ReentrantLock和condition源码浅析(一)
转载请注明出处。。。。。
一、介绍
大家都知道,在java中如果要对一段代码做线程安全操作,都用到了锁,当然锁的实现很多,用的比较多的是sysnchronize和reentrantLock,前者是java里的一个关键字,后者是一个java类。这两者的大致区别,在这里罗列下
相同点:
1、都能保证了线程安全性
2、都支持锁的重入
不同点:
1、synchronized适用于不是很激烈的情况,reentranLock适用于比较竞争激烈的情况
2、Synchronized是jvm层面实现的锁机制,而reentranLock是java代码层面实现的锁机制。
3、Reentranlock比synchronized多了锁投票,定时锁,中断锁等机制
4、synchronized是隐式获取锁和释放锁,不需要代码手动获取释放,Reentranlock为显示获取锁和释放锁,必须要手动代码获取释放
要了解reentranlock,那肯定先得会用它,下面通过一个例子来了解它的加锁和释放锁过程
二、demo
public class Demo {
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(15);
for (int i = 0; i < 500; i++){
executorService.execute(() -> {
add();
});
}
Thread.sleep(1000);
System.out.println(count);
}
private static int add(){
return ++count;
}
}
上述代码,安装预期结果 那肯定是500,但是真的是500吗?结果如下

结果很显然,它是小于500的,把这段代码用锁保证结果和预期结果一致。代码如下
public class Demo {
private static int count = 0;
private static Lock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(15);
for (int i = 0; i < 500; i++){
executorService.execute(() -> {
add();
});
}
Thread.sleep(1000);
System.out.println(count);
}
private static int add(){
lock.lock();
try {
return ++count;
}finally {
lock.unlock();
}
}
}

结果,和预期一致。
那它是怎么保证线程安全性的呢。往下看
三、ReentrantLock分析
先来了解这个类的大致结构

红框圈中的三个类,其中Sync是一个抽象类,另外两个是它的子类,Sync又继承了AQS类,所以它也有锁的操作可能性。
FairSync是一个公平锁,NonFairSync是一个非公平锁,它们虽然继承了同一个类,但实现上有所不同,
1、非公平锁获取锁的过程
进入lock方法
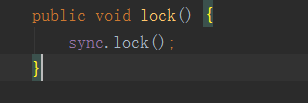
而sync 是ReentrantLock的一个字段,它在该类的构造函数中初始化,它有两个构造函数,sync默认为非公平锁实现,
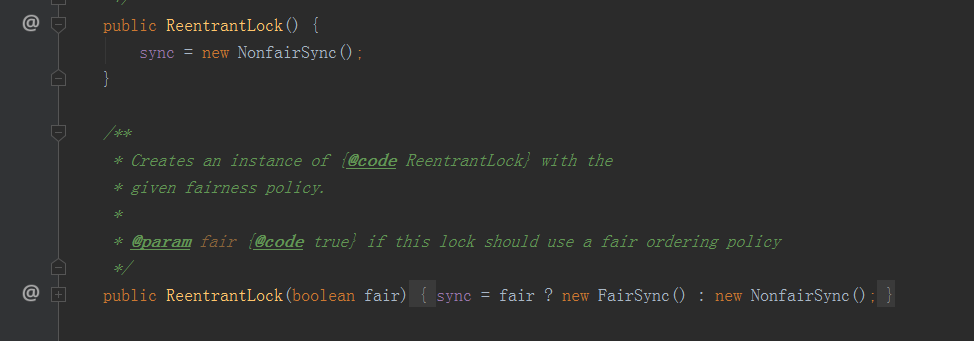
当sync调用了lock方法,也就是调用NonFairSync类的lock方法,继续看下去,下图为该类的结构

lock大致步骤为,先去试着改变state的值,如果改变成功,则state值就变为1了,返回true,失败返回false,先来解释下compareAndSetState方法的作用
它有两个参数,第一个是期望值,第二个是要更新的值,如果内存中state值和期望值相等,则将内存值变为更新值,这是交换成功的标志。如果不相等,那肯定是false。这个方法其实就是CAS,同时它也是线程安全的,具体实现,这里不作讨论。
这里也是获取锁成功的标志,当返回true,则将获取锁的线程置为当前线程,同时state值改变了,如果下一个线程进入,那么该方法肯定是返回false。那么获取锁失败的线程就会进入acquire方法。这个方法其实就是AQS的方法,代码如下,可以看到它又调用了tryAcquire方法,而这个方法的实现就是上一个图的nonFairTryAcquire方法,

1 final boolean nonfairTryAcquire(int acquires) {
2 // 获取当前线程
3 final Thread current = Thread.currentThread();
4 int c = getState();
5 // 如果状态值不为0,则进一步去获取锁
6 if (c == 0) {
7 if (compareAndSetState(0, acquires)) {
8 // 获取锁成功,将锁置给当前线程
9 setExclusiveOwnerThread(current);
10 return true;
11 }
12 }// 如果相等,则表明为锁的重入
13 else if (current == getExclusiveOwnerThread()) {
14 int nextc = c + acquires;
15 if (nextc < 0) // overflow
16 throw new Error("Maximum lock count exceeded");
17 setState(nextc);
18 return true;
19 }
20 // 只有获取锁失败才会返回false
21 return false;
22 }
当上面返回false时,又会相继执行addWaiter和acquireQueued方法,其中addWaiter方法主要是将获取锁失败的线程包装成一个Node节点,插入一个队列中,注意头结点不是该节点,而是new了一个新的node节点,它的状态值为0,然后返回该节点。
具体代码不做分析,下面看acquireQueued方法
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
// 类似while(true),作无限循环作用
for (;;) {
// 获取插入的node节点的前一个节点
final Node p = node.predecessor();
// 如果前继节点为head节点并且获取锁成功,则跳出无限循环,执行相应业务代码
if (p == head && tryAcquire(arg)) {
setHead(node);// 头结点被改变,改变同时其状态也被改变了,节点线程也为空
p.next = null; // help GC
failed = false;
return interrupted;
}
// 前继节点不是头结点或获取锁失败
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
// 防止代码运行过程中,线程突然被中断,中断则将该节点置为取消状态
if (failed)
cancelAcquire(node);
}
}
其中shouldParkAfterFailedAcquire方法做了这两件事,
1、如果p节点前有状态为cancel的节点,则将这些取消的节点放弃掉,简单来说就是排除取消的节点
2、将p节点状态置为signal状态。等待下一次进入该方法可能会被挂起
方法parkAndCheckInterrupt,在shouldParkAfterFailedAcquire返回true的时候,线程会被挂起。、
以上就是获取锁的过程,步骤如下
1、获取锁成功,则将改变state值,并将锁的拥有者置为当前线程
2、获取锁失败,则进入同步队列中,直到获取锁成功或当前线程被外因给中断,获取锁的过程中,有的线程可能会被挂起。
2、非公平锁释放锁的过程
为了不显得过于啰嗦,下面只列出核心代码
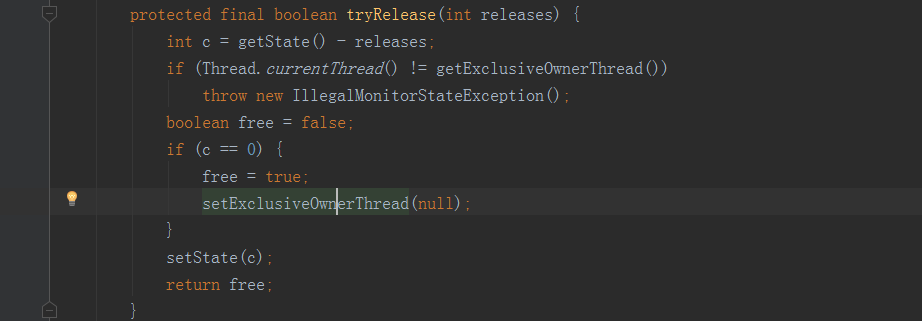
上述代码只有获取锁的线程调用了unlock方法,才会去修改state值,当state值为0时其他线程又可以获取锁,看到这,或许有的小伙伴迷糊了,上面不是介绍说在获取锁的过程中,有的线程会被挂起,那如果挂起的线程node节点前继恰好是头结点,那岂不是运行不了?,莫慌,往下看。当state值置为0时,该方法会返回true,之后会执行下面方法。
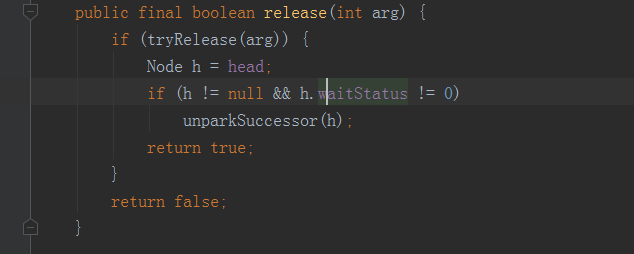
重点方法在unparkSuccessor方法上,看if(h != null && h.waitStatus !=0) ,为什么要加这个判断呢,因为如果有多个线程在获取锁,无论是获取失败,还是获取成功head节点的状态值都被改变(setHead()和shouldParkAfterFailedAcquire()方法会去改变head节点状态)。即不为0,如果为0,那么就说明就没有线程被挂起,自然就不用去释放这些线程。加这个判断,为了减少无用操作。重点来了,unparkSuccessor方法,代码如下
private void unparkSuccessor(Node node) {
// 将node结点状态置为0
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* 如果node结点下一个节点为null或被取消则进入下面的for循环
* 下面的for循环从尾节点往前寻找没有取消的节点 ,直至最靠近node节点,即node节点下一个状态小于等于0的节点
* 在这里node节点就是头结点,
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 找到了该节点,释放该节点的线程
if (s != null)
LockSupport.unpark(s.thread);
}
或许看到这更迷糊了,它释放锁怎么能确定释放的就是那个被挂起的线程呢,这个呢,确实确定不了,但是如果释放前继节点为头结点的线程,那么在后续获取锁的过程中,该线程肯定能获取到锁(因为这段代码是前一个线程释放锁的操作代码,所以下一个线程肯定能获取到锁),至此又一轮循环。
在这里,我对那个为啥从尾节点向前遍历也不清楚,如果有清楚的小伙伴,还请评论下方留言,谢谢!
以上就是非公平锁的释放操作。
3、公平锁的获取锁过程
该种锁和非公平锁的不同之处,就是这种锁一定得按照顺序来获取或,不能前一个线程释放了锁 ,然后谁抢到了就算谁的。
先来看下这种获取锁的代码
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
和非公平锁的不同点是在前者线程释放锁后(即state值为0),非公平锁是谁抢到锁,锁就是谁的,但是公平锁不一样,获取锁的线程会先去判断同步队列中有没有其他线程,如果没有,再去试着改变state值,如果改变成功则获取锁成功,它不允许没进入同步队列中的线程(此时同步队列中已有等待的线程,如果没有,那就是直接抢)抢占锁。下面看下hasQueuedPrdecessor(),代码如下
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
代码不复杂,就是判断同步队列中有没有等待的线程,且等待的线程不是当前线程,有则返回true,没有则返回false。
至于公平锁的释放操作,和非公平锁一致。这里不过多叙述。
获取公平锁操作
1、先判断同步队列中有没有等待的线程。
2、有则放弃锁的争夺,进入同步队列排好队,没有则抢占锁
----------------------------------------------------------------------------------------------------华丽的分界线---------------------------------------------------------------------------------------------------------------------------------
本来想继续写condition,但好像篇幅有点啰嗦,就放在下一篇。
以上就是我的个人见解,如果不足或错误之处,还请指教,谢谢!
ReentrantLock和condition源码浅析(一)的更多相关文章
- ReentrantLock和condition源码浅析(二)
转载请注明出处... 接着上一篇的ReentrantLock和condition源码浅析(一),这篇围绕着condition 一.condition的介绍 在这里为了作对比,引入Object类的两个方 ...
- Java显式锁学习总结之六:Condition源码分析
概述 先来回顾一下java中的等待/通知机制 我们有时会遇到这样的场景:线程A执行到某个点的时候,因为某个条件condition不满足,需要线程A暂停:等到线程B修改了条件condition,使con ...
- ReentrantLock 与 AQS 源码分析
ReentrantLock 与 AQS 源码分析 1. 基本结构 重入锁 ReetrantLock,JDK 1.5新增的类,作用与synchronized关键字相当,但比synchronized ...
- java并发:jdk1.8中ConcurrentHashMap源码浅析
ConcurrentHashMap是线程安全的.可以在多线程中对ConcurrentHashMap进行操作. 在jdk1.7中,使用的是锁分段技术Segment.数据结构是数组+链表. 对比jdk1. ...
- MySQL多版本并发控制机制(MVCC)-源码浅析
MySQL多版本并发控制机制(MVCC)-源码浅析 前言 作为一个数据库爱好者,自己动手写过简单的SQL解析器以及存储引擎,但感觉还是不够过瘾.<<事务处理-概念与技术>>诚然 ...
- 详解AQS中的condition源码原理
摘要:condition用于显式的等待通知,等待过程可以挂起并释放锁,唤醒后重新拿到锁. 本文分享自华为云社区<AQS中的condition源码原理详细分析>,作者:breakDawn. ...
- 【深入浅出jQuery】源码浅析--整体架构
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- 【深入浅出jQuery】源码浅析2--奇技淫巧
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- Struts2源码浅析-ConfigurationProvider
ConfigurationProvider接口 主要完成struts配置文件 加载 注册过程 ConfigurationProvider接口定义 public interface Configurat ...
随机推荐
- Confluence 6 理解你许可证的用户数
基于你的许可证类型,在你 Confluence 可以被注册的用户也许有限制. 在许可证明细页面中,将会告诉当前使用了多少的许可证(你注册的用户数量). 包括仅仅在 Confluence 中可以使用gl ...
- Ribbon服务消费者
springcloud使用到两种消费工具,ribbon和feign ribbon实现了服务的负载均衡 feign默认集成了ribbon,一般情况下使用feign作为消费端 搭建消费者项目(Ribbon ...
- NIO(五)
分散读取,聚集写入 package com.cppdy.nio; import java.io.RandomAccessFile; import java.nio.ByteBuffer; import ...
- Laravel5使用QQ邮箱发送邮件配置
在.env文件中设置如下MAIL_DRIVER=smtpMAIL_HOST=smtp.qq.comMAIL_PORT=465MAIL_USERNAME=00000000000@qq.comMAIL_P ...
- python网络爬虫笔记(一)
一.查询数据字典型数据 1.先说说dictionary查找和插入的速度极快,不会随着key的增加减慢速度,但是占用的内存大 2.list查找和插入的时间随着元素的增加而增加,但还是占用的空间小,内存浪 ...
- JMeter 中对于Json数据的处理方法
JMeter中对于Json数据的处理方法 http://eclipsesource.com/blogs/2014/06/12/parsing-json-responses-with-jmeter/ J ...
- NPOI操作Excel(三)--解析Excel
通过前面两篇的基础学习,我们对NPOI有了一定了了解,下面就开始进入实战,解析下面格式的Excel(下面只是列举了几个例子),并保存入库 首先我们先分析一下,要解析这样的Excel,需要把指标[橘色背 ...
- 数据结构C++实现代码-顺序表
参考:https://blog.csdn.net/ebowtang/article/details/43094041 //seqList.h// //包含顺序表中的声明// #include<i ...
- 饮冰三年-人工智能-linux-07 硬盘分区、格式化及文件系统的管理
先给虚拟机添加一个硬盘 通过fdisk -l sdb,查看磁盘内容 通过fdisk /sdb 来操作分区 创建一个新分区 创建第二个分区 创建第三个分区 创建扩展分区 再次创建分区,其实使用的是扩展分 ...
- linux下配置docker和splash(图文)
所需要环境:ubuntu16.04 第一步用:sudo apt install docker.io 第二步:完成后查看一下有没有成功 命令:docker -v,如果是输入错了写成了大V他会提示你有哪些 ...