CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2)
https://hadoop.apache.org/releases.html
准备工作
关闭防火墙 (也可放行)
# 停止防火墙
systemctl stop firewalld # 关闭防火墙开机自启动
systemctl disable firewalld
修改 hosts 文件,让 hadoop 对应本机 IP 地址 (非 127.0.0.1)
vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6 xxx.xxx.xxx.xxx hadoop
安装 JDK
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
# 解压
tar -zxf /opt/jdk-8u202-linux-x64.tar.gz -C /opt/ # 配置环境变量
vim /etc/profile # JAVA_HOME
export JAVA_HOME=/opt/jdk1..0_202/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH # 刷新环境变量
source /etc/profile # 验证
java -version # java version "1.8.0_202"
# Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
# Java HotSpot(TM) -Bit Server VM (build 25.202-b08, mixed mode)
安装Hadoop
# 解压
tar -zxf /opt/hadoop-2.9.-snappy-.tar.gz -C /opt/ # 配置环境变量
vim /etc/profile # HADOOP_HOME
export HADOOP_HOME=/opt/hadoop-2.9.
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin # 刷新环境变量
source /etc/profile # 验证
hadoop version # 自己编译的,显示可能不一样
# Hadoop 2.9.
# Subversion Unknown -r Unknown
# Compiled by root on --16T09:39Z
# Compiled with protoc 2.5.
# From source with checksum 3a9939967262218aa556c684d107985
# This command was run using /opt/hadoop-2.9./share/hadoop/common/hadoop-common-2.9..jar
配置 Hadoop 伪分布式
一、配置 HDFS
hadoop-env.sh
vim /opt/hadoop-2.9./etc/hadoop/hadoop-env.sh # 配置 JDK 路径
# The java implementation to use.
export JAVA_HOME=/opt/jdk1..0_202/
core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopTmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 默认为true,namenode 连接 datanode 时会进行 host 解析查询 -->
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>true</value>
</property>
</configuration>
启动 hdfs
# 第一次使用需要先格式化一次。之前若格式化过请先停止进程,然后删除文件再执行格式化操作
hdfs namenode -format # 启动 namenode
hadoop-daemon.sh start namenode # 启动 datanode
hadoop-daemon.sh start datanode # 验证,查看 jvm 进程
jps # Jps
# NameNode
# DataNode
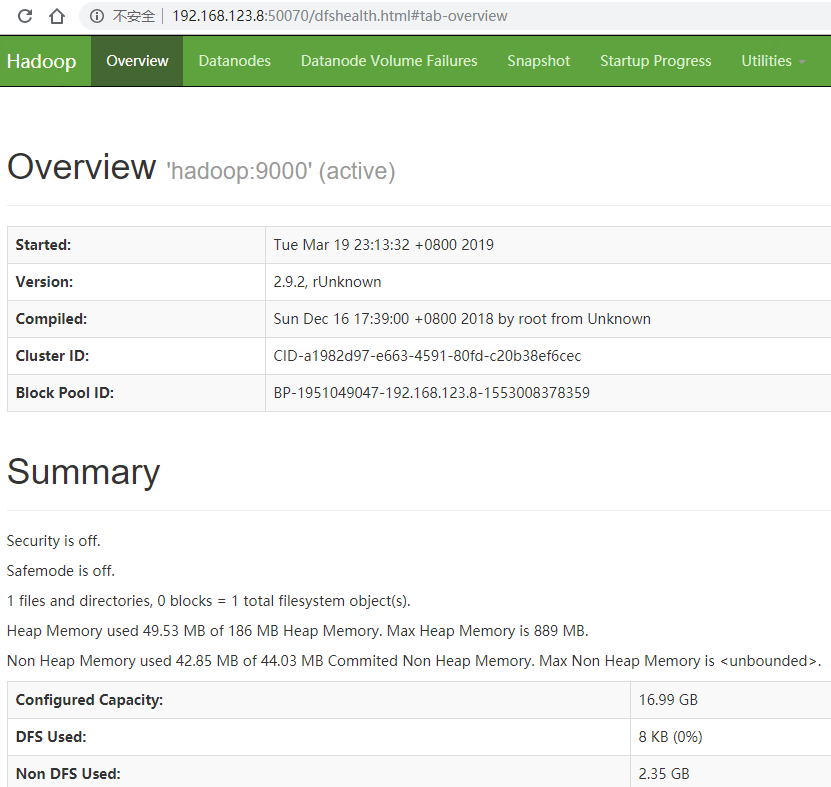
浏览器访问 CentOS 的 IP 地址加端口号 (默认50070) 即可看到 web 端
二、配置 YARN
yarn-env.sh
vim /opt/hadoop-2.9./etc/hadoop/yarn-env.sh # 配置 JDK 路径
# some Java parameters
export JAVA_HOME=/opt/jdk1..0_202/
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
</configuration>
启动 yarn,需保证 hdfs 已启动
# 启动 resourcemanager
yarn-daemon.sh start resourcemanager # 启动 nodemanager
yarn-daemon.sh start nodemanager # 查看 JVM 进程
jps # DataNode
# ResourceManager
# Jps
# NameNode
# NodeManager
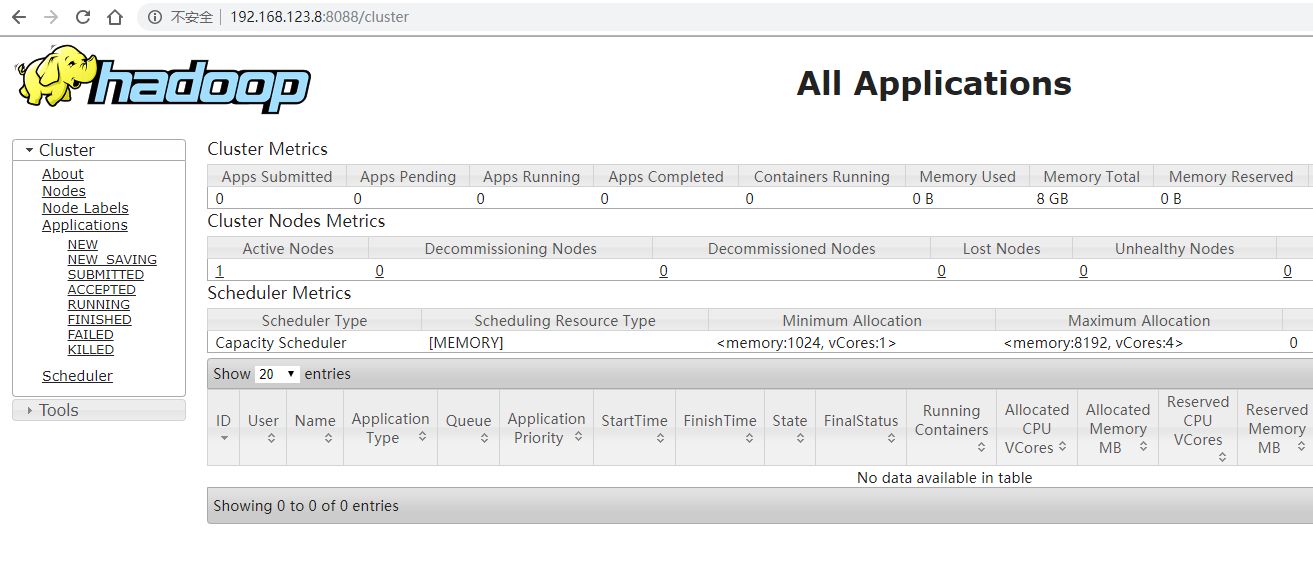
浏览器访问 CentOS 的 IP 地址加端口号 (默认8088) 即可看到 web 端
三、配置 MapReduce
mapred-env.sh
vim /opt/hadoop-2.9./etc/hadoop/mapred-env.sh # 配置 JDK 路径
export JAVA_HOME=/opt/jdk1..0_202/ # when HADOOP_JOB_HISTORYSERVER_HEAPSIZE is not defined, set it.
mapred-site.xml
# 复制一份
cp /opt/hadoop-2.9./etc/hadoop/mapred-site.xml.template /opt/hadoop-2.9./etc/hadoop/mapred-site.xml # 编辑
vim /opt/hadoop-2.9./etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
运行一个 MapReduce 任务
# 计算圆周率
hadoop jar /opt/hadoop-2.9./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9..jar pi # Job Finished in 26.542 seconds
# Estimated value of Pi is 3.14800000000000000000
浏览器访问 CentOS 的 IP 地址加端口号 (默认8088) 可以查看记录

其他配置
四、配置 jobhistory,打开历史记录
mapred-site.xml
<configuration>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop:19888/jobhistory/logs</value>
</property>
</configuration>
# 启动 jobhistory
mr-jobhistory-daemon.sh start historyserver # JVM 进程
jps # NodeManager
# DataNode
# Jps
# NameNode
# ResourceManager
# JobHistoryServer
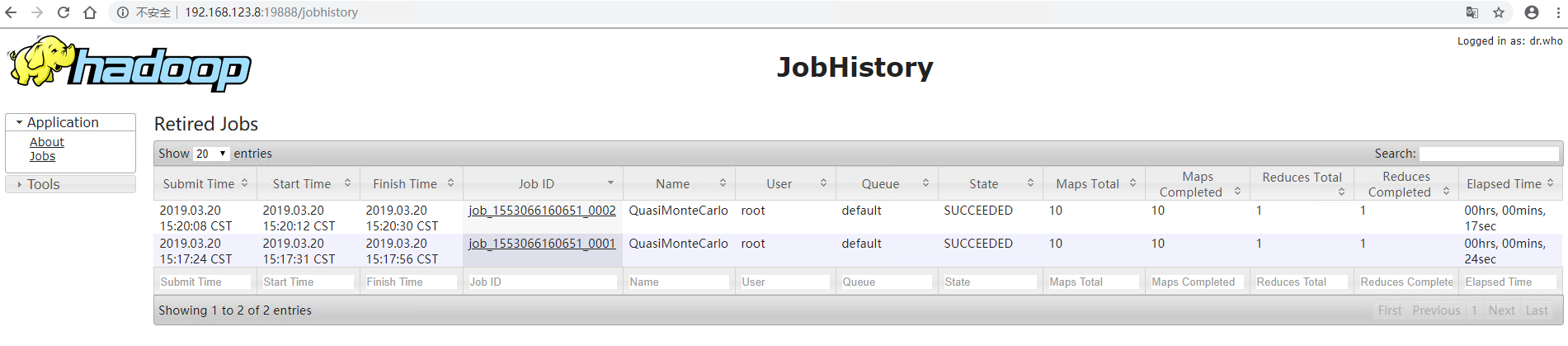
浏览器访问 CentOS 的 IP 地址加端口号 (默认19888) 即可看到 web 端
五、配置 log-aggregation,打开日志聚集,在 web 端可以查看运行详情
yarn-site.xml
<configuration>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志保留时间(7天) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
# 需要重启一遍服务 hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver # 再运行一个任务,就可以看到详情
hadoop jar /opt/hadoop-2.9./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9..jar pi
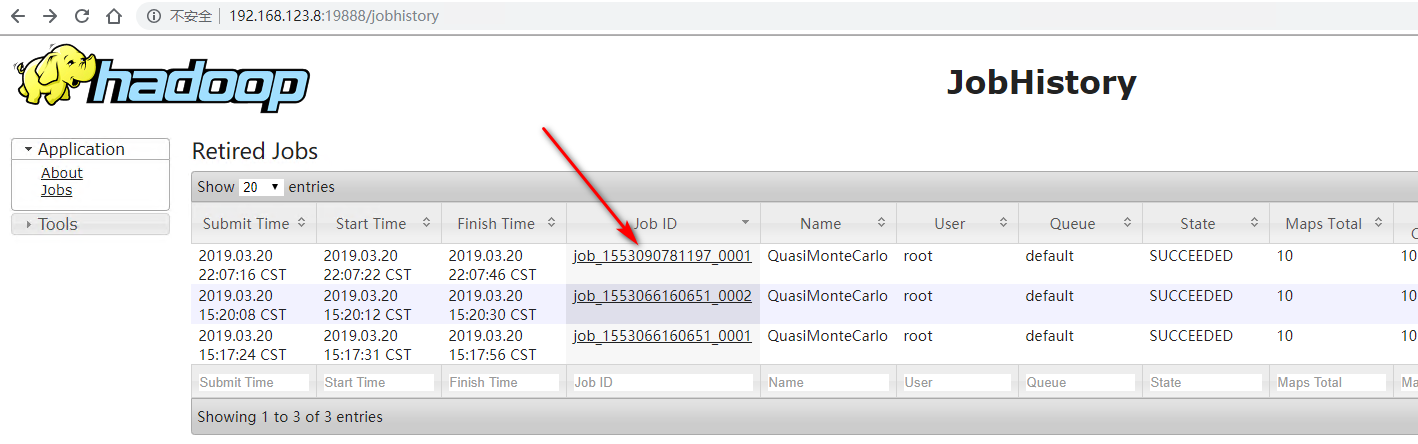
查看刚刚运行的任务详情,未开启日志聚集之前运行的任务无法查看详情
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
CentOS7 下 Hadoop 单节点(伪分布式)部署的更多相关文章
- Win10环境下Hadoop(单节点伪分布式)的安装与配置--bug(yarn的8088端口打不开+)
一.本文思路 [1].配置java环境–JDK12(Hadoop的底层实现语言是java,hadoop运行需要JDK环境) [2].安装Hadoop 1.解压hadop 2.配置hadoop环境变量 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装
实验目的 了解java的安装配置 学习配置对自己节点的免密码登陆 了解hdfs的配置和相关命令 了解yarn的配置 实验原理 1.Hadoop安装 Hadoop的安装对一个初学者来说是一个很头疼的事情 ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- ubantu18.04下Hadoop安装与伪分布式配置
1 下载 下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/stable2/ 2 解压 将文件解压到 /usr/local/hadoop cd ~ ...
- Hadoop单节点启动分布式伪集群
emm~ 写这篇博客只是手痒,因为开发环境用单节点就够了,生产环境肯定是真实集群,所以这个伪分布式纯属娱乐而已. 配置HDFS1. 安装好一台hadoop,可以参考这篇博客.2. 在hadoop目录下 ...
- 单节点伪分布式Hadoop配置
本文所用软件版本: VMware-workstation-full-11.1.0 jdk-6u45-linux-i586.bin ubuntukylin-14.04-desktop-i386.iso ...
- Hbase入门教程--单节点伪分布式模式的安装与使用
Hbase入门简介 HBase是一个分布式的.面向列的开源数据库,该技术来源于 FayChang 所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就像 ...
- 【Hadoop 分布式部署 三:基于Hadoop 2.x 伪分布式部署进行修改配置文件】
1.规划好哪些服务运行在那个服务器上 需要配置的配置文件 2. 修改配置文件,设置服务运行机器节点 首先在 hadoop-senior 的这台主机上 进行 解压 hadoop2.5 按照 ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
随机推荐
- BZOJ1150[CTSC2007]数据备份Backup——模拟费用流+堆+链表
题目描述 你在一家 IT 公司为大型写字楼或办公楼(offices)的计算机数据做备份.然而数据备份的工作是枯燥乏味 的,因此你想设计一个系统让不同的办公楼彼此之间互相备份,而你则坐在家中尽享计算机游 ...
- BZOJ3513[MUTC2013]idiots——FFT+生成函数
题目描述 给定n个长度分别为a_i的木棒,问随机选择3个木棒能够拼成三角形的概率. 输入 第一行T(T<=100),表示数据组数. 接下来若干行描述T组数据,每组数据第一行是n,接下来一行有n个 ...
- BZOJ4372烁烁的游戏——动态点分治+线段树(点分树套线段树)
题目描述 背景:烁烁很喜欢爬树,这吓坏了树上的皮皮鼠.题意:给定一颗n个节点的树,边权均为1,初始树上没有皮皮鼠.烁烁他每次会跳到一个节点u,把周围与他距离不超过d的节点各吸引出w只皮皮鼠.皮皮鼠会被 ...
- DRF 版本和认证
Django Rest Framework 版本控制组件 DRF的版本 版本控制是做什么用的, 我们为什么要用 首先我们要知道我们的版本是干嘛用的呢~~大家都知道我们开发项目是有多个版本的~~ 当我们 ...
- python深度学习库keras——安装
TensorFlow安装keras需要在TensorFlow之上才能运行.所以这里安装TensorFlow.TensorFlow需要vs2015环境,需要wein64位环境,所以32位的小伙伴需要升级 ...
- Joseph POJ - 1012 约瑟夫环递推
题意:约瑟夫环 初始前k个人后k个人 问m等于多少的时候 后k个先出去 题解:因为前k个位置是不动的,所以只要考虑每次递推后的位置在不在前面k个就行 有递推式 ans[i]=(ans[i-1]+m ...
- Katu Puzzle POJ - 3678(水2 - sat)
题意: 有n个未知量,m对未知量之间的关系,判断是否能求出所有的未知量且满足这些关系 解析: 关系建边就好了 #include <iostream> #include <cstdio ...
- wstngfw 初始化的一些配置
wstngfw 初始化的一些配置 1. 引导界面 2. 命令行菜单界面 3. Assign Interfaces (分配接口) Should VLANs be set up now [y|n]? nW ...
- 爬虫_电影天堂 热映电影(xpath)
写了一天才写了不到100行.不过总归是按自己的思路完成了 import requests from lxml import etree import time BASE = 'http://www.d ...
- Dockerfile基础
Dockerfile基础Dockerfile分四部分组成: 基础镜像.维护者信息.镜像操作指令.启动时命令ps: 我的本地镜像已经有centos,若没有请使用docker pull centos 入门 ...