YOLO 从数据集制作到训练
1.图片数据集收集 共 16种
- 集装箱船 container ship
- 散货船 bulker
- 油船 tanker
- 游轮 / 客轮 / 邮轮 passenger liner
- 渔船 fishing boat
- 滚装船 Ro/Ro ship
- 引航船 pilot boat
- LNG船 LNG ship
- LPG船 LPG ship
- 公务船 / 执法船 official ship
- 渡轮 ferry
- 拖船 tug
- 帆船 sailing boat
- 工程船 engineering ship
- 驳船 / 内河船 /江船 / 干货船 / 内陆船 river boat
- 游艇 / 快艇 speedboat
- 木船 wooden boat
首先考虑从相关机构获取优质的数据集 其次爬虫收集(整理图片 删除过小、过大、不符合类别或者损坏的图片)
http://www.shipspotting.com/gallery/photo.php?lid=2987189
标注标签 container ship,bulker,tanker,passenger liner,fishing boat,Ro/Ro ship,pilot boat,LNG ship,LPG ship,official ship,ferry,tug,sailing boat,engineering ship,river boat,speedboat,wooden boat
classes = ["container ship","bulker","tanker","passenger liner","fishing boat","Ro/Ro ship","pilot boat","LNG ship","LPG ship","official ship","ferry,tug","sailing boat","engineering ship","river boat","speedboat","wooden boat"]
obj.names 和 names.list
container ship bulker tanker passenger liner fishing boat Ro/Ro ship pilot boat LNG ship LPG ship official ship ferrytug sailing boat engineering ship river boat speedboat wooden boat
2.图片标注
我使用的是精灵标注助手,标注完之后使用pascal-voc格式进行输出
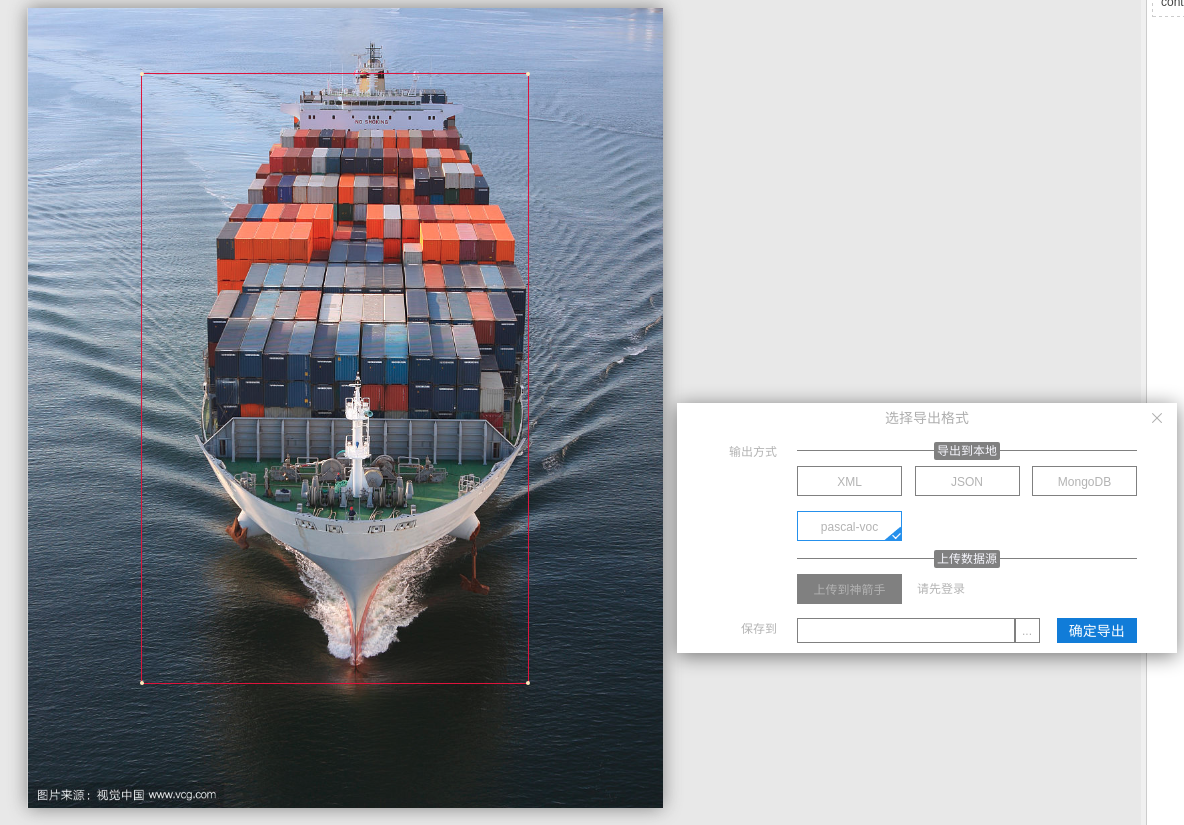
输入格式如下 <name>bulkship</name> 这里的bulkship就是你选择的标注名 后面会用到
<?xml version="1.0" ?>
<annotation>
<folder>ship</folder>
<filename>BulkShip3.jpg</filename>
<path>/home/joe/Desktop/aaa/ship/BulkShip3.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width></width>
<height></height>
<depth></depth>
</size>
<segmented></segmented>
<object>
<name>bulkship</name>
<pose>Unspecified</pose>
<truncated></truncated>
<difficult></difficult>
<bndbox>
<xmin></xmin>
<ymin></ymin>
<xmax></xmax>
<ymax></ymax>
</bndbox>
</object>
</annotation>
3.标注的xml转换成yolo需要的txt格式
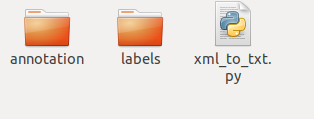
1.将已经标注好的所有xml放进annotation文件夹里面 摆放关系如图
2.运行xml_to_txt.py labels中会得到 yolo所需要的txt格式文件
下面是xml_to_txt.py 代码 注意上面代码中classes = ["containership", "bulkship"] 需要改成你自己训练的标注名集合 (<name>bulkship</name> ) list中的顺序较重要
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["containership", "bulkship"]
def convert(size, box):
dw = ./size[]
dh = ./size[]
x = (box[] + box[])/2.0
y = (box[] + box[])/2.0
w = box[] - box[]
h = box[] - box[]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(path,image_id):
in_file = open(os.path.join(path+r'/annotation/%s.xml'%(image_id))) #input
out_file = open(os.path.join(path+r'/labels/%s.txt'%(image_id)), 'w') #output
tree=ET.parse(in_file) #get xml tree
root = tree.getroot() #get root
size = root.find('size')
w = int(size.find('width').text) #width of image
h = int(size.find('height').text)
for obj in root.iter('object'): #find every object
difficult = obj.find('difficult').text #find difficult
ship_name = obj.find('name').text
:
continue
class_num = classes.index(ship_name)
xmlbox = obj.find('bndbox') #get boundbox
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(class_num) + " " + " ".join([str(a) for a in bb]) + '\n') #
path=os.getcwd()
os.walk(path)
filenames=os.listdir(os.path.join(path+'/annotation'))
isExists=os.path.exists(os.path.join(path+r'/labels/'))
if not isExists:
os.mkdir(os.path.join(path+r'/labels/'))
for filename in filenames:
print(filename)
image_id=filename.split(]
convert_annotation(path,image_id)
运行脚本如图
相应的txt文件

txt内容格式如下
0.53125 0.547752808988764 0.9328358208955224 0.44241573033707865
1代表 第二位 bulkship ( classes = ["containership", "bulkship"] )
其余四个浮点数标示 标记框 中心坐标和 框宽度和长度(具体含义自己百度)
4 暗网整合
1.下载暗网
git clone https://github.com/pjreddie/darknet.git cd darknetmake clean make -j4
把所有的txt格式的标注文件放进
/darknet/data/labels
所有的待图片数据集放进
/darknet/data/images
运行process.py 自动划分 训练集和测试集
# modified
import glob, os
# Current directory
current_dir = os.path.dirname(os.path.abspath(__file__))
# Directory where the data will reside, relative to 'darknet.exe'
path_data = 'images/'
# Percentage of images to be used for the test set
percentage_test = ;
# Create and/or truncate train.txt and test.txt
file_train = open(path_data + '/train.txt', 'w')
file_test = open(path_data + '/test.txt', 'w')
# Populate train.txt and test.txt
counter =
index_test = round( / percentage_test)
for pathAndFilename in glob.iglob(os.path.join(path_data, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test:
counter =
file_test.write("data/" + path_data + title + '.jpg' + "\n")
else:
file_train.write("data/" + path_data + title + '.jpg' + "\n")
counter = counter +
print("ok")
运行完毕会得到两个文件
文件内容类似如下
data/images/ContainerShip786.jpg data/images/BulkShip93.jpg data/images/ContainerShip1255.jpg data/images/BulkShip108.jpg data/images/ContainerShip916.jpg data/images/ContainerShip426.jpg data/images/ContainerShip1371.jpg data/images/ContainerShip1122.jpg data/images/BulkShip71.jpg data/images/BulkShip12.jpg ...
然后新建两个txt文件 obj.names 和 names.list 前者放 /darknet/data/images/ 下 后者放 /darknet/data/
内容参考 你要训练的种类(标注的种类) classes = ["containership", "bulkship"]
格式如下 严格按照 xml_to_txt.py中classes 顺序
然后在/darknet/cfg中新增obj.data
classes= 2 # 你训练的种类 train = data/images/train.txt # 训练集 valid = data/images/test.txt # 测试集 labels = data/images/obj.names #按行摆放的标注的种类名称 backup = backup/ # 每100次迭代存放一次权重的位置
上面可以根据你自己的具体情况修改
2.下载预训练权重
这个主要是卷积部分的预训练权重,使用这个权重可以节省训练时间,直接输入这个命令下载,或者去darknet官网上下载都是可以的。
wget https://pjreddie.com/media/files/darknet53.conv.74 # 这个是yolov3的预训练权重wget https://pjreddie.com/media/files/darknet19_448.conv.23 # 这个是yolov2的预训练权重
以上任选其一
对于权重文件的命名,比如darknet19_448.conv.23,指这个权重文件预先使用darknet19 448x448训练得到,这个darknet19网络有19个卷积层。文件名末尾的conv.23 表示作为待训练网络的预训练权重文件,这个待训练网络的卷积层有23个,而yolov2-voc.cfg中正好有23个卷积层。文件名中的448表示输入的size,通常width=height,这里就说明输入的width=height=448。
yolov3使用预训练权重文件darknet53.conv.74,这个权重文件本身是使用darknet53 448x448 的配置文件训练得到,这个配置文件中有53个卷积层,而darknet53.conv.74作为yolov3-voc.cfg的预训练权重,文件名末尾的conv.74预示着yolov3-voc.cfg中应该有74个卷积层,而事实上,yolov3-voc.cfg中有75的卷积层,这说明,上述说法并不准确,仅仅作为一个大体上的对应
如果你想选择yolov2进行训练
复制 /darknet/cfg/ 中 yolov2-voc.cfg 重命名为 yolo-obj.cfg 并根据自己配置 按照注释 提示 修改内容
[net] # Testing #batch= #subdivisions= # Training batch=64 # 显存大 可设置128 subdivisions=8 # 显存小 就设32 或 64 height= width= channels= momentum=0.9 decay=0.0005 angle= saturation = 1.5 exposure = 1.5 hue=. learning_rate=0.001 burn_in= max_batches = policy=steps steps=, scales=.,. [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [maxpool] size= stride= [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [maxpool] size= stride= [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [maxpool] size= stride= [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [maxpool] size= stride= [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [maxpool] size= stride= [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky ####### [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [route] layers=- [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [reorg] stride= [route] layers=-,- [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] size= stride= pad= filters=35 # filters = (coords +1 +classes)*5 我这里classes=2 filters =35 activation=linear [region] anchors = 1.3221, 1.73145, 3.19275, 4.00944, 5.05587, 8.09892, 9.47112, 4.84053, 11.2364, 10.0071 bias_match= classes=2 # 最后分类的类别数量 coords= num= softmax= jitter=. rescore= object_scale= noobject_scale= class_scale= coord_scale= absolute= thresh = . random=1 # 配置好 可开启 不好设置为0
如果你想选择yolov3进行训练
复制 /darknet/cfg/ 中 yolov3-voc.cfg 重命名为 yolo-obj.cfg 并根据自己配置 按照注释 提示 修改内容
[net] # Testing # batch= # subdivisions= # Training batch=64 # 显存大建议改为128 subdivisions=16 # 显存大改为8 显存小改为32 或者 64 width= height= channels= momentum=0.9 decay=0.0005 angle= saturation = 1.5 exposure = 1.5 hue=. learning_rate=0.001 burn_in= max_batches = policy=steps steps=, scales=.,. [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky # Downsample [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear # Downsample [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear # Downsample [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear # Downsample [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear # Downsample [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [shortcut] activation=linear ###################### [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] size= stride= pad= filters=21 # filters=3*(classes+5) activation=linear [yolo] mask = ,, anchors = ,, ,, ,, ,, ,, ,, ,, ,, , classes=2 # 修改类别数 num= jitter=. ignore_thresh = . truth_thresh = random= [route] layers = - [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [upsample] stride= [route] layers = -, [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] size= stride= pad= filters=21 # filters =3*(classes+5) activation=linear [yolo] mask = ,, anchors = ,, ,, ,, ,, ,, ,, ,, ,, , classes=2 #修改类别 num= jitter=. ignore_thresh = . truth_thresh = random= [route] layers = - [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [upsample] stride= [route] layers = -, [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] batch_normalize= filters= size= stride= pad= activation=leaky [convolutional] batch_normalize= size= stride= pad= filters= activation=leaky [convolutional] size= stride= pad= filters=21 #这里注意修改filters = 3*(classes+5) activation=linear [yolo] mask = ,, anchors = ,, ,, ,, ,, ,, ,, ,, ,, , classes= 2 # 修改类别数 num= jitter=. ignore_thresh = . truth_thresh = random=1 # 显存小改为0
#这个文件的最下面有3个YOLO层,这三个地方的classes做相应修改 #每个YOLO层的上一层的convolutional层(activation=linear)的filters也要修改
5 配置Makefile 如果你的训练指令报错 对半是这里的路径设置问题
按照注释提示 修改内容
GPU=1 #启用gpu训练
CUDNN=1 #启动深度学习加速库
OPENCV=1 # 涉及视频会用到
OPENMP=0
DEBUG=0
ARCH= -gencode arch=compute_61,code=sm_61 \ #这里根据你的显卡去英伟达官网查询算力,不是主流型号会报错
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
# -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
VPATH=./src/:./examples
SLIB=libdarknet.so
ALIB=libdarknet.a
EXEC=darknet
OBJDIR=./obj/
CC=gcc
CPP=g++
NVCC=/usr/local/cuda/bin/nvcc #这里需要格局你自己的目录修改
AR=ar
ARFLAGS=rcs
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON= -Iinclude/ -Isrc/
CFLAGS=-Wall -Wno-unused-result -Wno-unknown-pragmas -Wfatal-errors -fPIC
ifeq ($(OPENMP), 1)
CFLAGS+= -fopenmp
endif
ifeq ($(DEBUG), 1)
OPTS=-O0 -g
endif
CFLAGS+=$(OPTS)
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
LDFLAGS+= `pkg-config --libs opencv` -lstdc++
COMMON+= `pkg-config --cflags opencv`
endif
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda/include/ #这里需要根据你自己的目录修改
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
endif
ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN
CFLAGS+= -DCUDNN
LDFLAGS+= -lcudnn
endif
OBJ=gemm.o utils.o cuda.o deconvolutional_layer.o convolutional_layer.o list.o image.o activations.o im2col.o col2im.o blas.o crop_layer.o dropout_layer.o maxpool_layer.o softmax_layer.o data.o matrix.o network.o connected_layer.o cost_layer.o parser.o option_list.o detection_layer.o route_layer.o upsample_layer.o box.o normalization_layer.o avgpool_layer.o layer.o local_layer.o shortcut_layer.o logistic_layer.o activation_layer.o rnn_layer.o gru_layer.o crnn_layer.o demo.o batchnorm_layer.o region_layer.o reorg_layer.o tree.o lstm_layer.o l2norm_layer.o yolo_layer.o iseg_layer.o image_opencv.o
EXECOBJA=captcha.o lsd.o super.o art.o tag.o cifar.o go.o rnn.o segmenter.o regressor.o classifier.o coco.o yolo.o detector.o nightmare.o instance-segmenter.o darknet.o
ifeq ($(GPU), 1)
LDFLAGS+= -lstdc++
OBJ+=convolutional_kernels.o deconvolutional_kernels.o activation_kernels.o im2col_kernels.o col2im_kernels.o blas_kernels.o crop_layer_kernels.o dropout_layer_kernels.o maxpool_layer_kernels.o avgpool_layer_kernels.o
endif
EXECOBJ = $(addprefix $(OBJDIR), $(EXECOBJA))
OBJS = $(addprefix $(OBJDIR), $(OBJ))
DEPS = $(wildcard src/*.h) Makefile include/darknet.h
all: obj backup results $(SLIB) $(ALIB) $(EXEC)
#all: obj results $(SLIB) $(ALIB) $(EXEC)
$(EXEC): $(EXECOBJ) $(ALIB)
$(CC) $(COMMON) $(CFLAGS) $^ -o $@ $(LDFLAGS) $(ALIB)
$(ALIB): $(OBJS)
$(AR) $(ARFLAGS) $@ $^
$(SLIB): $(OBJS)
$(CC) $(CFLAGS) -shared $^ -o $@ $(LDFLAGS)
$(OBJDIR)%.o: %.cpp $(DEPS)
$(CPP) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.c $(DEPS)
$(CC) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.cu $(DEPS)
$(NVCC) $(ARCH) $(COMMON) --compiler-options "$(CFLAGS)" -c $< -o $@
obj:
mkdir -p obj
backup:
mkdir -p backup
results:
mkdir -p results
.PHONY: clean
clean:
rm -rf $(OBJS) $(SLIB) $(ALIB) $(EXEC) $(EXECOBJ) $(OBJDIR)/*
重新编译
make clean make -j4
6训练
从头开始训练yolov2
./darknet detector train cfg/obj.data cfg/yolo-obj.cfg -gpu | tee train_yolov2.log
从头开始训练yolov3
./darknet detector train cfg/obj.data cfg/yolo-obj.cfg -gpu | tee train_yolov3.log
yolo2训练
sudo ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg darknet19_448.conv. | tee train_log.txt
yolo3训练
sudo ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg darknet53.conv.74 | tee train_log.txt
: images
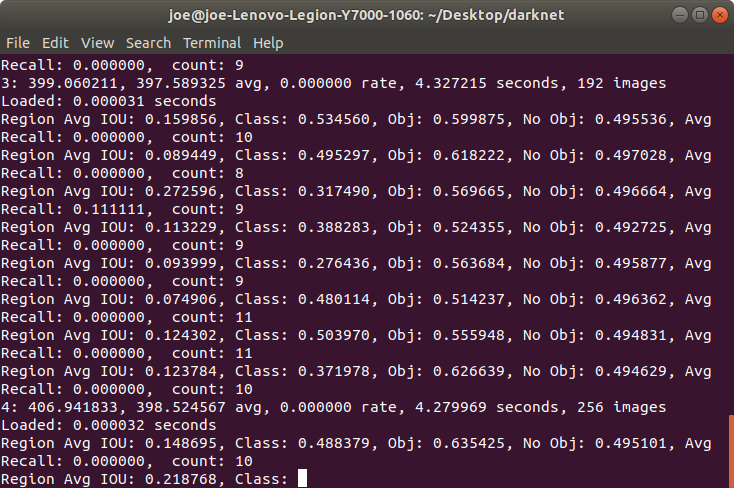
当训练在1-300轮次batch时 avg 会有比较奇怪的从小到大 从大到小的波动 学习率一直显示为0.00000 obj指数一直变小 这是正常的
基本到 600轮次batch后 avg就稳定下来了 obj也会持续变大 不会有那么大的波动差
train_log.txt 具体内容
yolo-obj Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005 Resizing Loaded: 0.000084 seconds Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: : images Loaded: 0.000081 seconds Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: Region Avg IOU: : images Loaded: 0.000090 seconds
class: 标注物体的分类准确率,越大越好,期望值是1.
obj: 越大越好,期望值为1.
no obj:越小越好,期望值为0.
Avg Recall 召回率,召回率=检测出的正样本/实际的正样本
count: 正样本数目.
输出的batch轮次参数中
: images
302: 指示当前训练的迭代次数
16.976120: 是总体的Loss(损失)
16.363884 avg : 是当前平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。
0.000008 rate: 代表当前的学习率,是在.cfg文件中定义的(不同时期学习率不一样)
11.815446 seconds: 表示当前批次训练花费的总时间。
38656 images: 这一行最后的这个数值是1*64的大小,表示到目前为止,参与训练的图片的总量。
参考 自 https://blog.csdn.net/tanmx219/article/details/82906707
https://blog.csdn.net/csdn_zhishui/article/details/85389168
1.cfg文件里的batch就是batch_size,subdivisions只是在显存不足的情况下把batch分批放入训练。 ?现在怀疑batch_size = batch/subdivisions。昨天跑的一个训练如果batch = batch_size的话那大约有80个epoch,但还是明显欠拟合,loss很高。所以还在疑惑???
2.epoch = max_batches/(images/bach) —— 暂时理解应该是这样?
3.max_batches = max_iterations
4.训练的时候batch在小于1000次时每100次保存模型,大于1000后每10000次保存一次模型。可以通过修改/examples/detector.c中的train_detector函数来自己决定多少张图保存一次模型。
5.假设steps = 10000 , scale = .1 ,那意思就是迭代到10000次时学习率衰减10倍。如果调整max_baches的大小,需要同时调整steps,而scale可以自己决定修不修改。
6.训练的时候若数据集小目标较少,106层会大概率输出nan,这是数据集的问题。如果数据集没有问题,可以通过调大batch或者调小learning_rate来解决。(yolo的训练调参略烦)
7.github上暂时还没有发现在pytorch框架下较好用的训练代码,尝试着跑了两个,效果不好,所以还是使用darknet来进行训练。
8.使用voc_label.py输出的是绝对路径。
9.训练的时候用 ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 2>1 | tee person_train.txt 保存训练内容
10.由于数据集的问题没有小目标,尝试使用三个数据集一起训练但大幅输出nan,表示训练很糟糕。所以在原有第一个数据集训练最后保存的模型的基础上,进行后续训练。也就是把预训练权重换成自己的xxx.weights,训练的输出暂时看起来较为正常,等训练完成了看结果好坏。(同时需要调整cfg文件的max_batches,比如第一次训练完保存的是100000次,生成了final.weights,那么接下去训练就需要把cfg调大超过10w次,不然会直接保存。)
YOLO 从数据集制作到训练的更多相关文章
- 图像分割实验:FCN数据集制作,网络模型定义,网络训练(提供数据集和模型文件,以供参考)
论文:<Fully Convolutional Networks for Semantic Segmentation> 代码:FCN的Caffe 实现 数据集:PascalVOC 一 数据 ...
- 小白也能弄得懂的目标检测YOLO系列之YOLOv1网络训练
上期给大家介绍了YOLO模型的检测系统和具体实现,YOLO是如何进行目标定位和目标分类的,这期主要给大家介绍YOLO是如何进行网络训练的,话不多说,马上开始! 前言: 输入图片首先被分成S*S个网格c ...
- Mask-RCNN数据集制作
转自https://blog.csdn.net/pingushen2100/article/details/80513043 一.Mask-RCNN数据集 1.1 训练Mask-RCNN用的到的文件有 ...
- 【猫狗数据集】pytorch训练猫狗数据集之创建数据集
猫狗数据集的分为训练集25000张,在训练集中猫和狗的图像是混在一起的,pytorch读取数据集有两种方式,第一种方式是将不同类别的图片放于其对应的类文件夹中,另一种是实现读取数据集类,该类继承tor ...
- 转载:VOC2007数据集制作
转载自:https://blog.csdn.net/gaohuazhao/article/details/60871886 另外,可参考:https://blog.csdn.net/dcxhun3/a ...
- Fast RCNN 训练自己的数据集(3训练和检测)
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https://github.com/YihangLou/fas ...
- 使用LAP数据集进行年龄训练及估计
一.背景 原本是打算按<DEX Deep EXpectation of apparent age from a single image>进行表面年龄的训练,可由于IMDB-WIKI的数据 ...
- 基于MNIST数据集使用TensorFlow训练一个包含一个隐含层的全连接神经网络
包含一个隐含层的全连接神经网络结构如下: 包含一个隐含层的神经网络结构图 以MNIST数据集为例,以上结构的神经网络训练如下: #coding=utf-8 from tensorflow.exampl ...
- 基于MNIST数据集使用TensorFlow训练一个没有隐含层的浅层神经网络
基础 在参考①中我们详细介绍了没有隐含层的神经网络结构,该神经网络只有输入层和输出层,并且输入层和输出层是通过全连接方式进行连接的.具体结构如下: 我们用此网络结构基于MNIST数据集(参考②)进行训 ...
随机推荐
- ORA-00959: tablespace 'PSAPTEMP' does not exist
错误 : ORA-00959: tablespace 'PSAPTEMP' does not exist 解决办法: CREATE TEMPORARY TABLESPACE PSAPTEMP TEM ...
- JBoss应用服务器清理缓存
旭日Follow_24 的CSDN 博客 ,全文地址请点击: https://blog.csdn.net/xuri24/article/details/82220081 jboss跟tomcat一样, ...
- 9.并发_EJ
第66条: 同步访问共享可变的数据 所谓同步指的发出一个调用时,如果没有得到结果就不返回,直到有结果后再返回.另外相对应的是异步,指的是发出一个调用时就立即返回而不在乎此时有没有结果. 同步和异步关注 ...
- mybatis类型别名
在mybatis中,statement的parameterType指定了输入参数的类型,resultType指定了输出结果的映射类型可以针对parameterType或resultType中指定的类型 ...
- CSS概念【记录】
1.CSS语法 2.@规则 3.注释 4.层叠 5.优先级 6.继承 7.值 8.块格式化上下文 9.盒模型 10.层叠上下文 11.可替换元素 12.外边距合并 13.包含块 14.视觉格式化模型 ...
- 13张动图助你彻底看懂马尔科夫链、PCA和条件概率!
13张动图助你彻底看懂马尔科夫链.PCA和条件概率! https://mp.weixin.qq.com/s/ll2EX_Vyl6HA4qX07NyJbA [ 导读 ] 马尔科夫链.主成分分析以及条件概 ...
- android常犯错误记录(一)
错误:Error:Error: Found item Attr/border_width more than one time 这个容易,属性相同了,按照提示查询一下找出来删了就行了,注意大小写很容易 ...
- View体系之属性动画
(内容省略了valueAnimator和PropertyValueHolder使用) 属性动画的使用的主要方式是AnimatorSet和ObjectAnimator配合使用.ObjectAnimato ...
- C程序
/* 不适用C库函数,只是用 C 语言实现函数 void* memcpy( void *dst, const void *src, size_t len ) memmove 函数的功能是拷贝 src ...
- [Objective-C]编程艺术 笔记整理
看了<禅与 Objective-C 编程艺术>,发现不少平时不注意的或注意但没有系统总结的东西,特此记录一下. 这次没有整理完,后续更新会结合手里的一些其他资料整理. 新博客wossone ...