Scala - 快速学习09 - 函数式编程:一些操作
1- 集合类(collection)
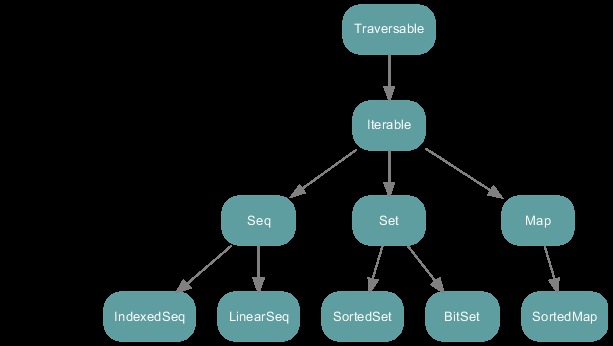
可变集合(Mutable)
不可变集合(Immutable)
- 对不可变集合的操作(修改,添加,删除某个集合元素),都是返回一个新的集合,原来的集合不会发生改变。
- 由于“永远不会被改变”的特性,可以说不可变集合是线程安全的。
- Scala在默认情况下采用的是不可变集合。在使用上,优先使用不可变集合。
- 不可变集合适用于大多数情况。
2- 列表(List)
List[T]
val a = List(1, 2, 3, 4) //> a : List[Int] = List(1, 2, 3, 4)
val b = 0 :: a //> b : List[Int] = List(0, 1, 2, 3, 4) val c = "x" :: "y" :: "z" :: Nil //> c : List[String] = List(x, y, z)
val r0 = "z" :: Nil //> r0 : List[String] = List(z)
val r1 = "y" :: r0 //> r1 : List[String] = List(y, z)
val r2 = "x" :: r1 //> r2 : List[String] = List(x, y, z) val d = a ::: c //> d : List[Any] = List(1, 2, 3, 4, x, y, z)
d.head //> res0: Any = 1
d.tail //> res1: List[Any] = List(2, 3, 4, x, y, z)
d.isEmpty //> res2: Boolean = false
Nil.isEmpty //> res3: Boolean = true def test(tlist: List[Int]): String = {
if (tlist.isEmpty) ""
else tlist.head.toString + " " + test(tlist.tail)
} //> test: (tlist: List[Int])String test(a) //> res4: String = "1 2 3 4 "
val test = List(1, 2, 3, 4, 5) //> test : List[Int] = List(1, 2, 3, 4, 5)
test.filter(x => x % 2 == 1) //> res0: List[Int] = List(1, 3, 5) "Double in 2018!".toList //> res1: List[Char] = List(D, o, u, b, l, e, , i, n, , 2, 0, 1, 8, !)
"Double in 2018!".toList.filter(x => Character.isDigit(x))
//> res2: List[Char] = List(2, 0, 1, 8)
"Double in 2018!".toList.takeWhile(x => x != 'i')
//> res3: List[Char] = List(D, o, u, b, l, e, )
列表的遍历
val list = List(1, 2, 3) //> list : List[Int] = List(1, 2, 3)
for (elem <- list) println(elem) //> 1
//| 2
//| 3
list.foreach(elem => print(elem)) //> 123
list.foreach(print) //> 123
3- 映射(Map)
键值对的集合
val test = Map(1 -> "Anliven", 9 -> "Angel") //> test : scala.collection.immutable.Map[Int,String] = Map(1 -> Anliven, 9 ->
//| Angel)
test(1) //> res0: String = Anliven
test(9) //> res1: String = Angel
test.contains(1) //> res2: Boolean = true
test.contains(2) //> res3: Boolean = false
test.keys //> res4: Iterable[Int] = Set(1, 9)
test.values //> res5: Iterable[String] = MapLike.DefaultValuesIterable(Anliven, Angel) test + (8 -> "888") //> res6: scala.collection.immutable.Map[Int,String] = Map(1 -> Anliven, 9 -> An
//| gel, 8 -> 888)
test - 1 //> res7: scala.collection.immutable.Map[Int,String] = Map(9 -> Angel)
test ++ List(2 -> "222", 3 -> "333") //> res8: scala.collection.immutable.Map[Int,String] = Map(1 -> Anliven, 9 -> An
//| gel, 2 -> 222, 3 -> 333)
test ++ List(2 -> "222", 3 -> "333") -- List(1, 9)
//> res9: scala.collection.immutable.Map[Int,String] = Map(2 -> 222, 3 -> 333)
映射的遍历
val test3 = Map("1" -> "AAA", "2" -> "BBB", "3" -> "CCC")
//> test3 : scala.collection.immutable.Map[String,String] = Map(1 -> AAA, 2 -> B
//| BB, 3 -> CCC)
for ((k, v) <- test3) printf("Key is : %s and Value is: %s\n", k, v)
//> Key is : 1 and Value is: AAA
//| Key is : 2 and Value is: BBB
//| Key is : 3 and Value is: CCC
for (k <- test3.keys) println(k) //> 1
//| 2
//| 3
for (v <- test3.values) println(v) //> AAA
//| BBB
//| CCC
for (x <- test3) println(x) //> (1,AAA)
//| (2,BBB)
//| (3,CCC)
4- Range与Stream
- range 整数序列
- stream 惰性求值列表
1 to 10 //> res0: scala.collection.immutable.Range.Inclusive = Range 1 to 10
1 to 10 by 2 //> res1: scala.collection.immutable.Range = inexact Range 1 to 10 by 2
(1 to 10).toList //> res2: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
1 until 10 //> res3: scala.collection.immutable.Range = Range 1 until 10
1 until 10 by 2 //> res4: scala.collection.immutable.Range = inexact Range 1 until 10 by 2 1 #:: 2 #:: 3 #:: Stream.empty //> res5: scala.collection.immutable.Stream[Int] = Stream(1, ?)
val stream = (1 to 123456789).toStream //> stream : scala.collection.immutable.Stream[Int] = Stream(1, ?)
stream.head //> res6: Int = 1
stream.tail //> res7: scala.collection.immutable.Stream[Int] = Stream(2, ?)
5- Tuple
(1, 2) //> res0: (Int, Int) = (1,2)
1 -> 2 //> res1: (Int, Int) = (1,2)
(1, "Alice", "Math", 95.5) //> res2: (Int, String, String, Double) = (1,Alice,Math,95.5)
val test = (1, "Alice", "Math", 95.5) //> test : (Int, String, String, Double) = (1,Alice,Math,95.5)
test._1 //> res3: Int = 1
test._2 //> res4: String = Alice
test._3 //> res5: String = Math
test._4 //> res6: Double = 95.5 val test2 = List(1, 2, 3, 4, 5) //> test2 : List[Int] = List(1, 2, 3, 4, 5)
def sumSq(in: List[Int]): (Int, Int, Int) =
in.foldLeft((0, 0, 0))((t, v) => (t._1 + 1, t._2 + v, t._3 + v * v))
//> sumSq: (in: List[Int])(Int, Int, Int)
sumSq(test2) //> res7: (Int, Int, Int) = (5,15,55)
6- 集合操作
Map操作与flatMap操作
val test = List[String]("x", "y", "z") //> test : List[String] = List(x, y, z)
test.map(x => x.toUpperCase) //> res0: List[String] = List(X, Y, Z)
test.map(_.toUpperCase) //> res1: List[String] = List(X, Y, Z)
val test2 = List(1, 2, 3, 4, 5) //> test2 : List[Int] = List(1, 2, 3, 4, 5)
test2.filter(x => x % 2 == 1) //> res2: List[Int] = List(1, 3, 5)
test2.filter(_ % 2 == 1) //> res3: List[Int] = List(1, 3, 5)
test2.filter(_ % 2 == 1).map(_ + 10) //> res4: List[Int] = List(11, 13, 15)
val test3 = List(test2, List(6, 7, 8, 9, 0)) //> test3 : List[List[Int]] = List(List(1, 2, 3, 4, 5), List(6, 7, 8, 9, 0))
test3.map(x => x.filter(_ % 2 == 0)) //> res5: List[List[Int]] = List(List(2, 4), List(6, 8, 0))
test3.map(_.filter(_ % 2 == 0)) //> res6: List[List[Int]] = List(List(2, 4), List(6, 8, 0))
test3.flatMap(_.filter(_ % 2 == 0)) //> res7: List[Int] = List(2, 4, 6, 8, 0)
val myStr = List("AAA", "BBB", "CCC") //> myStr : List[String] = List(AAA, BBB, CCC)
myStr flatMap (s => s.toList) //> res0: List[Char] = List(A, A, A, B, B, B, C, C, C)
myStr.flatMap(s => s.toList) //> res1: List[Char] = List(A, A, A, B, B, B, C, C, C)
示例说明:对于列表myStr中的每个元素,都执行Lamda表达式定义的匿名函数“s => s.toList”,myStr中的每个元素都调用toList,生成一个字符集合List[Char],最后,flatMap把这些集合中的元素“拍扁”得到一个集合List。
filter操作
val testMap = Map(11 -> "ABC", 22 -> "BCD", 33 -> "CDE")
//> testMap : scala.collection.immutable.Map[Int,String] = Map(11 -> ABC, 22 ->
//| BCD, 33 -> CDE)
val testFilter = testMap filter { kv => kv._2 contains "BC" }
//> testFilter : scala.collection.immutable.Map[Int,String] = Map(11 -> ABC, 22
//| -> BCD)
testFilter foreach { kv => println(kv._1 + ":" + kv._2) }
//> 11:ABC
//| 22:BCD val testMap2 = Map(1 -> "ab", 2 -> "ac", 3 -> "bc")
//> testMap2 : scala.collection.immutable.Map[Int,String] = Map(1 -> ab, 2 -> a
//| c, 3 -> bc)
val testFilter2 = testMap2 filter { kv => kv._2 startsWith "a" }
//> testFilter2 : scala.collection.immutable.Map[Int,String] = Map(1 -> ab, 2 -
//| > ac)
testFilter2 foreach { kv => println(kv._1 + ":" + kv._2) }
//> 1:ab
//| 2:ac
reduce操作(归约)与fold操作(折叠)
- 使用reduce可以对集合中的元素进行归约,包含reduceLeft和reduceRight两种操作。
- reduceLeft从集合的头部开始操作,reduceRight从集合的尾部开始操作。
- reduce默认采用的是reduceLeft,其原型:reduceLeft(op: (T, T) => T)
val test = List(1, 2, 3, 4, 5) //> test : List[Int] = List(1, 2, 3, 4, 5)
test.reduceLeft((x, y) => x + y) //> res0: Int = 15
test.reduceLeft(_ + _) //> res1: Int = 15
test.reduceRight(_ + _) //> res2: Int = 15
test.reduceLeft(_ - _) //> res3: Int = -13
test.reduceRight(_ - _) //> res4: Int = 3 test.reduce(_ - _) //> res5: Int = -13
- reduceLeft(_ - _)表示从列表头部开始,对两两元素进行求和操作
- reduceRight(_ - _)表示从列表尾部开始,对两两元素进行求和操作
- 下划线是占位符表示当前获取的两个元素,两个下划线之间的是操作符,表示对两个元素进行的操作
- 直接使用reduce,等同于reduceLeft
- foldLeft(),第一个参数为累计值,从集合的头部开始操作。
- foldRight(),第二个参数为累计值,从集合的尾部开始操作。
val test = List(1, 2, 3, 4, 5) //> test : List[Int] = List(1, 2, 3, 4, 5) test.foldLeft(0)(_ + _) //> res0: Int = 15
test.foldRight(0)(_ + _) //> res1: Int = 15
test.foldLeft(0)(_ - _) //> res2: Int = -15
test.foldRight(0)(_ - _) //> res3: Int = 3 test.fold(0)(_ - _) //> res4: Int = -15 test.fold(10)(_ * _) //> res5: Int = 1200
7- 实例WordCount
this is a test !
1,2,3
4,5,6,7,8,9
word2.txt
1,2,3
4,5,6,7,8,9
4,5,6,7,8,9
this is a test !
2 - 编辑并运行如下代码:
package testscala
import java.io.File
import scala.io.Source object TestScala { def main(args: Array[String]): Unit = {
val dirfile = new File("D:\\Anliven-Running\\Zen\\ScalaProjets\\temptest")
val files = dirfile.listFiles //得到数组files
for (file <- files) println(file) //遍历数组
val aFilesList = files.toList //Array类的toList方法将连续存放的数组转换为递归存放的列表
val wordsMap = scala.collection.mutable.Map[String, Int]() //定义一个Map变量,key是单词,value是单词数量 aFilesList.foreach(
file => Source.fromFile(file).getLines().foreach(
line => line.split(" ").foreach(
word => {
if (wordsMap.contains(word)) {
wordsMap(word) += 1
} else {
wordsMap += (word -> 1)
}
}))) println(wordsMap) //打印内容
for ((key, value) <- wordsMap) println(key + ": " + value) //遍历内容
} }
代码说明:
- 如果是在Linux系统下运行,目录格式应为“/d/Anliven-Running/Zen/ScalaProjets/temptest”
- aFilesList.foreach()对列表aFilesList中的每个元素进行遍历操作,按照括号中定义的逻辑进行处理
- file => Source.fromFile(file).getLines().foreach()遍历获取列表aFilesList的元素值(文件路径名)并赋值给file,然后调用getLines()方法获取该文件的所有行,并执行foreach()方法遍历所有行
- line=>line.split(" ").foreach()对一行内容进行切分得到一个集合,然后调用foreach()方法圆括号中定义的处理逻辑遍历集合
- foreach()方法中处理逻辑的功能是,对于当前遍历到的某个单词,如果这个单词以前已经统计过,就把映射中以该单词为key的映射条目的value增加1。如果以前没有被统计过,则为这个单词新创建一个映射条目。
3 - 运行结果:
D:\Anliven-Running\Zen\ScalaProjets\temptest\word1.txt
D:\Anliven-Running\Zen\ScalaProjets\temptest\word2.txt
Map(is -> 2, 1,2,3 -> 2, a -> 2, 4,5,6,7,8,9 -> 3, ! -> 2, this -> 2, test -> 2)
is: 2
1,2,3: 2
a: 2
4,5,6,7,8,9: 3
!: 2
this: 2
test: 2
Scala - 快速学习09 - 函数式编程:一些操作的更多相关文章
- Scala - 快速学习08 - 函数式编程:高阶函数
函数式编程的崛起 函数式编程中的“值不可变性”避免了对公共的可变状态进行同步访问控制的复杂问题,能够较好满足分布式并行编程的需求,适应大数据时代的到来. 函数是第一等公民 可以作为实参传递给另外一个函 ...
- 9、scala函数式编程-集合操作
一.集合操作1 1.Scala的集合体系结构 // Scala中的集合体系主要包括:Iterable.Seq.Set.Map.其中Iterable是所有集合trait的根trai.这个结构与Java的 ...
- Scala学习笔记--函数式编程
一.定义 简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论. 它属于"结构化编程&qu ...
- 大数据技术之_16_Scala学习_04_函数式编程-基础+面向对象编程-基础
第五章 函数式编程-基础5.1 函数式编程内容说明5.1.1 函数式编程内容5.1.2 函数式编程授课顺序5.2 函数式编程介绍5.2.1 几个概念的说明5.2.2 方法.函数.函数式编程和面向对象编 ...
- 大数据技术之_16_Scala学习_09_函数式编程-高级
第十三章 函数式编程-高级13.1 偏函数(partial function)13.1.1 提出一个需求,引出思考13.1.2 解决方式-filter + map 返回新的集合13.1.3 解决方式- ...
- Scala - 快速学习01 - Scala简介
Scala简介 Scala(Scalable Language)是一门多范式(multi-paradigm)编程语言,Scala的设计吸收借鉴了许多种编程语言的思想,具备面向对象编程.函数式编程等特性 ...
- Scala - 快速学习03 - 基础语法
1- 变量 变量 mutable variable 在程序运行过程中其值可能发生改变的量 关键词var定义变量,定义时直接进行求值 常量 immutable variable 在程序运行过程中其值不会 ...
- [学习] 从 函数式编程 到 lambda演算 到 函数的本质 到 组合子逻辑
函数式编程 阮一峰 <函数式编程初探>,阮一峰是<黑客与画家>的译者. wiki <函数编程语言> 一本好书,<计算机程序的构造与解释>有讲到schem ...
- scala快速学习笔记(二):控制结构,类和对象
IV.控制结构 1.if/else 除基本用法外,if/else语句能用来赋值,进而代替?:运算符.这得益于在Scala中,每个语句块都有值,就是该语句块最后一个语句的值.请看下面的代码. def a ...
随机推荐
- 数据库子查询和join的比较
子查询进行SELECT语句嵌套查询,可以一次完成很多逻辑上需要多个步骤才能完成的SQL操作.子查询虽然很灵活,但是执行效率并不高. select goods_id,goods_name from go ...
- jsp页面的html代码显示不出来,提示Uncaught SyntaxError: Unexpected token <
jsp页面的html代码显示不出来,提示Uncaught SyntaxError: Unexpected token < <input type="hidden" na ...
- ZOJ 2507 Let's play a game
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=1507 MisereNim博弈.代码如下: //=========== ...
- maven学习四:maven集成jetty插件发布web项目 标签: maven
http://blog.csdn.net/u014079773/article/details/50167833
- springboot pom.xml记
本文包括: springboot 基本pom.xml配置 热部署 配置打包插件 maven pom.xml配置详解 1. springboot 基本pom.xml配置 <project xmln ...
- 转 Java并发之锁的升级
说明:本文大部分内容来自<并发编程的艺术>,再加上自己网络整理和理解 以下内容来自<java并发编程的艺术>作者:方鹏飞 魏鹏 程晓明 在多线程并发编程中synchronize ...
- js实现(可实现局部打印)
1.js实现(可实现局部打印) <input id="btnPrint" type="button" value="打印" oncli ...
- Unity自动生成AnimatorController
上一篇写了如何自动切割动画,这一篇写如何自动生成AnimatorController. 之前网上查了很多资料,看的一直很蒙,看不懂是怎么回事的,这里我先给大家明确几个概念: 画的不好,大家将就着看,写 ...
- 未能加载文件或程序集“ .....WebUI ”或它的某一个依赖项,试图加载格式不正确的程序
编译Web网站没有问题(需要引用oracle.dataAccess.dll),在运行时报错如下: 解决: 1. 将项目编译生成x86模式(win7 64位) 2. 有可能本机运行有问题,发布到IIS, ...
- java跨域问题
public class SimpleCORSFilter implements Filter{ @Override public void destroy() { } @Override publi ...