Day10 多线程理论 开启线程
多线程:
多线程和多进程的不同是他们占用的资源不一样,
一个进程里边可以包含一个或多个进程,
进程的开销大,线程的开销小。
打个比方来说:创建一个进程,就是创建一个车间。创建一个线程,就是在一个车间创建一个流水线。
怎么去开启一个线程:
方法一(直接用默认的类):
开启线程的方式一:使用替换threading模块提供的Thread
from threading import Thread
from multiprocessing import Process def task():
print('is running') if __name__ == '__main__':
t=Thread(target=task,)
# t=Process(target=task,)
t.start()
print('主')
方法二(自己定义一个类,继承系统的类):
#开启线程的方式二:自定义类,继承Thread
from threading import Thread
from multiprocessing import Process
class MyThread(Thread):
def __init__(self,name):
super().__init__() #不破坏原有的类
self.name=name
def run(self):
print('%s is running' %self.name) if __name__ == '__main__':
t=MyThread('egon')
# t=Process(target=task,)
t.start()
print('主')
在同时开始多个线程和多个进程的时候,多个线程的pid是不一样的,多个线程的pid是一样的。
可以利用这段代码测试下:
from threading import Thread
from multiprocessing import Process
import os def task():
print('%s is running' %os.getpid()) if __name__ == '__main__':
# t1=Thread(target=task,)
# t2=Thread(target=task,)
t1=Process(target=task,)
t2=Process(target=task,)
t1.start()
t2.start()
print('主',os.getpid())
多个线程是共享同一个进程内的资源的。
Thread的其他相关的属性或者方法:
from threading import Thread,activeCount,enumerate,current_thread
import time
def task():
print('%s is running' %current_thread().getName())
time.sleep(2) if __name__ == '__main__':
t=Thread(target=task,)
t.start()
t.join()
print(t.is_alive()) #判断线程是否是活着的
print(t.getName()) #获取到线程名
print(enumerate()) #显示当前活跃的进程对象
print('主')
print(activeCount()) #查看活着的线程数,一般是一个主进程(相当于也是一个线程)和开启的数量
current_thread的用法:
current_thread的用法
from threading import Thread,activeCount,enumerate,current_thread
from multiprocessing import Process
import time def task():
print('%s is running' %current_thread().getName())
time.sleep(2) if __name__ == '__main__':
p=Process(target=task)
p.start()
print(current_thread())
主线程从执行层面上代表了其所在进程的执行过程。
守护线程:
无论是进程还是线程,都是遵循:守护XXX会等待主XXX运行完毕后被销毁。
需要强调的是:运行完毕并非终止运行。
主进程运行完了还需要等待子进程运行。
先看:守护进程 from multiprocessing import Process
import time def task1():
print('123')
time.sleep(1)
print('123done') def task2():
print('456')
time.sleep(10)
print('456done') if __name__ == '__main__':
p1=Process(target=task1)
p2=Process(target=task2)
p1.daemon = True #p1加了守护进程
p1.start()
p2.start()
print('主')
p1加了守护进程后,在主进程运行结束后,p1的进程也死掉。
p2没有加守护进程,在主进程运行结束后,p2会继续运行。
#再看:守护线程 from threading import Thread
import time def task1():
print('123')
time.sleep(10)
print('123done') def task2():
print('456')
time.sleep(1)
print('456done') if __name__ == '__main__':
t1=Thread(target=task1)
t2=Thread(target=task2)
t1.daemon=True
t1.start()
t2.start()
print('主')
主线程会等其他线程(相当于子线程)运行完毕,程序才会结束。
如果(子)线程加上了守护线程,当主线程运行结束后,(子)线程没有运行结束的都会被干掉。
需要特别注意的一点,这里如果还有其他线程没有运行完,主线程是不会结束的。
GIL全局解释器锁:
GIL本质就是一把互斥锁。
这把锁的意义在于在代码执行的时候,防止多段代码抢占资源。
在Cpython解释器中,同一个进程下开启多个多线程,同一时刻只能有一个线程执行,无法利用多核优势。
from threading import Thread
n=100
def task():
print('is running') if __name__ == '__main__':
t1=Thread(target=task,)
t2=Thread(target=task,)
t3=Thread(target=task,)
# t=Process(target=task,)
t1.start()
t2.start()
t3.start()
print('主')
比如说python执行这样一个程序:
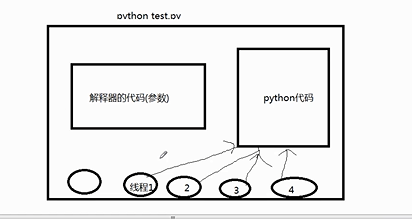
python解释器除了自己开的线程外,还有一些其他的线程,比如说内存回收机制。
线程1,2,3,4都是同一段代码,这三段代码都是要交给python解释器来执行的。
当python代码和内存回收机制同时进行的时候,可能会将数据紊乱。
所以为了防止这种情况:
可以在解释器的代码前后加入这些代码:
GIL.acquire()
解释器的代码()
GIL.release()
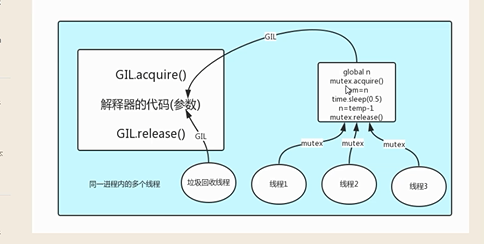
python多线程利用不了多核优势,多进程能够利用多核优势。
#线程的互斥锁
from threading import Thread,Lock
import time
n=100
def work():
global n
mutex.acquire() #加GIL锁
temp=n
time.sleep(0.1)
n=temp-1
mutex.release() #解GIL锁 if __name__ == '__main__':
mutex=Lock() #造出这把所
l=[]
start=time.time()
for i in range(100):
t=Thread(target=work)
l.append(t)
t.start() for t in l:
t.join()
print('run time:%s value:%s' %(time.time()-start,n))
互斥锁和join的区别:
上面的互斥锁的代码,下面是join的代码:
from threading import Thread,Lock
import time
n=100
def work():
time.sleep(0.05)
global n
temp=n
time.sleep(0.1)
n=temp-1 if __name__ == '__main__':
start=time.time()
for i in range(100):
t=Thread(target=work)
t.start()
t.join() print('run time:%s value:%s' %(time.time()-start,n))
join和互斥锁的代码的区别是:
join是将每一个循环斗都执行了,相当于所有的代码串行了。
而互斥锁是只将加锁的代码串行,其他的代码串行。
总结一个结论:如果碰到的是纯IO的操作,利用不了多核优势,一般利用多线程。
如果碰到的是计算的操作,能够利用多核的优势,一般利用多进程。
#多线程
优点:开销小
缺点:不能利用多核优势 from threading import Thread
from multiprocessing import Process
import time
#计算密集型
def work():
res=1
for i in range(100000000):
res+=i if __name__ == '__main__':
p_l=[]
start=time.time()
for i in range(4):
# p=Process(target=work) #6.7473859786987305
p=Thread(target=work) #24.466399431228638
p_l.append(p)
p.start()
for p in p_l:
p.join() print(time.time()-start) #从运算结果上得到结果可以看到,在有4核的机器上,纯计算的多线程程序能利用多核优势,多线程无法利用多核优势。
from threading import Thread
from multiprocessing import Process
import time
#IO密集型
def work():
time.sleep(2) if __name__ == '__main__':
p_l=[]
start=time.time()
for i in range(400):
# p=Process(target=work) #12.104692220687866
p=Thread(target=work) #2.038116455078125
p_l.append(p)
p.start()
for p in p_l:
p.join() print(time.time()-start) #IO密集型程序能够利用单核优势,开线程比开进程的优势在于线程的资源比进程的资源小。
死锁与递归锁:
#死锁现象
#一个线程起来以后,运行函数F1内容(去抢A锁,然后去抢B锁,然后释放B锁,释放A锁),然后运行F2的程序(先抢B锁,然会抢A锁,等待一小下,然后释放A锁,释放B锁)
#同时起了20个线程,当一个线程起来后,运行了A过程,其他线程抢不到A锁,当释放了A锁后,运行B过程,这时候抢到了B锁。其他线程抢到了A锁,第一个线程需要A锁,其他进程需要B锁,就会造成死锁现象。
from threading import Thread,Lock,RLock
import time
mutexA=Lock()
mutexB=Lock()
class Mythread(Thread):
def run(self):
self.f1()
self.f2() def f1(self):
mutexA.acquire()
print('\033[45m%s 抢到A锁\033[0m' %self.name)
mutexB.acquire()
print('\033[44m%s 抢到B锁\033[0m' %self.name)
mutexB.release()
mutexA.release() def f2(self):
mutexB.acquire()
print('\033[44m%s 抢到B锁\033[0m' %self.name)
time.sleep(1)
mutexA.acquire()
print('\033[45m%s 抢到A锁\033[0m' %self.name)
mutexA.release()
mutexB.release() if __name__ == '__main__':
for i in range(20):
t=Mythread()
t.start()
解决死锁的问题可以利用递归锁:
#递归锁 RLock
#RLock的运行原理:当锁一旦acquire的话,计数器+1,当锁release的话,计数器就减一。
#其他锁想抢占锁的时候,就必须得等到锁的计数器减到0才能抢占,这样就避免了死锁现象的发生。2017-09-06
from threading import Thread,Lock,RLock
import time
mutex=RLock()
class Mythread(Thread):
def run(self):
self.f1()
self.f2() def f1(self):
mutex.acquire()
print('\033[45m%s 抢到A锁\033[0m' %self.name)
mutex.acquire()
print('\033[44m%s 抢到B锁\033[0m' %self.name)
mutex.release()
mutex.release() def f2(self):
mutex.acquire()
print('\033[44m%s 抢到B锁\033[0m' %self.name)
time.sleep(1)
mutex.acquire()
print('\033[45m%s 抢到A锁\033[0m' %self.name)
mutex.release()
mutex.release() if __name__ == '__main__':
for i in range(20):
t=Mythread()
t.start()
信号量:
(本质也是一把锁,就好像是一个公共厕所,可以进多个人)
可以让有数量的进程一起运行。
from threading import Thread,current_thread,Semaphore
import time,random
#current_thread 得到线程的名称
#Semaphore 指定线程的最大运行数量函数 #定义最多允许5个进程同时运行
sm=Semaphore(5)
def work():
sm.acquire()
print('%s 上厕所' %current_thread().getName())
time.sleep(random.randint(1,3))
sm.release() if __name__ == '__main__':
for i in range(20):
t=Thread(target=work)
t.start()
信号量的执行是你先创造几把锁,这样就定义了同时能够运行的最大数量。
当有一个线程(或进程)运行了以后,拿走一个锁,count+1.当线程(或线程)运行完毕以后,count-1.
这时候其他的进程或者线程才能够再去抢这把锁。
事件Event:
一共两个进程(或者进程),第二个进程的执行需要得到第一个的执行结果才能执行。
例如说连接数据库需要两个进程,一个检测数据库是否可以连接,一个连接。from threading import Thread,current_thread,Evenimport timeevent=Event()
def conn_mysql():
count=1
while not event.is_set():
if count > 3:
raise ConnectionError('链接失败')
print('%s 等待第%s次链接mysql' %(current_thread().getName(),count))
event.wait(0.5)
#这里设置的wait是等下面check_mysql的event设置为True
count+=1 print('%s 链接ok' % current_thread().getName()) def check_mysql():
print('%s 正在检查mysql状态' %current_thread().getName())
time.sleep(1)
#这里是将event设置为True event.set() if __name__ == '__main__':
t1=Thread(target=conn_mysql)
t2=Thread(target=conn_mysql)
check=Thread(target=check_mysql) t1.start()
t2.start()
check.start()
定时器:
from threading import Timer def hello(n):
print("hello, world",n) t = Timer(3, hello,args=(11,))
t.start() # after 1 seconds, "hello, world" will be printed
#定义了以后在几秒以后执行
线程queue:
针对于线程,不针对于进程
import queue
#这个是针对于线程的 # q=queue.Queue(3) #队列:先进先出
# q.put(1)
# q.put(2)
# q.put(3)
#
# print(q.get())
# print(q.get())
# print(q.get()) # q=queue.LifoQueue(3) #堆栈:后进先出
# q.put(1)
# q.put(2)
# q.put(3)
#
# print(q.get())
# print(q.get())
# print(q.get()) q=queue.PriorityQueue(3) #数字越小优先级越高
#前面放的是优先级,数字越小优先级越高
q.put((10,'data1'))
q.put((11,'data2'))
q.put((9,'data3')) print(q.get())
print(q.get())
print(q.get())
进程池与线程池:
这个模块提高了一个更高级的接口来异步调用。
异步调用就是将一堆任务直接丢到进程池或者线程池,不用等待执行完成。
同步调用是将任务丢到进程池或者线程池,还要等待他的执行结果。
线程池:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
#引用线程池和进程池函数
from threading import current_thread
import os,time,random
def work(n):
print('%s is running' %current_thread().getName())
time.sleep(random.randint(1,3))
return n**2 if __name__ == '__main__':
p=ThreadPoolExecutor()
#生成一个线程池
objs=[]
for i in range(21):
obj=p.submit(work,i)
#将所有线程提交到线程池
objs.append(obj)
p.shutdown()
#等待所有线程结束 #打印线程池内的线程
for obj in objs:
print(obj.result())
进程池:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import current_thread
import os,time,random
def work(n):
print('%s is running' %current_thread().getName())
time.sleep(random.randint(1,3))
return n**2 if __name__ == '__main__':
p=ThreadPoolExecutor()
objs=[]
for i in range(21):
obj=p.submit(work,i)
objs.append(obj)
p.shutdown()
for obj in objs:
print(obj.result())
模拟IO密集型操作,看看是进程池的程序好还是线程池的程序好:
模拟下载网页的过程:(IO需要等待下载)
进程池:
进程池
import requests #pip3 install requests
import os,time
from multiprocessing import Pool
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
def get_page(url):
print('<%s> get :%s' %(os.getpid(),url))
respone = requests.get(url)
if respone.status_code == 200:
return {'url':url,'text':respone.text} def parse_page(obj):
dic=obj.result()
print('<%s> parse :%s' %(os.getpid(),dic['url']))
time.sleep(0.5)
res='url:%s size:%s\n' %(dic['url'],len(dic['text'])) #模拟解析网页内容
with open('db.txt','a') as f:
f.write(res) if __name__ == '__main__': # p=Pool(4)
p=ProcessPoolExecutor()
urls = [
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
] for url in urls:
# p.apply_async(get_page,args=(url,),callback=parse_page)
p.submit(get_page,url).add_done_callback(parse_page) p.shutdown()
print('主进程pid:',os.getpid())
线程池:
线程池
import requests #pip3 install requests
import os,time,threading
from multiprocessing import Pool
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
def get_page(url):
print('<%s> get :%s' %(threading.current_thread().getName(),url))
respone = requests.get(url)
if respone.status_code == 200:
return {'url':url,'text':respone.text} def parse_page(obj):
dic=obj.result()
print('<%s> parse :%s' %(threading.current_thread().getName(),dic['url']))
time.sleep(0.5)
res='url:%s size:%s\n' %(dic['url'],len(dic['text'])) #模拟解析网页内容
with open('db.txt','a') as f:
f.write(res) if __name__ == '__main__': # p=Pool(4)
p=ThreadPoolExecutor(3)
urls = [
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
] for url in urls:
# p.apply_async(get_page,args=(url,),callback=parse_page)
p.submit(get_page,url).add_done_callback(parse_page) p.shutdown()
print('主进程pid:',os.getpid())
Day10 多线程理论 开启线程的更多相关文章
- 20190102(多线程,守护线程,线程互斥锁,信号量,JoinableQueue)
多线程 多进程: 核心是多道技术,本质上就是切换加保存技术. 当进程IO操作较多,可以提高程序效率. 每个进程都默认有一条主线程. 多线程: 程序的执行线路,相当于一条流水线,其包含了程序的具体执行步 ...
- day36 joinablequeue、多线程理论、多线程的两种使用方式、守护线程、互斥锁、死锁、递归锁、信号量
1.joinablequeue队列 joinablequeue与queue一样,也是一种队列,其继承自queue,也有queue中的put 与get 方法,但是在joinablequeue中有自己的 ...
- Python 35 线程(1)线程理论、开启线程的两种方式
一:线程理论 1 什么是线程 进程其实一个资源单位,而进程内的线程才是cpu上的执行单位 线程其实指的就是代码的执行过程2 为何要用线程 线程vs进程 1. 同一进程下的多个线程共享该进程 ...
- python 之 并发编程(线程理论,开启线程的两种方式,进程与线程的区别,线程对象的其他方法)
9.9 线程理论 1.什么是线程 线程指的是一条流水线的工作过程 进程根本就不是一个执行单位,进程其实是一个资源单位,一个进程内自带一个线程,线程才是执行单位 2.进程VS线程 同一进程内的线程们共享 ...
- python 并发编程 多线程 开启线程的两种方式
一 threading模块介绍 multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性 二 开启线程的两种方式 第一种 每造一个进程,默认有一个线程,就是 ...
- 线程概念( 线程的特点,进程与线程的关系, 线程和python理论知识,线程的创建)
参考博客: https://www.cnblogs.com/xiao987334176/p/9041318.html 线程概念的引入背景 进程 之前我们已经了解了操作系统中进程的概念,程序并不能单独运 ...
- python 全栈开发,Day41(线程概念,线程的特点,进程和线程的关系,线程和python 理论知识,线程的创建)
昨日内容回顾 队列 队列 : 先进先出.数据进程安全 队列实现方式: 管道 + 锁 生产者消费者模型 : 解决数据供需不平衡 管道 双向通信 数据进程不安全 EOFError: 管道是由操作系统进行引 ...
- Python进阶----线程基础,开启线程的方式(类和函数),线程VS进程,线程的方法,守护线程,详解互斥锁,递归锁,信号量
Python进阶----线程基础,开启线程的方式(类和函数),线程VS进程,线程的方法,守护线程,详解互斥锁,递归锁,信号量 一丶线程的理论知识 什么是线程: 1.线程是一堆指令,是操作系统调度 ...
- iOS开发多线程篇—创建线程
iOS开发多线程篇—创建线程 一.创建和启动线程简单说明 一个NSThread对象就代表一条线程 创建.启动线程 (1) NSThread *thread = [[NSThread alloc] in ...
随机推荐
- 【一天一道LeetCode】#345. Reverse Vowels of a String
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Write a ...
- 03-Git常用命令演示、冲突演示
Git常用命令演示 Git的的思想其实和SVN还是蛮像的,可以参考之前svn文章一起加深了解. 新建一个user2目录,clone下代码. 修改readme.txt git status 可以看到re ...
- 04_Weblogic之受管服务器:配置受管服务器,启动受管服务器,解决因为强制关闭Weblogic之后导致启动有问题的问题,配置boot.properties
配置受管服务器, 先启动WebLogic服务器,启动方式如下: 在WebLogic控制台中的"开发模式"---"锁定并编辑"模式下,点击"Ser ...
- (三十三)UIApplicationDelegate和程序的启动过程
移动操作系统有个致命弱点,是app容易受到干扰(来电或者锁屏). 当app受到干扰时,会产生一系列的系统事件,这时UIApplication会通知其delegate对象,让delegate处理系统事件 ...
- 开源图像检索工具:Caliph&Emir使用方法
Caliph&Emir是基于MPEG7的软件.它是用Java编写的开源软件.采用了lucene完成索引和检索功能.是研究MPEG7标准,图像检索等等方面不可多得的好工具. 在此介绍一下它们的基 ...
- C++格式化输出,C++输出格式控制
在输出数据时,为简便起见,往往不指定输出的格式,由系统根据数据的类型采取默认的格式,但有时希望数据按指定的格式输出,如要求以十六进制或八进制形式 输出一个 整数,对输出的小数只保留两位小数等.有两种方 ...
- android 开源图表库MPChart最简单使用方法示例教程Demo--折线图 柱状图
转载请注明本文出处:http://blog.csdn.net/wingichoy/article/details/50428246 MPChart是android上一款强大的图表开源库,他可以轻松的绘 ...
- crontab 任务程序执行乱码的问题
今天碰到一个坑爹的问题,定时用php程序从远程的mssql读取数据,并写入到mysql中,手动用php执行程序的时候,程序运行没有问题,但当用crontab任务定时执行php程序的时候就出问题了,插入 ...
- Android学习之旅-android系统服务的启动过程以及分类(90)
读了android开发精要这本书,所以我把书中的比较精彩的地方截图了,一块分享一下
- 《java入门第一季》之面向对象(构造方法)
/* 构造方法: 给对象的数据进行初始化 格式: A:方法名与类名相同 B:没有返回值类型,连void都没有 C:没有具体的返回值 */ class Student { private String ...