ALS音乐推荐(上)
本篇文章的开头笔者提出一个疑问,何为数据科学,数据科学是做什么的?大家带着这个疑问去读接下来的这篇音乐推荐的公众号。
从经验上讲,推荐引擎属于大规模机器学习,在日常购物中大家或许深有体会,比如:你在淘宝上浏览了一些商品,或者购买了一些商品,那么淘宝就会根据你的偏好给你推荐一些其他类似的商品。然而,相比较其他机器学习算法,推荐引擎的输出更加的直观,有时候的推荐效果让人吃惊。作为机器学习开篇文章,本篇文章会系统的介绍基于Audioscrobbler数据集的音乐推荐。
数据集介绍
Audioscrobbler数据集是一个公开发布的数据集,读者可以在(http://www-etud.iro.umontreal.ca/~bergstj/audioscrobbler_data.html)网站获取。数据集主要有三部分组成,user_artist_data.txt文件是主要的数据集文件记录了约2420条用户id、艺术家id以及用户收听艺术家歌曲的次数数据,包含141000个用户和160万个艺术家;artist_data.txt文件记录了艺术家id和对应的名字;artist_alias.txt记录了艺术家id和对应的别称id。
推荐算法介绍
由于所选取的数据集只记录了用户和歌曲之间的交互情况,除了艺术家名字之外没有其他信息。因此要找的学习算法不需要用户和艺术家的属性信息,这类算法通常被称为协同过滤。如果根据两个用户的年龄相同来判断他们可能具有相似的偏好,这不叫协同过滤。相反,根据两个用户播放过许多相同歌曲来判断他们可能都喜欢某首歌,这是协调过滤。
本篇所用的算法在数学上称为迭代最小二乘,把用户播放数据当成矩阵A,矩阵低i行第j列上的元素的值,代表用户i播放艺术家j的音乐。矩阵A是稀疏的,绝大多数元素是0,算法将A分解成两个小矩阵X和Y,既A=XYT,X代表用户特征矩阵,Y代表特征艺术家矩阵。两个矩阵的乘积当做用户-艺术家关系矩阵的估计。可以通过下边一组图直观的反映:
现在假如有5个听众,音乐有5首,那么A是一个5*5的矩阵,假如评分如下:

图2.1 用户订阅矩阵
假如d是三个属性,那么X的矩阵如下:
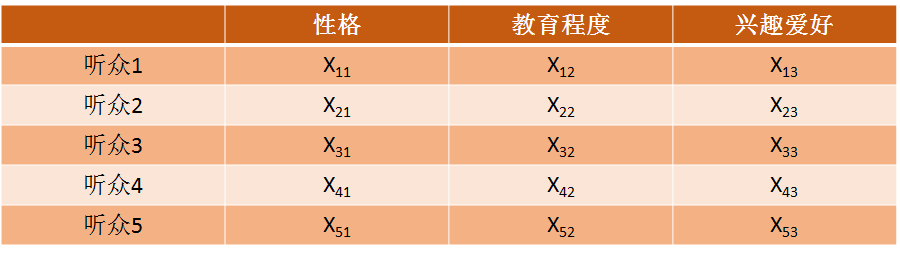
图2.2 用户-特征矩阵
Y的矩阵如下:

图2.3 特征-电影矩阵
实际的求解过程中通常先随机的固定矩阵Y,则,为提高计算效率,通常采用并行计算X的每一行,既
。得到X之后,再反求出Y,不断的交替迭代,最终使得XYT与A的平方误差小于指定阈值,停止迭代,得到最终的X(代表用户特征矩阵)和Y矩阵(代表特征艺术家矩阵)。在根据最终X和Y矩阵结果,向用户进行推荐。
ALS的Spark实现
Spark MLlib的ALS算法实现有点缺陷,要求用户和产品的ID必须是数值型,并且是32位非负整数。在计算之前应该首先检验一下数据量。
1)数据预处理
过滤无效的用户艺术家ID和名字行,将格式不正确的数据行剔除掉。
def buildArtistByID(rawArtistData: Dataset[String]): DataFrame = {
rawArtistData.flatMap { line =>
val (id, name) = line.span(_ != '\t')
if (name.isEmpty) {
None
} else {
try {
Some((id.toInt, name.trim))
} catch {
case _: NumberFormatException => None
}
}
}.toDF("id", "name")
}
过滤艺术家id和对应的别名id,将格式拼写错误的行剔除掉。
def buildArtistAlias(rawArtistAlias: Dataset[String]): Map[Int,Int] = {
rawArtistAlias.flatMap { line =>
val Array(artist, alias) = line.split('\t')
if (artist.isEmpty) {
None
} else {
Some((artist.toInt, alias.toInt))
}
}.collect().toMap
}
将数据转换成Rating对象,Rating对象是ALS算法对“用户-产品-值”的抽象。
def buildCounts(
rawUserArtistData: Dataset[String],
bArtistAlias: Broadcast[Map[Int,Int]]): DataFrame = {
rawUserArtistData.map { line =>
val Array(userID, artistID, count) = line.split(' ').map(_.toInt)
val finalArtistID = bArtistAlias.value.getOrElse(artistID, artistID)
(userID, finalArtistID, count)
}.toDF("user", "artist", "count")
}
2)模型构建
def model(
rawUserArtistData: Dataset[String],
rawArtistData: Dataset[String],
rawArtistAlias: Dataset[String]): Unit = {
val bArtistAlias = spark.sparkContext.broadcast(buildArtistAlias(rawArtistAlias)) //艺术家别名数据
val trainData = buildCounts(rawUserArtistData, bArtistAlias).cache() //将数据转换成需要的格式
val model = new ALS().
setSeed(Random.nextLong()).
setImplicitPrefs(true).
setRank(10).
setRegParam(0.01).
setAlpha(1.0).
setMaxIter(5).
setUserCol("user").
setItemCol("artist").
setRatingCol("count").
setPredictionCol("prediction").
fit(trainData)
trainData.unpersist()
model.userFactors.select("features").show(truncate = false)
val userID = 2093760
val existingArtistIDs = trainData.
filter($"user" === userID).
select("artist").as[Int].collect()
val artistByID = buildArtistByID(rawArtistData)
artistByID.filter($"id" isin (existingArtistIDs:_*)).show()
val topRecommendations = makeRecommendations(model, userID, 5)
topRecommendations.show()
val recommendedArtistIDs = topRecommendations.select("artist").as[Int].collect()
artistByID.filter($"id" isin (recommendedArtistIDs:_*)).show()
model.userFactors.unpersist()
model.itemFactors.unpersist()
}
本篇文章主要对ALS音乐推荐进行简单的介绍,下一篇会对模型的参数,以及模型的推荐效果进行评估,并且会对推荐结果进行优化。
备注:如果文中排版出现错乱,请点击https://mp.weixin.qq.com/s/aqF38rDQdT35YrLAyLm-nA
更多精彩内容,欢迎扫码关注以下微信公众号:大数据技术宅。大数据、AI从关注开始

ALS音乐推荐(上)的更多相关文章
- 3-Spark高级数据分析-第三章 音乐推荐和Audioscrobbler数据集
偏好是无法度量的. 相比其他的机器学习算法,推荐引擎的输出更直观,更容易理解. 接下来三章主要讲述Spark中主要的机器学习算法.其中一章围绕推荐引擎展开,主要介绍音乐推荐.在随后的章节中我们先介绍S ...
- Spark 实践——音乐推荐和 Audioscrobbler 数据集
本文基于<Spark 高级数据分析>第3章 用音乐推荐和Audioscrobbler数据 完整代码见 https://github.com/libaoquan95/aasPractice/ ...
- Recommending music on Spotify with deep learning 采用深度学习算法为Spotify做基于内容的音乐推荐
本文参考http://blog.csdn.net/zdy0_2004/article/details/43896015译文以及原文file:///F:/%E6%9C%BA%E5%99%A8%E5%AD ...
- 音乐推荐与Audioscrobbler数据集
1. Audioscrobbler数据集 数据下载地址: http://www.iro.umontreal.ca/~lisa/datasets/profiledata_06-May-2005.tar. ...
- Android-bindService本地服务-音乐播放-上
播放音乐的行为写在服务里,Activity去调用Service里面到方法,进行音乐播放,当Activity结束后,音乐播放器停止播放 界面: MainActivity: package liudeli ...
- 6、DRN-----深度强化学习在新闻推荐上的应用
1.摘要: 提出了一种新的深度强化学习框架的新闻推荐.由于新闻特征和用户喜好的动态特性,在线个性化新闻推荐是一个极具挑战性的问题. 虽然已经提出了一些在线推荐模型来解决新闻推荐的动态特性,但是这些方法 ...
- 这个菜鸟花几个小时写的 DEMO 被码云推荐上首页 ?
写在最前 没有接触过 AntV 的诸位看客可通过这篇不成文的文章稍作了解.最近 病毒猖獗,遂抽空做了一个相关小 DEMO.数据可视化方面的使用的是 AntV F2,前端框架使用 Vue 快速成 ...
- 用TensorFlow教你手写字识别
博主原文链接:用TensorFlow教你做手写字识别(准确率94.09%) 如需转载,请备注出处及链接,谢谢. 2012 年,Alex Krizhevsky, Geoff Hinton, and Il ...
- 历上最强的音乐播放器(jetA…
原文地址:历上最强的音乐播放器(jetAudio-8.0.5.320-Plus-VX-完全汉化版)下载作者:盖世天星 历上最强的音乐播放器(jetAudio-8.0.5.320-Plus-VX-完全汉 ...
随机推荐
- c# 基于FTP协议的简易软件自动升级程序
最近在重写了一个老的产品条码扫描程序,客户端数越有30个,因为经常有更新,C/S维护非常不方便,所以做一个自动更新程序特别有必要. 在网上随便找了找自动更新的方案,大多使用VS的发布/更新功能,不太喜 ...
- [日常] NOIP 2017滚粗记
突然挑了这么个滑稽的时间补了游记... (成绩日常延时再加上人太菜估计基本上就是颓废记录) 然而文化课太废可能会被强制退役QAQ所以先补了再说吧 day0 一大早被老姚交代了个开十一机房门的任务... ...
- Java虚拟机之GC
⑴背景 Java堆和方法区实现类所需内存是不一样的,每个方法的多分支需要的内存也可能不一样,我们只有在运行期间才能制动创建哪些对象.这部分内存分配与回收都是动态的,而垃圾回收器所关注的就是这些这部分内 ...
- SpringMVC DispatcherServlet 启动和加载过程(源码调试)
在阅读本文前,最好先阅读以下内容(当然,如果对 Servlet 已经有所了解,则可跳过): http://www.cnblogs.com/cyhbyw/p/8682078.html http://ww ...
- ssh框架-Struts2(一)
Struts2 概述 用我们自己的话来说: struts是web层框架, 相当于Servlet 作用: 1. 获得请求参数 2. 调用业务 3. 分发转向 常用的WEB层框架 Struts2入门 1. ...
- Alpha集合
项目名称:城市安全风险管控系统 小组成员: 张梨贤.林静.周静平.黄腾飞 Alpha冲刺随笔 Alpha冲刺Day1 Alpha冲刺Day2 Alpha冲刺Day3 Alpha冲刺Day4 Alpha ...
- Beta冲刺Day1
项目进展 李明皇 今天解决的进度 点击首页list相应条目将信息传到详情页 明天安排 优化信息详情页布局 林翔 今天解决的进度 前后端连接成功 明天安排 开始微信前端+数据库写入 孙敏铭 今天解决的进 ...
- python 操作MongoDB
安装MongoDB 启动数据库:安装完成指定数据库存放路径 mongod.exe --dbpath c:\data\db进入目录后运行mongo.exe 成功 创建数据库 > use mydb ...
- New UWP Community Toolkit - ImageEx
概述 UWP Community Toolkit 中有一个图片的扩展控件 - ImageEx,本篇我们结合代码详细讲解 ImageEx 的实现. ImageEx 是一个图片的扩展控件,包括 Ima ...
- JAVA_SE基础——57.有了包之后类与类之间的访问使用import语句
代码1访问代码2 代码1: class Demo3 { public static void main(String[] args) { Demo4 a = new Demo4(); a.print( ...