1 = {'name':'barry','job':'teacher'}
#改
# dic['name'] = 'jinxin'
# print(dic)
#update
# dic.update(dic1)
# print(dic)
# print(dic1) # {'name': 'barry', 'job': 'teacher'} #查
# print(dic['name'])
# print(dic['gfgfgfdgf']) # 报错
# print(dic.get('name'))
# print(dic.get('gfdgfgf')) # None
# print(dic.get('gfdgfgf','sb,没有这个键'))
# print(dic.keys(),type(dic.keys()))
# for key in dic.keys():
# print(key)
# for i in dic:
# print(i)
# print(dic.values())
# for value in dic.values():
# print(value)
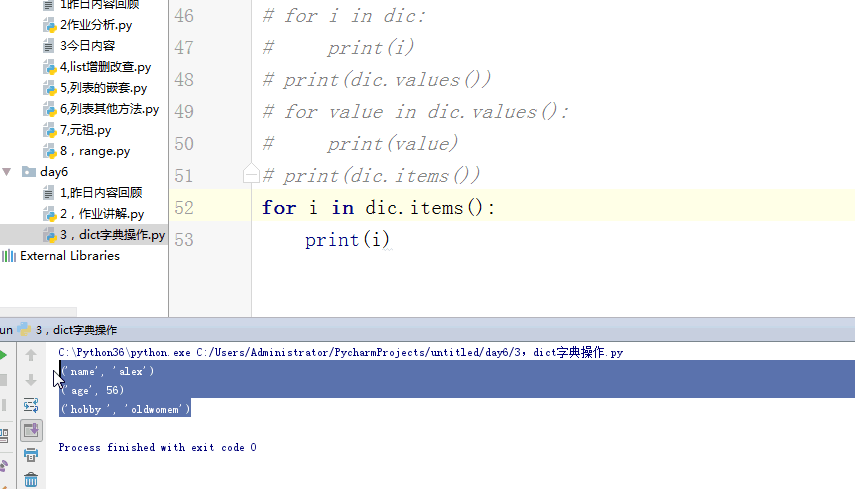
# print(dic.items())
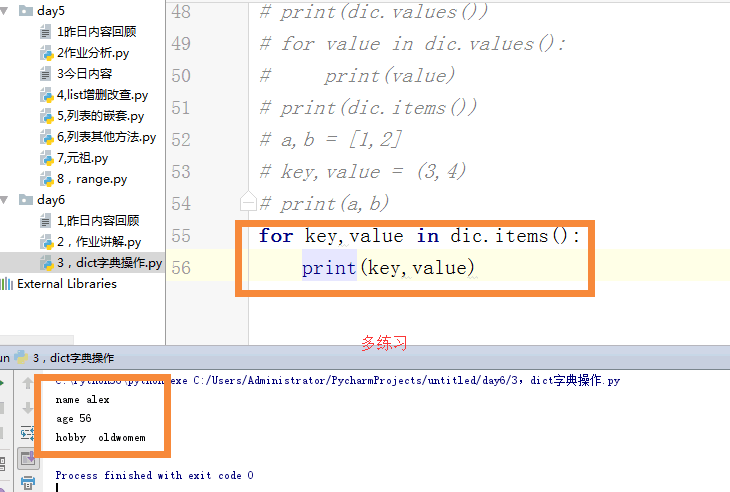
# a,b = [1,2]
# key,value = (3,4)
# print(a,b)
# for key,value in dic.items():
# print(key,value)
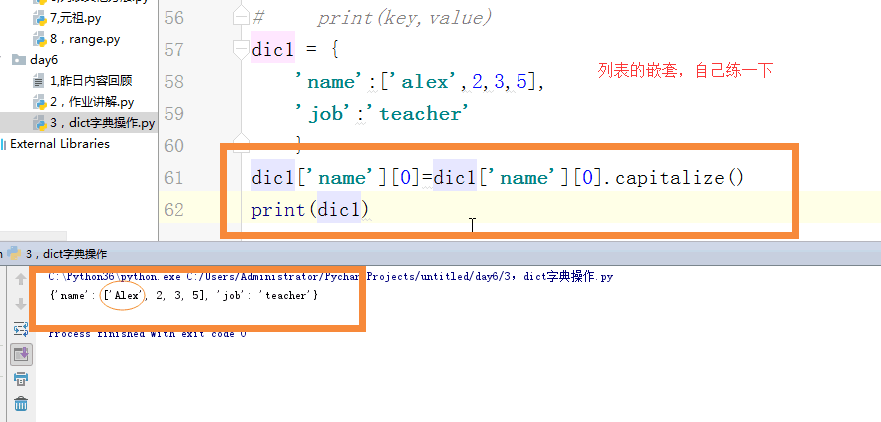
dic1 = {
'name':['alex',2,3,5],
'job':'teacher'
}
dic1['name'][0] = dic1['name'][0].capitalize()
print(dic1)
字典里面,有一个setdefault用法,
我们先来解释一下,它是干什么的,setdefault,是一个默认字典,
1:key存在,则不赋值,key不存在则设置默认值,
2:key存在,返回的是key对应的已有的值,key不存在,返回的则是要设置的默认值,
# d={}
# print(d.setdefault("b",2)) # 2 这里我们的d里面没有值,它就返回设置的默认值,这个时候你给它赋什么值,它就返回什么值给你
# c={"a":111}
# print(c.setdefault("a",2)) # 111 这里我们的c里面有key,返回的就是它自己已有的值,即便你设置了新的值,也不会生效
setdefault源码:
在builtins.py里面,有一个字典类
class dict(object):
def setdefault(self, k, d=None): # real signature unknown; restored from __doc__
""" D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D """
pass
v=dict.fromkeys(['k1','k2'],[])
'''
def fromkeys(*args, **kwargs): # real signature unknown
""" Returns a new dict with keys from iterable and values equal to value. """
pass
'''
我们的fromkeys是把它里面需要的参数迭代组合成一个字典,前面的参数是key,后面的参数是value,就相当于用zip方法把他们给拼接上,
然后就组成了有两个键值对的字典,在下面得到的结果,
v['k1'].append(123)
# print(v) # {'k1': [123], 'k2': [123]}
v['k1']=321 这里是重新对k1这个键进行了赋值,做了更新操作
print(v) # {'k1': 321, 'k2': [123]}
day6 note 字典的增删改查(以及setdefault用法补充)的更多相关文章
- DAY5(PYTHON) 字典的增删改查和dict嵌套
一.字典的增删改查 dic={'name':'hui','age':17,'weight':168} dict1={'height':180,'sex':'b','class':3,'age':16} ...
- 字典(dict),增删改查,嵌套
一丶字典 dict 用{}来表示 键值对数据 {key:value} 唯一性 键 都必须是可哈希的 不可变的数据类型就可以当做字典中的键 值 没有任何限制 二丶字典的增删改查 1.增 dic[k ...
- 2018.8.1 python中字典的增删改查及其它操作
一.字典的简单介绍 1.dict 用{}来表示 键值对数据 {key:value} 唯一性 2.键都必须是可哈希,不可变的数据类型就可以当做字典中的键 值没有任何限制 ...
- python字典的增删改查
字典dict 知识点: {}括起来,以键值对形式存储的容器性数据类型: 键-必须是不可变数据类型,且是唯一的: -值可以是任意数据类型.对象. 优点:关联性强,查询速度快. 缺点:以空间换时间. 字典 ...
- mysql 增删改查最基本用法小结
目录: 1.新建数据库 2.新建数据表 3.查看表结构 4.增删改查 建立一个数据库students 建立一块数据表class1 内容包括: id 主键 自动编号 无符号位 SMALLINT类型 na ...
- ADO.NET 增删改查的基本用法
ADO.NET:数据访问技术 就是将C#和MSSQL连接起来的一个纽带 可以通过ADO.NET将内存中的临时数据写入到数据库中也可以将数据库中的数据提取到内存中供程序调用 所有数据访问技术的基础 连接 ...
- python基础之字典以及增删改查
字典:字典是python中唯一的一个映射类型,主要形式为 dic = {key1:value,key2:value2,....} 字典中key的值是唯一的,主要关系到HASH算法,并且key的值必须是 ...
- 字典的增删改查 daty 5
字典:python中非常重要的数据类型,在python中唯一一个映射的数据类型数据类型分类 按照数据可变与不可变: # 不可变数据类型: int str bool tuple # 可变数据类型: li ...
- python字典的增删改查操作
一.字典 (键值对) 1.字典的基本格式:{key1:1,key2:2} 2.字典里的键必须是不可变的(如:数字,字符串,元组,bool值);值是可变的,可用数字,字符串,列表,字典等. 3.字典里 ...
随机推荐
- iOS 中的block异常 判断block是否为空
我们在调用block时,如果这个block为nil,则程序会崩溃,报类似于EXC_BAD_ACCESS(code=1, address=0xc)异常[32位下的结果,如果是64位,则address=0 ...
- Confluence 6 Oracle 驱动输入你的数据库细节
Confluence 的安装向导将会指导你一步一步的在 Confluence 中配置安装 Oracle 数据库. 使用 JDBC 连接(默认) JDBC 是推荐的连接你的 Confluence 到数据 ...
- Confluence 6 配置 Office 转换器
Office 连接器(Office Connector)允许 Confluence 用户能够查看和编辑从 Microsoft Office 和 Open Office 中导入并附加到页面的内容. Of ...
- 关于python3链接虚拟机MongoDB 遇到的问题总结
pymongo.errors.ServerSelectionTimeoutError: 192.168.12.230:27017: [Errno 61] Connection refused 1.如果 ...
- django 中自定义过滤器
多参数过滤器
- python自动化-unittest批量执行用例(discover)
前言 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了. 加载用例后,用unittest里面的Text ...
- python并发编程之多进程1-----------互斥锁与进程间的通信
一.互斥锁 进程之间数据隔离,但是共享一套文件系统,因而可以通过文件来实现进程直接的通信,但问题是必须自己加锁处理. 注意:加锁的目的是为了保证多个进程修改同一块数据时,同一时间只能有一个修改,即串行 ...
- LeetCode(83): 删除排序链表中的重复元素
Easy! 题目描述: 给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次. 示例 1: 输入: 1->1->2 输出: 1->2 示例 2: 输入: 1->1-&g ...
- laravel 不理解的call方法
返回结果: 原来是调用同控制器的这四个方法之一...vendor\zhiyicx\plus-question\src\API2\Controllers\UserQuestionController.p ...
- web.xml中的ContextLoaderListener和DispatcherServlet区别
ContextLoaderListener和DispatcherServlet都会在Web容器启动的时候加载一下bean配置. 区别在于: DispatcherServlet一般会加载MVC相关的be ...