phoenix表操作
phoenix表操作
进入命令行,这是sqlline.py 配置到path环境变量的情况下
sqlline.py localhost
如果要退出命令行:!q 或者 !quit
3.4.1 创建表
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
UPSERT INTO us_population (state, city, population) values ('NY','New York',8143197);
UPSERT INTO us_population (state, city, population) values ('CA','Los Angeles',3844829);
在phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
3.4.2 显示所有表
!tables
退出命令行
!quit
具体语法参照官网
https://phoenix.apache.org/language/index.html#upsert_select
3.5 phoenix表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的,如图1和图2,US_POPULATION是在phoenix中直接创建的,而test是在hbase中直接创建的,默认情况下,在phoenix中是查看不到test的。
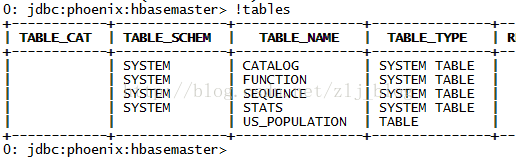
图1 phoenix命令行中查看所有表
如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射。
hbase 中test的表结构如下,两个列簇name、company.
|
Rowkey |
name |
company |
||
|
empid |
firstname |
lastname |
name |
address |
3.5.1 hbase命令行中创建表
$ cd /home/hadoop/hbase/bin
$ ./hbase shell 进入hbase命令行
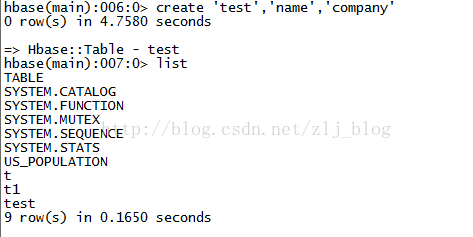
create 'test','name','company' 创建表,如下图
下面的视图映射和表映射均基于该表。
3.5.2 视图映射(不推荐)
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。而且相比于直接创建映射表,视图的查询效率会低,原因是:创建映射表的时候,Phoenix会在表中创建一些空的键值对,这些空键值对的存在可以用来提高查询效率。
1)创建视图
create view"test"(empid varchar primarykey,"name"."firstname" varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);
2)删除视图
drop view "test";
3.5.3 表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
1) 当HBase中表已存在,创建同名表和结构即可
2)当HBase中不存在,可以直接使用create table指令创建需要的表,并且在创建指令中可以根据需要对HBase表结构进行显示的说明。
第1)种情况下,如在之前的基础上已经存在了表,则表映射的语句如下:
create table "HBASE_BMDA5"("SS5" varchar primary key ,
"info"."NodeType" INTEGER ,
"info"."NodeName" varchar,
"info"."IsWarehouse" INTEGER,
"info"."IsAssetUser" INTEGER);
ps1.主键可以任意指定字符串,不可加列族在前,如::: "SS" varchar primary key (正确), "info"."SS" varchar primary key(错误)
ps2:如果phoenix里同时存在"TEST"表,和"test"表,如果要查小写的“test表,表名必须加引号,即select * from "test",如果不加引号,则算是查大写的TEST表
ps3.类型
INTEGER java.lang.Integer -2147483648 to 2147483647 (4 byte )
UNSIGNED_INT java.lang.Integer 0 to 2147483647 (4 byte )
BIGINT java.lang.Long -9223372036854775807 to 9223372036854775807 8 byte
UNSIGNED_LONG java.lang.Long 0 to 9223372036854775807
TINYINT java.lang.Byte -128 to 127 1 byte
UNSIGNED_TINYINT java.lang.Byte 0 to 127 1 byte
SMALLINT java.lang.Short -32768 to 32767 2 byte
UNSIGNED_SMALLINT java.lang.Short 0 to 32767 2 byte
FLOAT java. lang.Float -3.402823466 E + 38 to 3.402823466 E + 38 4 byte
UNSIGNED_FLOAT java.lang.Float -3.402823466 E + 38 to 3.402823466 E + 38 4 byte DOUBLE java.lang.Double -1.7976931348623158 E+308 to 1.7976931348623158 E+308 8 byte
UNSIGNED_DOUBLE java.lang.Double 0 to 1.7976931348623158 E + 308 8 byte
DECIMAL java.math.BigDecimal 38 digits
BOOLEAN java.lang.Boolean
TIME java.sql.Time
DATE java.sql.Date
TIMESTAMP java.sql.Timestamp
UNSIGNED_TIME java.sql.Time
UNSIGNED_DATE java.sql.Date
UNSIGNED_TIMESTAMP java.sql.Timestamp
VARCHAR( precisionInt ) java.lang.String
CHAR ( precisionInt ) java.lang.String
BINARY ( precisionInt ) byte[]
VARBINARY byte[]
然后数据就直接有了.
使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。但是视图就不会,如果删除视图,源数据不会发生改变。
参考:
phoenix表操作的更多相关文章
- Phoenix表和索引分区优化方法
Phoenix表和索引分区,基本优化方法 优化方法 1. SALT_BUCKETS RowKey SALT_BUCKETS 分区 2. Pre-split RowKey分区 3. 分列族 4. 使用压 ...
- Mysql常用表操作 | 单表查询
160905 常用表操作 1. mysql -u root -p 回车 输入密码 2. 显示数据库列表 show databases 3. 进入某数据库 use database data ...
- Sql Server系列:数据表操作
表是用来存储数据和操作数据的逻辑结构,用来组织和存储数据,关系数据库中的所有数据都表现为表的形式,数据表由行和列组成.SQL Server中的数据表分为临时表和永久表,临时表存储在tempdb系统数据 ...
- 学习MySQL之单表操作(二)
##单表操作 ##创建表 CREATE TABLE t_employee( empno ), ename ), job ), MGR ), Hiredate DATE DEFAULT '0000-00 ...
- python——Django(ORM连表操作)
千呼万唤始出来~~~当当当,终于系统讲了django的ORM操作啦!!!这里记录的是django操作数据库表一对多.多对多的表创建及操作.对于操作,我们只记录连表相关的内容,介绍增加数据和查找数据,因 ...
- mysql数据表操作&库操作
首先登陆mysql:mysql -uroot -proot -P3306 -h127.0.0.1 查看所有的库:show databases; 进入一个库:use database; 显示所在的库:s ...
- SQL server基础知识(表操作、数据约束、多表链接查询)
SQL server基础知识 一.基础知识 (1).存储结构:数据库->表->数据 (2).管理数据库 增加:create database 数据库名称 删除:drop database ...
- Python之Django--ORM连表操作
一对多 class UserType(models.Model): caption = models.CharField(max_length=32) class UserInfo(models.Mo ...
- spark使用Hive表操作
spark Hive表操作 之前很长一段时间是通过hiveServer操作Hive表的,一旦hiveServer宕掉就无法进行操作. 比如说一个修改表分区的操作 一.使用HiveServer的方式 v ...
随机推荐
- 新版本微信导致的ios表单bug
解决方法如下: $(document).delegate('input, textarea, select', 'blur', function(){ setTimeout(function(){ $ ...
- 用函数SendARP()获取局域网计算机的MAC地址
sendARP 31 说明对方没有开机,我们的函数检测不到它, 1784 说明的给函数的最后一个参数的值是0,或你的给的值与你给的缓存区大小不符合. 如果返回31不在线,则最后一个参数指针指向的值赋值 ...
- codeforces 416div.2
A CodeForces 811A Vladik and Courtesy B CodeForces 811B Vladik and Complicated Book C CodeFo ...
- python多线程threading下载示例
#coding:utf-8 # windows中测试不通过,下载的图片不完整 # 通过多线程下载图片 import requests import threading class downloader ...
- MySQL数据库的一些方法使用
substring_index(windSpeed,)/3.6 as windSpeed 可将 .8公里.0m/s 进行拆分 嵌套使用replace方法 replace( replace( repla ...
- Mysql按条件计数的几种方法
最近在给某网站的后台添加一系列的统计功能,遇到很多需要按条件计数的情况.尝试了几种方法,下面简要记录,供大家参考. 问题描述 为使讨论简单易懂,我将问题稍作简化,去掉诸多的背景. 从前有一个皇帝,他有 ...
- [C]*和&
一 .& c的&被称为“寻址运算符”,作用是指向某变量的指针: 请看以下代码: int main(void){ int int_1 = 16; printf(" ...
- python PIL实现图片合成
在项目中需要将两张图片合在一起.遇到两种情况,一种就是两张非透明图片的合成, 一种是涉及到透明png的合成. 相关API见 http://pillow.readthedocs.io/en/latest ...
- JVM·垃圾收集器与内存分配策略之对象是否可被回收!
1.判断对象已经死去/不再被引用. 1.1.引用计数算法:给对象添加引用计数器,有个地方引用就+1,引用失效就-1.任何时刻,引用为0,即判断对象死亡. 1.1.1.优点:实现 ...
- python 知识梳理
1.数据类型:字符串,列表,元组,字典,集合.处理每种数据类型的函数 2.判断与循环部分 3.高级函数:lambda,map,reduce,filter 4.自定义模块以及第三方模块 5.函数式编程 ...