Kafka学习笔记-如何保证高可用
一、术语
1.1 Broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。
如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
1.2 Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
1.3 Partition
topic中的数据分割为一个或多个partition。
partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。或者需要保证按业务类型顺序消费的情况,则按业务类型发到同一分区,来保证对应业务类型内的顺序处理。
1.4 Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。
生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
1.5 Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
1.6 Consumer Group
每个Consumer属于一个特定的Consumer Group。同一组内topic的一条消息,只有一个消费者能消费到。
1.7 Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
1.8 Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。
二、架构
2.1 拓扑结构
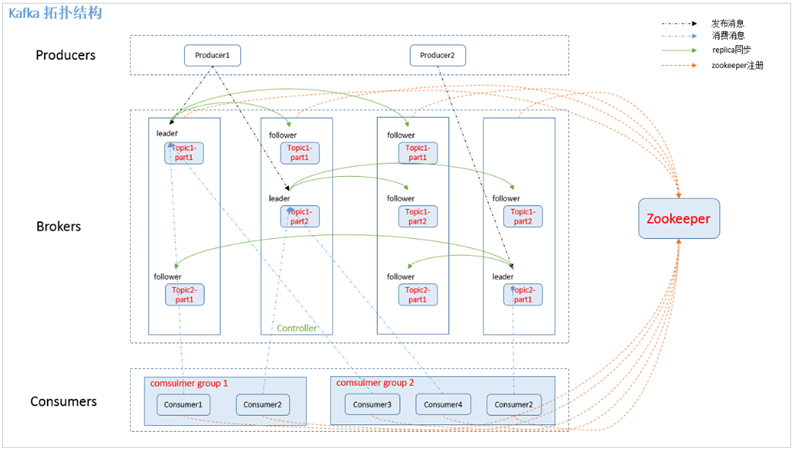
如上图所示,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。
Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。
Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
2.2 Topics和Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。
为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
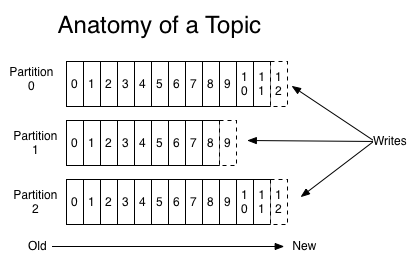
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。
当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可在Partition文件超过1GB时删除旧数据,配置如下所示:
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according to the retention policies
log.retention.check.interval.ms=300000
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高Kafka性能无关。选择怎样的删除策略只与磁盘以及具体的需求有关。
2.3 Producer消息路由
Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。
有了Partition后,不同的消息可以并行写入不同broker的不同Partition里,极大的提高了吞吐率。
可以在$KAFKA_HOME/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。
在发送一条消息时,可以指定这条消息的key,Producer根据这个key和Partition机制来判断应该将这条消息发送到哪个Parition。Paritition机制可以通过指定Producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。
2.4 Consumer Group
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。

这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。
Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的Consumer属于不同的Consumer Group即可。
2.5 Push vs Pull
作为一个消息系统,Kafka遵循了传统的方式,选择由Producer向broker push消息并由Consumer从broker pull消息。
2.6 Kafka delivery guarantee
几种可能的delivery guarantee:
At most once 消息可能会丢,但绝不会重复传输 At least one 消息绝不会丢,但可能会重复传输 Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
当Producer向broker发送消息时,一旦这条消息被commit,因为replication的存在,它就不会丢。但是如果Producer发送数据给broker后,遇到网络问题而造成通信中断,那Producer就无法判断该条消息是否已经commit。虽然Kafka无法确定网络故障期间发生了什么,但是Producer可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了Exactly once。
Consumer在从broker读取消息后,可以选择commit,该操作会在Zookeeper中保存该Consumer在该Partition中读取的消息的offset。该Consumer下一次再读该Partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。
当然可以将Consumer设置为autocommit,即Consumer一旦读到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了Exactly once。
但实际使用中应用程序并非在Consumer读取完数据就结束了,而是要进行进一步处理,而数据处理与commit的顺序在很大程度上决定了消息从broker和consumer的delivery guarantee semantic。
Kafka默认保证At least once,并且允许通过设置Producer异步提交来实现At most once。而Exactly once要求与外部存储系统协作,幸运的是Kafka提供的offset可以非常直接非常容易得使用这种方式。
三、高可用
3.1 缘起
在没有Replication的情况下,一旦某机器宕机或者某个Broker停止工作则会造成整个系统的可用性降低。随着集群规模的增加,整个集群中出现该类异常的几率大大增加,因此对于生产系统而言Replication机制的引入非常重要。
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
3.2 高可用设计解析
Kafka分配Replica的算法如下:
1.将所有Broker(假设共n个Broker)和待分配的Partition排序
2.将第i个Partition分配到第(i mod n)个Broker上
3.将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
3.3 Data Replication(副本策略)
3.3.1 消息传递同步策略
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。
Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。
一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。
Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
总结:
高可用机制,就是 replica(复制品) 副本机制。
每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。只能读写 leader。
Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
如果某个 broker 宕机了,没事儿,那个 broker上面的 partition 在其他机器上都有副本的,如果这上面有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
Kafka学习笔记-如何保证高可用的更多相关文章
- redis 学习笔记(4)-HA高可用方案Sentinel配置
上一节中介绍了master-slave模式,在最小配置:master.slave各一个节点的情况下,不管是master还是slave down掉一个,“完整的”读/写功能都将受影响,这在生产环境中显然 ...
- SpringCloud学习笔记(6)——Eureka高可用
参考Spring Cloud官方文档第12章12.3.12.5.12.6小节 12.3 High Availability, Zones and Regions 默认情况下,每一个Eureka服务器同 ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- KafKa——学习笔记
学习时间:2020年02月03日10:03:41 官网地址 http://kafka.apache.org/intro.html kafka:消息队列介绍: 近两年发展速度很快.从1.0.0版本发布就 ...
- Kafka学习笔记(3)----Kafka的数据复制(Replica)与Failover
1. CAP理论 1.1 Cosistency(一致性) 通过某个节点的写操作结果对后面通过其他节点的读操作可见. 如果更新数据后,并发访问的情况下可立即感知该更新,称为强一致性 如果允许之后部分或全 ...
- Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer
Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer: 启动Zookeeper 启动Kafka0.11 创建一个新的Topic: ./kafk ...
- kafka为什么吞吐量高,怎样保证高可用
1:kafka可以通过多个broker形成集群,来存储大量数据:而且便于横向扩展. 2:kafka信息存储核心的broker,通过partition的segment只关心信息的存储,而生产者只负责向l ...
- 【消息队列】kafka是如何保证高可用的
一.kafka一个最基本的架构认识 由多个broker组成,每个broker就是一个节点:创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的br ...
随机推荐
- 【带着canvas去流浪(8)】碰撞
目录 一. canvas的能力 二. 动画框架 三. 在canvas中模拟碰撞 3.1定义小球的属性 3.2 生成新的小球 3.3 帧动画绘制函数step 3.4 定义小球的update方法 3.5 ...
- 【大数据安全】Apache Kylin 安全配置(Kerberos)
1. 概述 本文首先会简单介绍Kylin的安装配置,然后介绍启用Kerberos的CDH集群中如何部署及使用Kylin. Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spa ...
- VsCode+Node的前端环境搭建及其理解并创建一个前端目录
既然选择了远方,便只顾风雨兼程 __ HANS许 系列:零基础搭建前后端分离项目 系列:零基础搭建前后端分离项目 VsCode VsCode的安装 VSCode中文设置 VsCode 扩展 VsCod ...
- H5、C3、ES6的新特性
H5的新特性 1.语义化标签 有利于SEO,有助于爬虫抓取更多的有效信息,爬虫是依赖于标签来确定上下文和各个关键字的权重. 语义化的HTML在没有CSS的情况下也能呈现较好的内容结构与代码结构 方便其 ...
- Hacking HackDay: Albania
概述: Name: HackDay: Albania Date release: 18 Nov 2016 Author: R-73eN Series: HackDay 下载: https://down ...
- 使用VC建立网络连接并访问网络资源
目录 1. 提出问题 2. 解决方案 1. 提出问题 在windows下可以通过系统操作,将局域网的资源映射到本地,从而实现像本地数据一样访问网络资源.实际上这些步骤也可通过代码调用win32函数实现 ...
- Oracle字符到数值转换错误
[错误] [问题分析] line 3: 定义 NUM_VAL varchar2(500); line 9: NUM_VAL := 'NUM'+1; NUM_VAL是一个varchar类型的数据,而在数 ...
- 局域网git服务器搭建(基于win7 + bonobo git server)
公司内网有一台win7系统的服务器. 准备在上面部署git后台, 用于内网项目版本管理. 搜索了相关资料后, 在根据公司环境, 决定采用win7 + bonobo git server + git的方 ...
- [20190423]简单测试latch nowilling等待模式.txt
[20190423]简单测试latch nowilling等待模式.txt --//我对这个问题的理解就是如果参数willing=0,表示无法获取该latch,直接退出,再寻找类似的latch.--/ ...
- NPM -- 初探--01
NPM是随同NodeJS一起安装的包管理工具,能解决NodeJS代码部署上的很多问题,常见的使用场景有以下几种: 允许用户从NPM服务器下载别人编写的第三方包到本地使用. 允许用户从NPM服务器下载并 ...