CatBoost算法和调参
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

catboost官网文档
catboost GPU官方文档
https://catboost.ai/docs/features/training-on-gpu.html
catboost特点:
少量或无需调参,默认参数效果非常好
支持分类变量
支持GPU
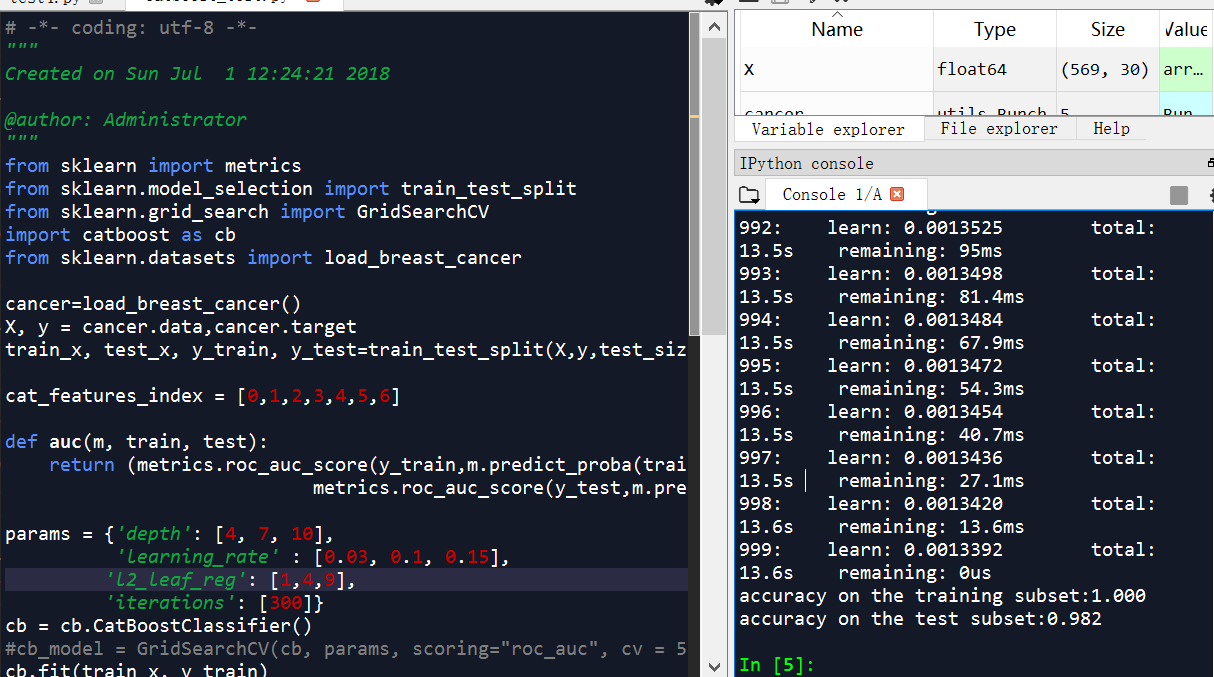
catboost代码举例
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 1 12:24:21 2018 @author: Administrator
"""
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.grid_search import GridSearchCV
import catboost as cb
from sklearn.datasets import load_breast_cancer cancer=load_breast_cancer()
X, y = cancer.data,cancer.target
train_x, test_x, y_train, y_test=train_test_split(X,y,test_size=0.3,random_state=0) cat_features_index = [0,1,2,3,4,5,6] def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1])) params = {'depth': [4, 7, 10],
'learning_rate' : [0.03, 0.1, 0.15],
'l2_leaf_reg': [1,4,9],
'iterations': [300]}
cb = cb.CatBoostClassifier()
#cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv = 5)
cb.fit(train_x, y_train) print("accuracy on the training subset:{:.3f}".format(cb.score(train_x,y_train)))
print("accuracy on the test subset:{:.3f}".format(cb.score(test_x,y_test)))
'''
accuracy on the training subset:1.000
accuracy on the test subset:0.982
'''
俄罗斯最大搜索引擎Yandex开源了一款梯度提升机器学习库CatBoost
摘要: 俄罗斯搜索巨头Yandex宣布,将向开源社区提交一款梯度提升机器学习库CatBoost。它能够在数据稀疏的情况下“教”机器学习。特别是在没有像视频、文本、图像这类感官型数据的时候,CatBoost也能根据事务型数据或历史数据进行操作。
据开发者所说超越Lightgbm和XGBoost的又一个神器,不过具体性能,还要看在比赛中的表现了。
整理一下里面简单的教程和参数介绍,很多参数不是那种重要,只解释部分重要的参数,训练时需要重点考虑的。
import numpy as np
import catboost as cb train_data = np.random.randint(0, 100, size=(100, 10))
train_label = np.random.randint(0, 2, size=(100))
test_data = np.random.randint(0,100, size=(50,10)) model = cb.CatBoostClassifier(iterations=2, depth=2, learning_rate=0.5, loss_function='Logloss',
logging_level='Verbose')
model.fit(train_data, train_label, cat_features=[0,2,5])
preds_class = model.predict(test_data)
preds_probs = model.predict_proba(test_data)
print('class = ',preds_class)
print('proba = ',preds_probs)
参数
CatBoostClassifier/CatBoostRegressor
通用参数
learning_rate(eta)=automatically
depth(max_depth)=6: 树的深度
l2_leaf_reg(reg_lambda)=3 L2正则化系数
n_estimators(num_boost_round)(num_trees=1000)=1000: 解决ml问题的树的最大数量
one_hot_max_size=2: 对于某些变量进行one-hot编码
loss_function=’Logloss’:
RMSE
Logloss
MAE
CrossEntropy
custom_metric=None
RMSE
Logloss
MAE
CrossEntropy
Recall
Precision
F1
Accuracy
AUC
R2
eval_metric=Optimized objective
RMSE
Logloss
MAE
CrossEntropy
Recall
Precision
F1
Accuracy
AUC
R2
nan_mode=None:处理NAN的方法
Forbidden
Min
Max
1
2
3
leaf_estimation_method=None:迭代求解的方法,梯度和牛顿
Newton
Gradient
1
2
random_seed=None: 训练时候的随机种子
---------------------
性能参数
thread_count=-1:训练时所用的cpu/gpu核数
used_ram_limit=None:CTR问题,计算时的内存限制
gpu_ram_part=None:GPU内存限制
处理单元设置
task_type=CPU:训练的器件
devices=None:训练的GPU设备ID
counter_calc_method=None,
leaf_estimation_iterations=None,
use_best_model=None,
verbose=None,
model_size_reg=None,
rsm=None,
logging_level=None,
metric_period=None,
ctr_leaf_count_limit=None,
store_all_simple_ctr=None,
max_ctr_complexity=None,
has_time=None,
classes_count=None,
class_weights=None,
random_strength=None,
name=None,
ignored_features=None,
train_dir=None,
custom_loss=None,
bagging_temperature=None
border_count=None
feature_border_type=None,
save_snapshot=None,
snapshot_file=None,
fold_len_multiplier=None,
allow_writing_files=None,
final_ctr_computation_mode=None,
approx_on_full_history=None,
boosting_type=None,
simple_ctr=None,
combinations_ctr=None,
per_feature_ctr=None,
device_config=None,
bootstrap_type=None,
subsample=None,
colsample_bylevel=None,
random_state=None,
objective=None,
max_bin=None,
scale_pos_weight=None,
gpu_cat_features_storage=None,
data_partition=None
CatBoostClassifier
属性(attribute):
is_fitted_
tree_count_
feature_importances_
random_seed_
方法(method):
fit
X: 输入数据数据类型可以是,list; pandas.DataFrame; pandas.Series
y=None
cat_features=None: 拿来做处理的类别特征
sample_weight=None: 输入数据的样本权重
logging_level=None: 控制是否输出日志信息,或者何种信息
plot=False: 训练过程中,绘制,度量值,所用时间等
eval_set=None: 验证集合,数据类型list(X, y)tuples
baseline=None
use_best_model=None
verbose=None
predict
返回验证样本所属类别,数据类型为np.array
predict_proba
返回验证样本所属类别的概率,数据类型为np.array
get_feature_importance
eval_metrics
save_model
load_model
get_params
score
教程(tutorial)

catboost GPU版本
https://catboost.ai/docs/features/training-on-gpu.html
Training on GPU
CatBoost supports training on GPUs.
Choose the implementation for more details on the parameters that are required to start training on GPU.

Note. Other training parameters are also available. Some of them are CPU-specific or GPU-specific. See the Python package training parameters section for more details.
For example, use the following code to train a classification model on GPU:
GPU版本测试
# -*- coding: utf-8 -*-
"""
Created on Wed May 29 10:34:20 2019 @author: Administrator
GPU
1m -1m 2s
CPU
28.7s-28.8s
""" from catboost import CatBoostClassifier train_data = [[0, 3],
[4, 1],
[8, 1],
[9, 1]]
train_labels = [0, 0, 1, 1] model = CatBoostClassifier(task_type = "GPU")
#model = CatBoostClassifier()
model.fit(train_data,
train_labels)
# -*- coding: utf-8 -*-
"""
Created on Wed May 22 10:50:59 2019 @author: Administrator
CPU版本:3m 30s-3m 40s
GPU版本:3m 33s-3m 34s
""" from sklearn import metrics
from sklearn.model_selection import train_test_split
import catboost as cb
from sklearn.datasets import load_breast_cancer cancer=load_breast_cancer()
X, y = cancer.data,cancer.target
train_x, test_x, y_train, y_test=train_test_split(X,y,test_size=0.3,random_state=0)
cb = cb.CatBoostClassifier()
#cb = cb.CatBoostClassifier(task_type="CPU")
#cb = cb.CatBoostClassifier(task_type="GPU")
cb.fit(train_x, y_train)
Python package installation
Installation is only supported by the 64-bit version of Python.
- Choose an installation method:
(Optionally) Install additional packages for data visualization support.
- (Optionally) Test CatBoost.
Note that there are additional system requirements if training on GPU is required.
GPU system requirements
The versions of CatBoost available from pip install and conda install have GPU support out-of-the-box.
Devices with compute capability 3.0 and higher are supported in compiled packages.
Training on GPU requires NVIDIA Driver of version 390.xx or higher.
- Step 4 of the Build from source on Linux and macOS operation.
- Step 3 of the Build from source on Windows operation.
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频,含catboost算法讲解)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

欢迎扫描和关注博主主页,学习python视频资源

CatBoost算法和调参的更多相关文章
- 调参、最优化、ml算法(未完成)
最优化方法 调参方法 ml算法 梯度下降gd grid search lr 梯度上升 随机梯度下降 pca 随机梯度下降sgd 贝叶斯调参 lda 牛顿算法 knn 拟牛顿算法 kmeans ...
- 自动调参库hyperopt+lightgbm 调参demo
在此之前,调参要么网格调参,要么随机调参,要么肉眼调参.虽然调参到一定程度,进步有限,但仍然很耗精力. 自动调参库hyperopt可用tpe算法自动调参,实测强于随机调参. hyperopt 需要自己 ...
- k-近邻算法采用for循环调参方法
//2019.08.02下午#机器学习算法中的超参数与模型参数1.超参数:是指机器学习算法运行之前需要指定的参数,是指对于不同机器学习算法属性的决定参数.通常来说,人们所说的调参就是指调节超参数.2. ...
- LightGBM 调参方法(具体操作)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- sklearn逻辑回归(Logistic Regression,LR)调参指南
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- scikit-learn随机森林调参小结
在Bagging与随机森林算法原理小结中,我们对随机森林(Random Forest, 以下简称RF)的原理做了总结.本文就从实践的角度对RF做一个总结.重点讲述scikit-learn中RF的调参注 ...
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- word2vec参数调整 及lda调参
一.word2vec调参 ./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -neg ...
- 漫谈PID——实现与调参
闲话: 作为一个控制专业的学生,说起PID,真是让我又爱又恨.甚至有时候会觉得我可能这辈子都学不会pid了,但是经过一段时间的反复琢磨,pid也不是很复杂.所以在看懂pid的基础上,写下这篇文章,方便 ...
随机推荐
- Nginx 当上游服务器返回失败时的处理办法
陶辉95课 Syntax: proxy_next_upstream error | timeout | invalid_header | http_500 | http_502 | http_503 ...
- C语言实现字符串逆序输出
方法一: #include <stdio.h> #include <stdlib.h> #include <string.h> void Reverse(char ...
- SpringBoot2.0.3 + SpringSecurity5.0.6 + vue 前后端分离认证授权
新项目引入安全控制 项目中新近添加了Spring Security安全组件,前期没怎么用过,加之新版本少有参考,踩坑四天,终完成初步解决方案.其实很简单,Spring Security5相比之前版本少 ...
- centos部署nextcloud
简介 Nextcloud是一套用于创建和使用文件托管服务的客户端-服务器软件.它在功能上类似于Dropbox,虽然Nextcloud是免费的和开源的,允许任何人在私人服务器上安装和操作它.与Dropb ...
- 「2017 Multi-University Training Contest 2」2017多校训练2
1001 Is Derek lying 题目链接 HDU6045 Is Derek lying? 给出两个人选择题的回答,问得分分别为x和y是否可能.(\(1\le N \le 80000,0\le ...
- LGP2801 教主的魔法
题目链接 : P2801 教主的魔法 这是第一次A分块的题 就是模板题了 每个块内排序 每个整块仅需维护整块的修改量 询问操作: 对于边缘块 直接暴力找在[l, r]内 且比给定值大的有几个 对于整块 ...
- zabbix 自动发现端口并添加监控设置
自动发现端口并添加监控设置UserParameter=net.listen.discovery,sudo /etc/zabbix/scripts/discovery_listport.sh #!/bi ...
- 【BZOJ3576】江南乐(博弈论)
[BZOJ3576]江南乐(博弈论) 题面 BZOJ 洛谷 题解 无论一堆石头怎么拆分,都并不能改变它是一个\(Multi-SG\)的事实. 既然每一组的\(F\)都是固定的,那么我们预处理所有的可能 ...
- 【CF865D】Buy Low Sell High(贪心)
[CF865D]Buy Low Sell High(贪心) 题面 洛谷 CF 题解 首先有一个\(O(n^2)\)的\(dp\)很显然,设\(f[i][j]\)表示前\(i\)天手中还有\(j\)股股 ...
- 【BZOJ5293】[BJOI2018]求和(前缀和,LCA)
[BZOJ5293][BJOI2018]求和(前缀和,LCA) 题面 BZOJ 洛谷 题解 送分题??? 预处理一下\(k\)次方的前缀和. 然后求个\(LCA\)就做完了?... #include& ...