htmlUnit加持,网络小蜘蛛的超级进化
前言
前段时间写了个小说线上采集阅读(猛戳这里:https://www.cnblogs.com/huanzi-qch/p/9817831.html),当我们去采集起点网的小说目录时发现目录数据没有在html里面,数据是页面加载时,用ajax请求获取,且对应的div是隐藏的,需要点击“目录”,才看到目录,虽然经过研究最终我们还是找到了接口URL,并通过HttpClient构造post请求获取到了数据,但这种方式太麻烦,成本太大,那有没有其他的方式呢?
htmlUnit简单介绍
通过查找资料发现一个神器:HtmlUnit 官网入口,猛戳这里:http://htmlunit.sourceforge.net
以下介绍摘自官网:
HtmlUnit is a "GUI-Less browser for Java programs". It models HTML documents and provides an API that allows you to invoke pages, fill out forms, click links, etc... just like you do in your "normal" browser.
It has fairly good JavaScript support (which is constantly improving) and is able to work even with quite complex AJAX libraries, simulating Chrome, Firefox or Internet Explorer depending on the configuration used.
It is typically used for testing purposes or to retrieve information from web sites.
HtmlUnit is not a generic unit testing framework. It is specifically a way to simulate a browser for testing purposes and is intended to be used within another testing framework such as JUnit or TestNG. Refer to the document "Getting Started with HtmlUnit" for an introduction.
HtmlUnit is used as the underlying "browser" by different Open Source tools like Canoo WebTest, JWebUnit, WebDriver, JSFUnit, WETATOR, Celerity, Spring MVC Test HtmlUnit, ...
HtmlUnit was originally written by Mike Bowler of Gargoyle Software and is released under the Apache 2 license. Since then, it has received many contributions from other developers, and would not be where it is today without their assistance.
HtmlUnit provides excellent JavaScript support, simulating the behavior of the configured browser (Firefox or Internet Explorer). It uses the Rhino JavaScript engine for the core language (plus workarounds for some Rhino bugs) and provides the implementation for the objects specific to execution in a browser.
中文翻译:
HtmlUnit是一个“Java程序的无界面浏览器”。它为HTML文档建模,并提供一个API,允许您调用页面、填写表单、单击链接等……就像你在“普通”浏览器中所做的一样。
它有相当好的JavaScript支持(不断改进),甚至可以使用非常复杂的AJAX库,根据使用的配置模拟Chrome、Firefox或Internet Explorer。
它通常用于测试或从web站点检索信息。
HtmlUnit不是一个通用的单元测试框架。它是一种专门用于测试目的的模拟浏览器的方法,并打算在其他测试框架(如JUnit或TestNG)中使用。请参阅“开始使用HtmlUnit”文档以获得介绍。
HtmlUnit被不同的开源工具用作底层的“浏览器”,比如Canoo WebTest, JWebUnit, WebDriver, JSFUnit, WETATOR, Celerity, Spring MVC Test HtmlUnit…
HtmlUnit最初是由石像鬼软件的Mike Bowler编写的,在Apache 2许可证下发布。从那以后,它收到了其他开发者的许多贡献,如果没有他们的帮助,它就不会有今天的成就。
HtmlUnit提供了出色的JavaScript支持,模拟了配置好的浏览器(Firefox或Internet Explorer)的行为。它使用Rhino JavaScript引擎作为核心语言(加上一些Rhino bug的解决方案),并为特定于在浏览器中执行的对象提供实现。
代码编写
快速上手,猛戳这里:http://htmlunit.sourceforge.net/gettingStarted.html
maven引包:
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.32</version>
</dependency>
那对应我们之前获取目录,我们可以这样做:
try {
//创建一个WebClient,并模拟特定的浏览器
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_52);
//几个重要配置
webClient.getOptions().setJavaScriptEnabled(true);//激活js
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置Ajax异步
webClient.getOptions().setThrowExceptionOnFailingStatusCode(true);//抛出失败的状态码
webClient.getOptions().setThrowExceptionOnScriptError(true);//抛出js异常
webClient.getOptions().setCssEnabled(false);//禁用css,无页面,无需渲染
webClient.getOptions().setTimeout(10000); //设置连接超时时间
//获取起点中文网书本详情、目录页面
HtmlPage page = webClient.getPage("https://book.qidian.com/info/1209977");
//设置等待js响应时间
webClient.waitForBackgroundJavaScript(5000);
//模拟点击“目录”
page = page.getHtmlElementById("j_catalogPage").click();
//获取页面源代码
System.out.println(page.asXml());
} catch (IOException e) {
e.printStackTrace();
}
效果展示
未执行js之前

经过执行js请求渲染数据,再获取页面源代码,这样我们就能拿到带有目录数据的html了
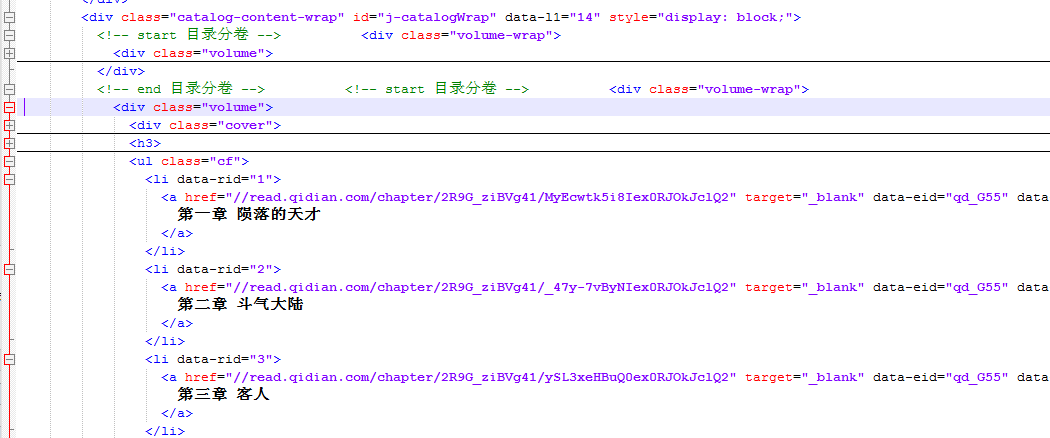
结束语
简单的几行代码就可以看出htmlUnit的强大,理论上,浏览器能做的它都能模拟;在这里先记录下来,等有空了再加到小说线上采集阅读(猛戳这里:https://www.cnblogs.com/huanzi-qch/p/9817831.html)
htmlUnit加持,网络小蜘蛛的超级进化的更多相关文章
- Python网络02 Python服务器进化
原文:Python网络02 Python服务器进化 作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! **注意,在Python 3. ...
- HtmlUnit 开发网络爬虫
网络爬虫第一个要面临的问题,就是如何抓取网页,抓取其实很容易,没你想的那么复杂,一个开源HtmlUnit包,几行代码就OK啦! 通常在一个页面中会包含别的Url,在别的Url当中又会包含更多的Url. ...
- Wi-Fi无线网络下行速度超级慢 (5kb/s)之解决方案
转载:http://www.iplaysoft.com/wifi-slow-solution.html 作者:X-Force 转载原因:该文分类提出了多种解决方案,并详述其原因.简洁清晰,可作为参考方 ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
- [论文阅读]阿里DIEN深度兴趣进化网络之总体解读
[论文阅读]阿里DIEN深度兴趣进化网络之总体解读 目录 [论文阅读]阿里DIEN深度兴趣进化网络之总体解读 0x00 摘要 0x01论文概要 1.1 文章信息 1.2 基本观点 1.2.1 DIN的 ...
- Django REST Framework 数码宝贝 - 3步进化 - 混合类 -->
读了我这篇博客, 你会刷新对面对对象的认知, 之前的面对对象都是LJ~~~ 表结构 class Publisher(models.Model): name = models.CharField(max ...
- NGK公链:在规则明确的环境下运行超级节点机制
首先要跟大家明确的一点是,21个超级节点是投票选举出来的,并不是系统在创立之初就已经确定好了的.那么相信大家也一定很好奇,这21个超级节点是通过什么方式产生? NGK.IO对分布式超级节点使用了一个自 ...
- Block Chain Learning Notes
区块链是什么 区块链技术是由比特币创造的,本文也将从比特币开始进行引导,一步一步告诉大家什么是区块链.如果你想立马知道区块链是什么,也可以直接转到文章末尾的区块链定义. 区块链,可能是当下最有前景又充 ...
- 佛山6397.7539(薇)xiaojie:佛山哪里有xiaomei
佛山哪里有小姐服务大保健[微信:6397.7539倩儿小妹[佛山叫小姐服务√o服务微信:6397.7539倩儿小妹[佛山叫小姐服务][十微信:6397.7539倩儿小妹][佛山叫小姐包夜服务][十微信 ...
随机推荐
- python循环解压rar文件
python循环解压rar文件 C:. │ main.py │ ├─1_STL_算法简介 │ STL_算法简介.rar │ └─2_STL_算法_填充新值 STL_算法_填充新值.rar 事情是这样的 ...
- 公用表表达式 (CTE)、递归、所有子节点、sqlserver
指定临时命名的结果集,这些结果集称为公用表表达式 (CTE).公用表表达式可以包括对自身的引用.这种表达式称为递归公用表表达式. 对于递归公用表达式来说,实现原理也是相同的,同样需要在语句中定义两部分 ...
- kubernetes1.7.6 ha高可用部署
写在前面: 1. 该文章部署方式为二进制部署. 2. 版本信息 k8s 1.7.6,etcd 3.2.9 3. 高可用部分 etcd做高可用集群.kube-apiserver 为无状态服务使用hap ...
- C++输出格式
C++输出格式 C++中默认输出有效位数是6位,即 则输出: 221.111.11011199967 //6位有效数字,自动截取保存六位1.99967e+006 //六位以上且无法省略显示将会变为指数 ...
- css中文字超出文本框,溢出部分用点点点表示
text-overflow 属性规定当文本溢出包含元素时发生的事情.我们可以使用它来对文本超出的部分进行样式的处理. text-overflow: clip|ellipsis|string;包 ...
- python基础自学 第四天
break和continue break:某一条件满足,退出循环,不在执行后续重复代码 continue:某一条件满足时,不执行后续重复的代码 注意:在循环中,如果使用continue这个关键字,使用 ...
- Android-引导用户指纹录入
根据不同的手机,跳转到指纹录入界面,如果没有检测到手机的品牌,就提醒用户手动去指纹录入: 首先描述手机信息检测对象,PhoneInfoCheck.java: package com.esandinfo ...
- 网络编程懒人入门(九):通俗讲解,有了IP地址,为何还要用MAC地址?
1.前言 标题虽然是为了解释有了 IP 地址,为什么还要用 MAC 地址,但是本文的重点在于理解为什么要有 IP 这样的东西.本文对读者的定位是知道 MAC 地址是什么,IP 地址是什么. (本文同步 ...
- Javascript高级编程学习笔记(40)—— DOM(6)CDATASection、DocumentType
CDATASection类型 CDATASection类型是只针对XML文档的类型 因为浏览器无法解析 在浏览器中创建CDATASection的函数也无法正常使用 该类型有以下属性 nodeType: ...
- Rpc框架dubbo-server(v2.6.3) 源码阅读(一)
额,dubbo的前世今生咱就不说了,有用的人都知道.(最新版本已更名 incubator-dubbo,预计版本3.0,不过咱们就先不掺和别人的开发过程了,以v2.6.3为蓝本) 首先,是工作需要,用到 ...