文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言:
经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的。于是开始逐一的去了解SVM的原理。
SVM 是在建立在结构风险最小化和VC维理论的基础上。所以这篇只介绍关于SVM的理论基础。参考this paper:
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/svmtutorial.pdf
目录:
- 文本分类学习(一)开篇
- 文本分类学习(二)文本表示
- 文本分类学习(三)特征权重(TF/IDF)和特征提取
- 文本分类学习(四)特征选择之卡方检验
- 文本分类学习(五)机器学习SVM的前奏-特征提取(卡方检验续集)
- 文本分类学习(六)AdaBoost和SVM(残)
1.泛化误差界
机器学习的能力和它的表现,有一个衡量的标准那就是泛化误差界。所谓泛化误差,就是指机器学习在除训练集之外的测试集上的预测误差。传统的机器学习追求在训练集上的预测误差最小化(经验风险,下面会具体说到),然后放到实际中去预测测试集的文本,却一败涂地。这就是泛化性能太差,而泛化误差界是指一个界限值,后面也会解释到。
机器学习实际是在预测一个模型以逼近真实的模型。这其中就必然存在与真实模型之间的误差(风险),这个风险当然是可以计算的。
假设我们有l个观察值,每个观察值由两个元素组成 一个属于Rn(n维空间)的向量:Xi ∈ Rn (i = 1 , 2 , 3 , 4...l) 已经和这个向量相对应的映射值 Yi 在二分类文本中 Xi就表示第i个文本的特征向量,前面介绍过,那么Yi = {+1,-1} 由两个类别组成。
接着我们假设有一个未知的分布 P(X,Y) 是X 到 Y 的映射,给定Xi 都有一个固定的Yi 与之对应,与此同时我们使用机器学习得到了一个函数 f (x, α) 表示输入 x 会得出x的映射 y,这里的 α 是机器学习的某一个参数,比如具有固定的结果的神经网络,具有表示重量和偏见的 α 。 那么该机器学习算法的风险(误差)公式 :
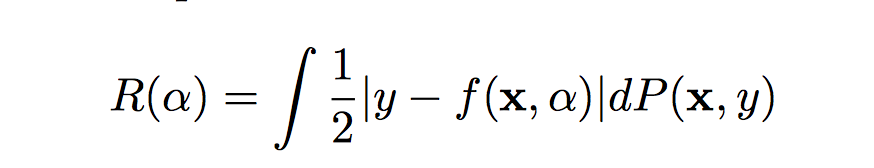
R (α) 术语叫做期望风险(expected risk),我们也可以称作为真实风险,因为它是衡量机器学习和实际测试数据集之间的误差。
而机器学习和训练数据集之间的误差也有个名字叫做经验风险 (empirical risk)用 Remp(α) 表示:
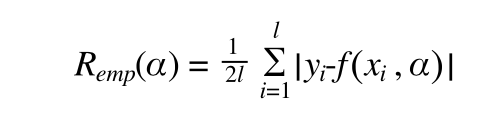
这里给定参数 α 和训练集 {xi,yi} 得到的 Remp(α) 是一个确定的数字,取一个 η ( 0<= η<=1)用 1- η 机器学习出现误差的概率,R (α) 有一个上界可以表示为(Vapnik, 1995 ):

Φ(h/l) 叫做置信风险 (VC confidence), h 叫做VC维度 (Vapnik Chervonenkis (VC) dimension) l 就是样本数目 Φ(h/l) 的公式如下:
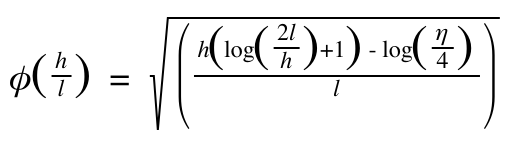
以上公式可以看到,要使真实风险最小,统计学习就要使得R (α) 的上界最小,也就是让 Φ(h/l) + Remp(α) 变的最小,也就是结构风险最小,。可以说 Φ(h/l) + Remp(α) 叫做结构风险,它是一个实际的边界值,是R (α) 的上限,就是统计学中的泛化误差界限。那么怎么使得结构风险最小化呢?下面就要提到VC维度理论。(注:上面的公式就不用去思考原理了,都是paper里面的公式)
2.VC维度
上面说到置信风险Φ(h/l) 中的h叫做VC 维度,那么VC维度是什么呢?举个例子:
假设我们有 l 个点,每个点我们都有个标记 Yi = {+1,-1},把这 l 个点 分别进行标记+1或者-1 ,那么有2l 种方法。对于函数集 { f(x,α) } (f(x,α) 就是前面提到的机器学习得到的分类函数) 中的函数,2l中的每个方法都能从函数集中找到一个函数去成功的标记,那么就说这个函数集 { f(x,α) } 的VC维度为 l 。也就是函数集能够进行标记的数据点的最大个数(用行话叫做分散)。再实际一点:
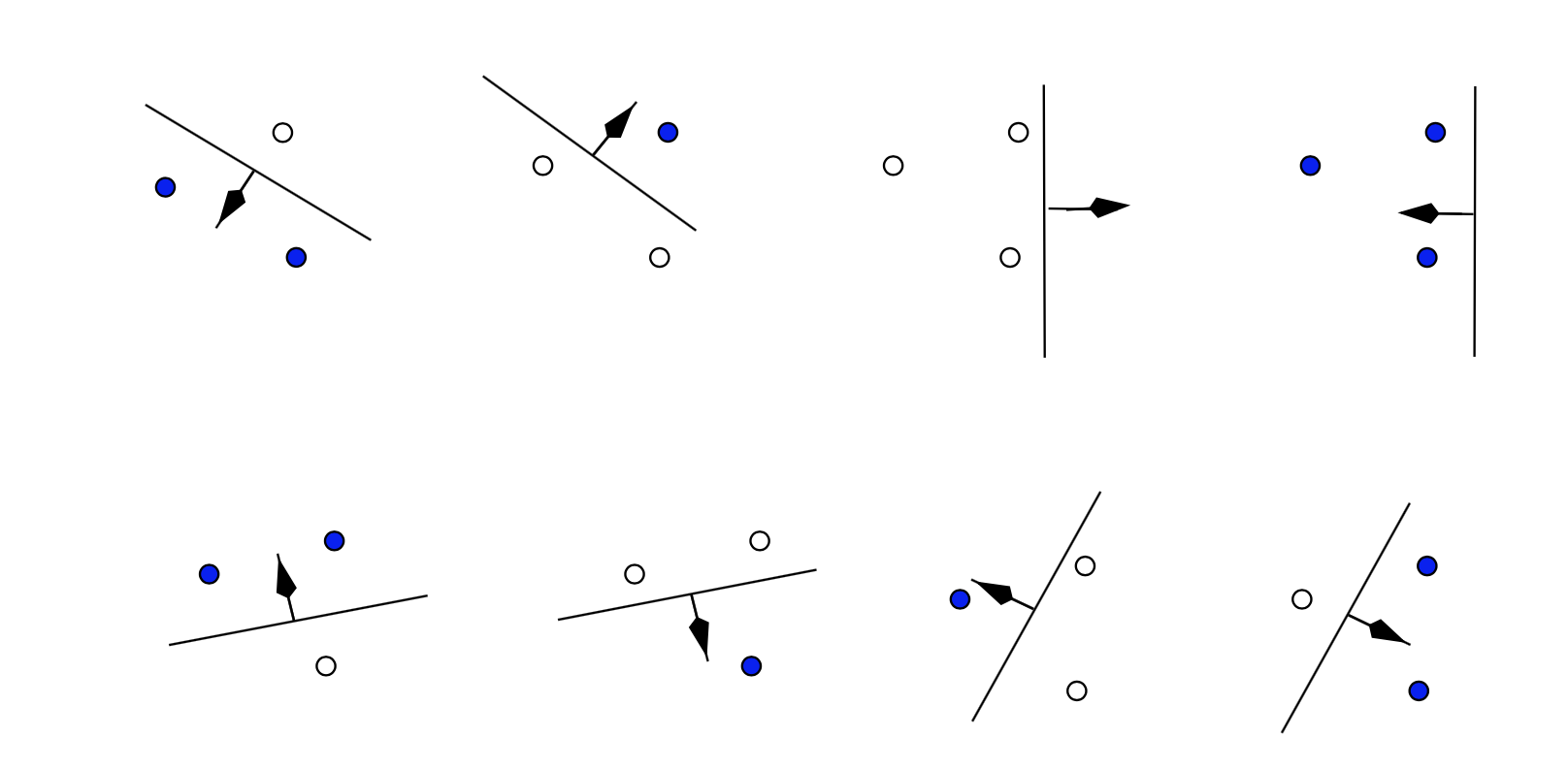
这是在二维坐标平面上,3个点,将他们进行比较为2个类别,会有2的3次方,也就是8种方法,可以看到每种标记方法我们都可以找到一条直线把这3个点分散(就是根据类别分开)。但是4个点的时候,你却发现有几种情况你无法找到一条直线将他们按照类别分开在直线的两侧。这也就说明了在二维空间里,一个直线的集合的VC维度是3。
推广到n维空间Rn 中 超平面(Oriented Hyperplanes)的VC维度是n+1。证明的方法是根据一个定理:
在n维空间 Rn 中有一个m个点的集合,选择任意一个点作为原点,如果剩下的m-1个点是线性可分的,那么这m个点就可以被一个超平面集合分散
推广一下,在n维空间 Rn 中我们总是可以选取n+1个点,选取其中一个点作为原点,剩下的n个点在n维空间是一定线性可分的,因此n+1个点在n维空间中是可以被超平面集合分散的。
VC维度越高,表示函数集的复杂程度越高。一般的函数集的越复杂,VC维度越高,能够对训练集的每一个文本都可以精确分类,也就是把经验风险降到最低,但是前面说过,面对训练集之外的样本却一塌糊涂。就是因为VC维度太高了,为什么呢?因为忽视了置信风险:

取 η = 0.05) l = 10,000 可以得到
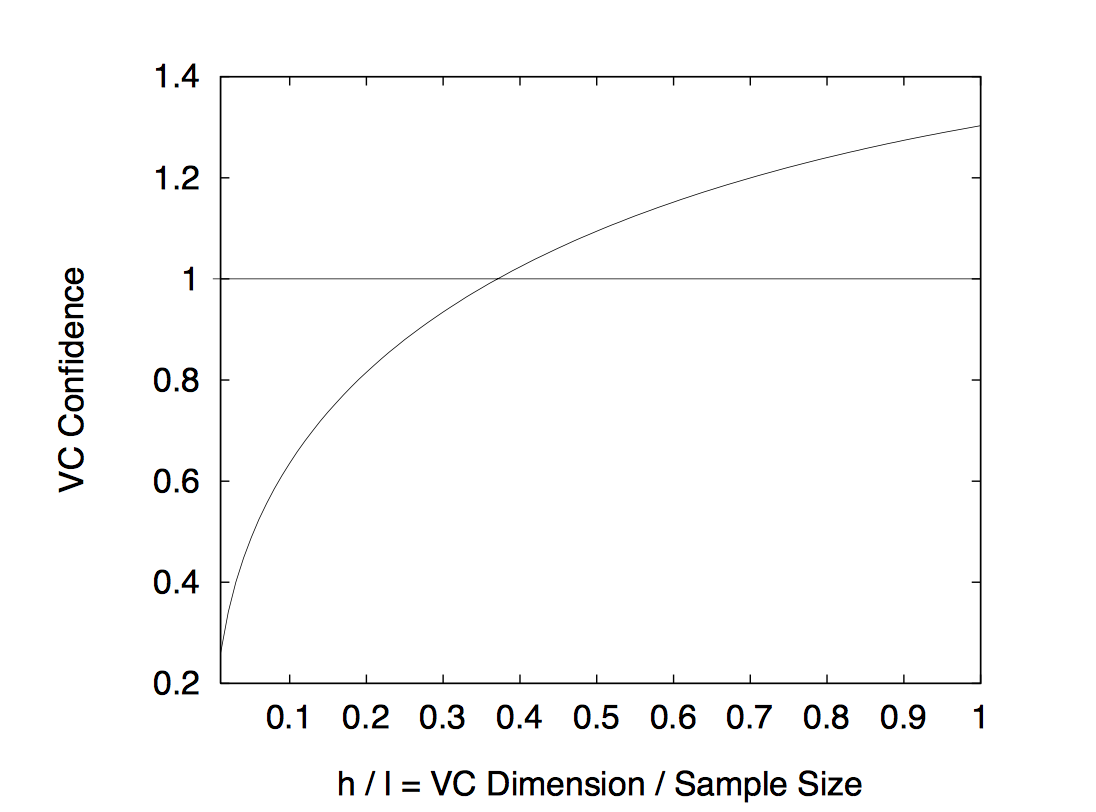
可以看到VC维度 h 越高,置信风险也越高,对于任意的l, 置信风险都是h的递增函数。
对于一般情况VC维度越高,机器学习的置信风险越高,泛化能力就会越差。然而也有相反的情况:
反例:
如果VC维度到达无限,比如K邻近算法,k=1 只有一个类,那么所有的样本都会被正确分类,他的VC维度是无限的,经验风险是0。他的泛化能力反而是无限强的。
如果VC维度到达无限,那么上面的说的泛化误差界限就没有实际的用处了,所以VC维度高到无限对性能的影响也不一定是差的。
3.SRM 结构风险最小化
在第1节中已经提到了让 Φ(h/l) + Remp(α) 最小化 ,就是结构风险最小化,也即SRM( Structural Risk Minimization )
具体的思想是:
通过将函数集划分为多个子集。 对于每个子集按照VC维度排列,在每个子集中寻找最小经验风险,然后在子集之间折衷考虑经验风险和置信风险之和最小,得到的泛化误差界最小。
而SVM 则是将结构风险最小化较好实现的算法。具体在哪里体现了,还是在以后遇到的时候再提吧。
文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论的更多相关文章
- 文本分类学习 (十)构造机器学习Libsvm 的C# wrapper(调用c/c++动态链接库)
前言: 对于SVM的了解,看前辈写的博客加上读论文对于SVM的皮毛知识总算有点了解,比如线性分类器,和求凸二次规划中用到的高等数学知识.然而SVM最核心的地方应该在于核函数和求关于α函数的极值的方法: ...
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- svm、经验风险最小化、vc维
原文:http://blog.csdn.net/keith0812/article/details/8901113 “支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上” 结构化 ...
- 机器学习理论基础学习4--- SVM(基于结构风险最小化)
一.什么是SVM? SVM(Support Vector Machine)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性和非线性两大类. ...
- 文本分类学习(六) AdaBoost和SVM
直接从特征提取,跳到了BoostSVM,是因为自己一直在写程序,分析垃圾文本,和思考文本分类用于识别垃圾文本的短处.自己学习文本分类就是为了识别垃圾文本. 中间的博客待自己研究透彻后再补上吧. 因为获 ...
- 文本分类学习 (八)SVM 入门之线性分类器
SVM 和线性分类器是分不开的.因为SVM的核心:高维空间中,在线性可分(如果线性不可分那么就使用核函数转换为更高维从而变的线性可分)的数据集中寻找一个最优的超平面将数据集分隔开来. 所以要理解SVM ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 文本分类学习 (九)SVM入门之拉格朗日和KKT条件
上一篇说到SVM需要求出一个最小的||w|| 以得到最大的几何间隔. 求一个最小的||w|| 我们通常使用 来代替||w||,我们去求解 ||w||2 的最小值.然后在这里我们还忽略了一个条件,那就是 ...
- 模式识别之svm()---支持向量机svm 简介1995
转自:http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html 作者:Jasper 出自:http://www.blogjav ...
随机推荐
- CUDA学习,第一个kernel函数及代码讲解
前一篇CUDA学习,我们已经完成了编程环境的配置,现在我们继续深入去了解CUDA编程.本博文分为三个部分,第一部分给出一个代码示例,第二部分对代码进行讲解,第三部分根据这个例子介绍如何部署和发起一个k ...
- leetcode 9 Palindrome Number 回文数
Determine whether an integer is a palindrome. Do this without extra space. click to show spoilers. S ...
- 【一天一道LeetCode】#73. Set Matrix Zeroes
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given a ...
- 网站开发进阶(二十八)初探localStorage
初探localStorage 注: localStorage经典项目应用案例 HTML5中提供了localStorage对象可以将数据长期保存在客户端,直到人为清除. localStora ...
- 学习OpenCV,GPU模块
如何使用opencv的gpu库呢?我这两天一直在搞这个事情,环境的配置见上文(转载),这里我先举个简单的例子,实现这样的功能:host读入一幅图像,加载到GPU上,在GPU上复制一份然后下传到host ...
- STL - vector容器
1Vector容器简介 vector是将元素置于一个动态数组中加以管理的容器. vector可以随机存取元素(支持索引值直接存取, 用[]操作符或at()方法,这个等下会详讲). vector尾部添加 ...
- CRM导入组织报实例名称必须与计算机名称相同的问题
今天采用P2V拷贝了一台CRM数据库到虚机上,因为要加域必须得把计算机名改了,然后再重新导入组织的时候报错了:"实例名称必须与计算机名称相同",google了下没有匹配的问题答案, ...
- Vim/Vi实用技巧(第二版)
Vim/Vi实用技巧 1.导入文件 :r [文件名] #导入到当前编辑的文件中 如 :r /etc/inittab 文件上部为/etc/services文件,下部为/etc/inittab文件 2.执 ...
- struts2 easyui实现datagrid的crud
最近两天因为项目需要,接触了easyui,要用它的datagrid实现crud.第一次做,花了一天时间才完成所有功能,昨天做另外一个模块,同样的功能只用了两个小时. 现在把第一次做datagrid时遇 ...
- Java 条形码生成(一维条形码)
utl:http://mianhuaman.iteye.com/blog/1013945 在这里给大家介绍一个java 生成条形码 jbarcode.jar 生成条形码 支持EAN13, EAN8, ...