MySQL 笔记整理(18) --为什么这些SQL语句逻辑相同,性能却差异巨大?
笔记记录自林晓斌(丁奇)老师的《MySQL实战45讲》
(本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除)
18) --为什么这些SQL语句逻辑相同,性能却差异巨大?
本篇我们以三个例子来记录。
案例一:条件字段函数操作
mysql> CREATE TABLE `tradelog` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`operator` int(11) DEFAULT NULL,
`t_modified` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`),
KEY `t_modified` (`t_modified`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
一个交易系统中有这样一个交易记录表,假设现在已经记录了从16年年初到18年年底的全部数据,需要统计发生在所有年份中7月份的交易记录总数,你可能会这么写查询语句:
mysql> select count(*) from tradelog where month(t_modified)=7;
由于查询条件中的t_modified字段上有索引,你就很放心的执行了,但是实际上执行地很慢。如果你接着这个问题查一查会发现,如果对字段做了函数计算,就用不上索引了,这是MySQL的规定。那么,为什么呢?
我们前面介绍过了,MySQL是按照B+树的数据结构来存放索引的,实际上t_modified这个字段的索引示意图如下:
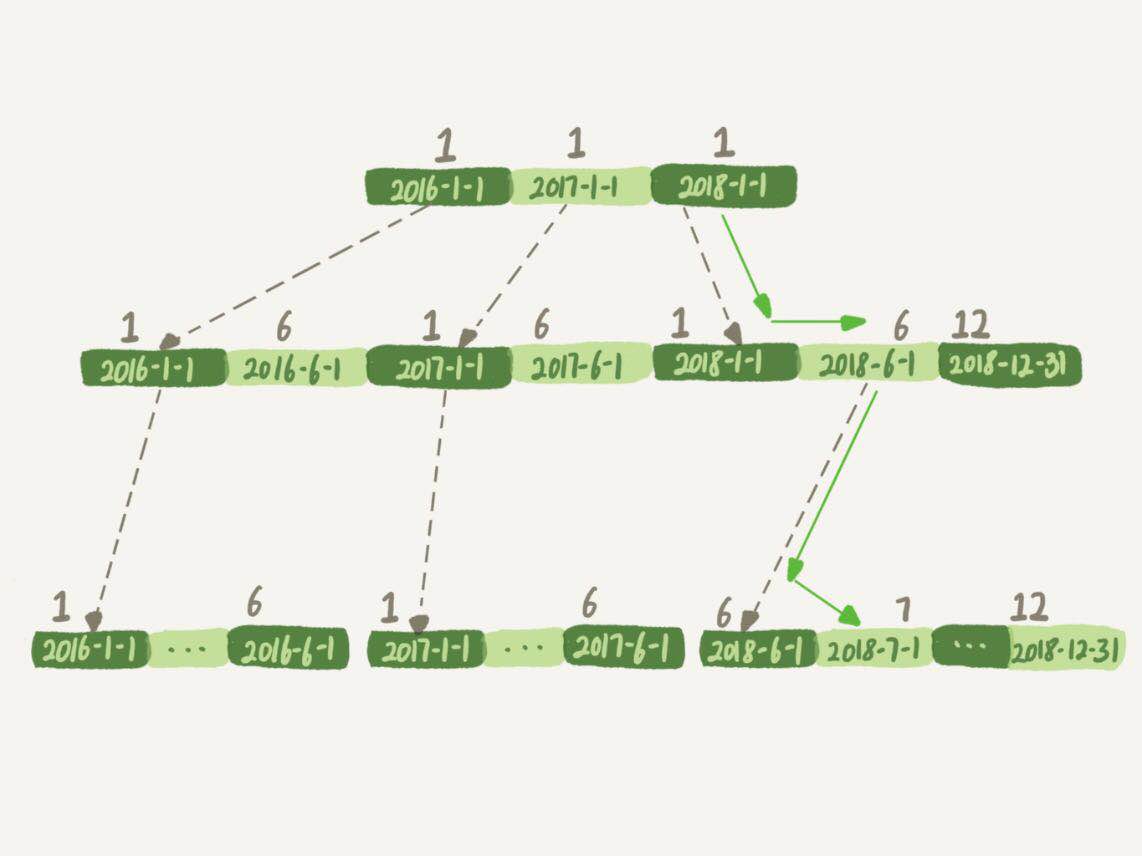
如果你的查询条件是where t_modified = '2018-7-1',那么引擎就会按照上面所示的方式快速定位到这条记录,而如果你使用了month函数来计算的话,在这个索引树的第一层引擎就不知道应该怎么去寻找了。
实际上,B+树提供这个快速定位能力,来源于同一层兄弟节点的有序性。
因此,对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。需要注意的是,优化器并不是要放弃使用这个索引。在这个例子中,放弃了树的搜索功能,优化器可以遍历主键索引,也可以遍历索引t_modified。优化器对比索引大小之后,发现t_modified更小,遍历这个索引更快,因此最终还是会选择索引t_modified。
上面这个例子对索引字段使用了函数操作破坏所引值的有序性,因此查询变慢,那么我们应该怎么优化一下呢?问题的关键是使用上索引,我们可以把语句改成基于字段本身的范围查询,例如:
mysql> select count(*) from tradelog where
-> (t_modified >= '2016-7-1' and t_modified<'2016-8-1') or
-> (t_modified >= '2017-7-1' and t_modified<'2017-8-1') or
-> (t_modified >= '2018-7-1' and t_modified<'2018-8-1');
当然,如果你的系统上线更早,或者后面又插入了之后年份的数据,你就需要把其他年份补齐了。
month()函数破坏了有序性因此导致查询变慢,但实际上,MySQL的优化器确实有“偷懒”行为。例如
select * from tradlog where id+1 = 10000;
虽然没有改变有序性,但是优化器还是不能利用索引快速定位到id=9999这一行。你需要手动改动查询条件为
id = 10000-1才行。
案例二:隐式类型转换
我们还用刚才那个交易记录表举例,来看看这条SQL语句:
mysql> select * from tradelog where tradeid=110717;
交易编号tradeid这个字段本来就有索引,但是explain的结果却显示,这条语句需要走全表扫描。你可能也发现了,tradeid的字段类型是varchar(32),而输入的参数确实整型,索引需要做类型转换。那么现在这里就有两个问题了:
- 数据类型的转换规则是什么?
- 为什么有数据类型转换,就需要走全表索引扫描?
先来看第一个问题,你可能会说,数据库里类型这么多,这种数据类型规则更多,我记不住怎么办呢?有一个简单地方法,看看select "10" > 9的结果:
- 如果规则是“将字符串转成数字”,那么就是数字比较,结果应该是1;
- 如果规则是“将数字转成字符串”,那么久做字符串比较,结果应该是0;
实际上上面这个查询返回的结果是1,即“将字符串转成数字”。这时,我们再来看看案例二刚开始的查询语句
mysql> select * from tradelog where tradeid=110717;
对于优化器来说,这个语句就相当于
mysql> select * from tradelog where CAST(tradeid AS signed int) = 110717;
因此优化器放弃了走树搜索的功能。
案例三: 隐式字符编码转换
假设系统里还有另一个表trade_detail用于记录交易的操作细节。为了方便量化分析和复现,我们准备一些数据,如下:
mysql> CREATE TABLE `trade_detail` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`trade_step` int(11) DEFAULT NULL, /* 操作步骤 */
`step_info` varchar(32) DEFAULT NULL, /* 步骤信息 */
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into tradelog values(1, 'aaaaaaaa', 1000, now());
insert into tradelog values(2, 'aaaaaaab', 1000, now());
insert into tradelog values(3, 'aaaaaaac', 1000, now()); insert into trade_detail values(1, 'aaaaaaaa', 1, 'add');
insert into trade_detail values(2, 'aaaaaaaa', 2, 'update');
insert into trade_detail values(3, 'aaaaaaaa', 3, 'commit');
insert into trade_detail values(4, 'aaaaaaab', 1, 'add');
insert into trade_detail values(5, 'aaaaaaab', 2, 'update');
insert into trade_detail values(6, 'aaaaaaab', 3, 'update again');
insert into trade_detail values(7, 'aaaaaaab', 4, 'commit');
insert into trade_detail values(8, 'aaaaaaac', 1, 'add');
insert into trade_detail values(9, 'aaaaaaac', 2, 'update');
insert into trade_detail values(10, 'aaaaaaac', 3, 'update again');
insert into trade_detail values(11, 'aaaaaaac', 4, 'commit');
此时如果需要查询id=2(tradeid = 'aaaaaaab')的交易的所有操作步骤信息,SQL语句可以这么写:
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;
这条语句的explain执行结果为:

这个结果表明:
- 第一行显示优化器会先在交易记录表tradelog上查到id=2的行,这个步骤用上了主键索引,rows=1表示只扫描了1行。
- 第二行key=NULL,表示没有用上交易详情表trade_detail上的tradeid索引,进行了全表扫描。
这个执行结果里,是从tradelog表中取tradeid字段,再去trade_detail表里查询匹配字段,因此,我们把tradelog称为驱动表,把trade_detail称为被驱动表,把tradeid称为关联字段。接下来我们来看看explain结果表示的执行流程:
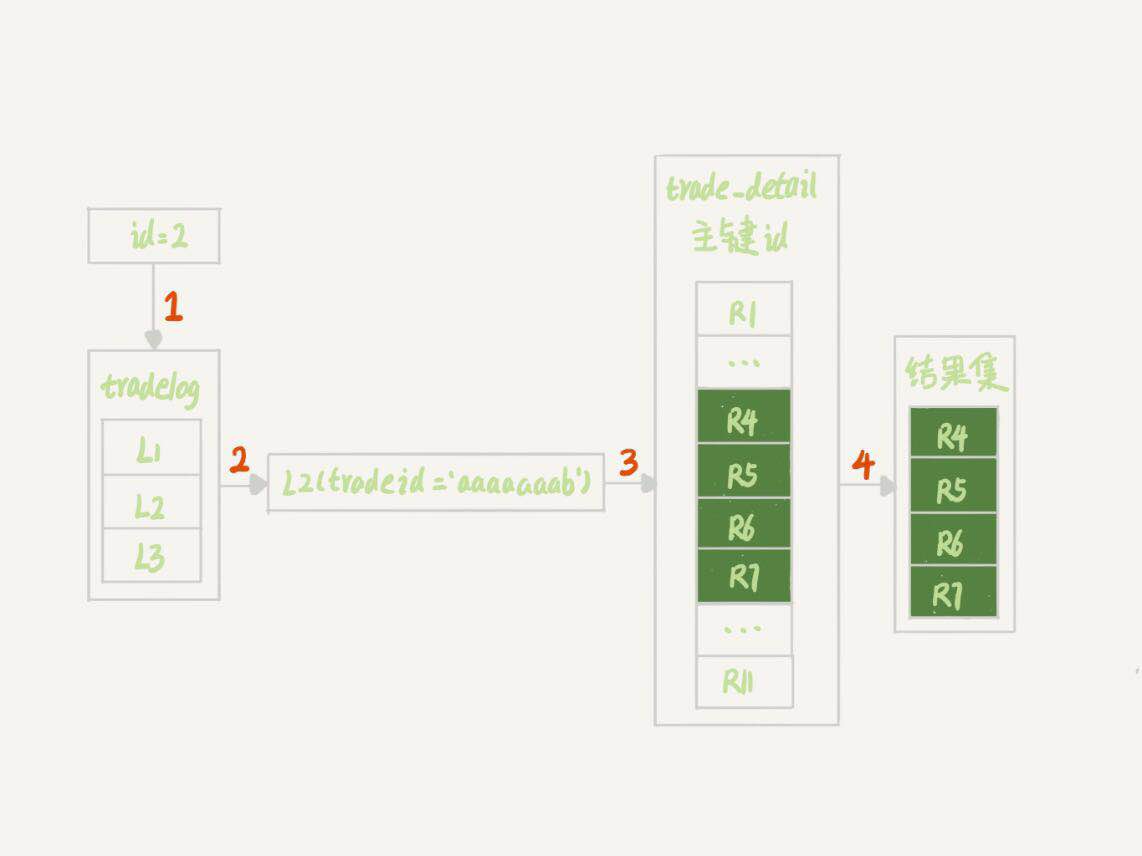
- 根据id在tradelog中找到L2这一行记录。
- 从L2中取出tradeid字段的值。
- 根据tradeid值到trade_detail表中查找条件匹配的行。explain的结果里面第二行的key=NULL表示的就是,这个过程通过遍历主键索引的方式,一个一个地判断tradeid的值是否匹配。
到这里你会发现,第三步中与我们期望的执行结果不符,因为trade_detail字段上是有索引的,我们本来是希望通过使用tradeid索引来快速定位的。这时候如果你去问DBA同学,他可能会告诉你,因为这两个表的字符集不同,一个是utf8,另一个是utf8mb4,所以做表连接查询的时候用不上关联字段的索引。但是如果你再追问一下,为什么字符集不同就用不上索引了呢?
如果说刚才的执行结果问题是出在第三步,那么如果单独把这一步改成SQL语句的话,那就是:
mysql>select * from trade_detail where tradeid = $L2.tradeid.value;
其中,$L2.tradeid.value的字符集是utf8mb4。
参照前面的例子,你肯定想到了,字符集utf8mb4是utf8的超集,所以当这两个类型的字符串是在做比较的时候,MySQL内部的操作是,先把utf8转化成utf8mb4字符集,再做比较。也就是说,实际上这个语句等同于下面这个写法:
select * from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value;
这就触发了我们在案例一中的那种情况:对索引字段做函数操作,优化器会放弃走树搜索功能。
到这里,你应该明白了,字符集不同只是条件之一,连接过程中要求在被驱动表的索引字段上加函数操作,是直接导致对被驱动表做全表扫描的原因。
那么这个语句我们应该怎么去优化呢,一般有两种作法:
- 直接把trade_detail的表的字符集也改成utf8mb4,这样就没有字符集转换的问题了。
- 如果业务上不允许进行DDL的话,那就只能修改SQL语句了,你可以尝试这么写:
mysql> select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2;
这里我们主动改变了l.tradeid的字符集,避免了被驱动表上字符编码的转换。
今天这个三个例子,其实是在说同一件事。即:对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
MySQL 笔记整理(18) --为什么这些SQL语句逻辑相同,性能却差异巨大?的更多相关文章
- 18 | 为什么这些SQL语句逻辑相同,性能却差异巨大?
在MySQL中,有很多看上去逻辑相同,但性能却差异巨大的SQL语句.对这些语句使用不当的话,就会不经意间导致整个数据库的压力变大. 我今天挑选了三个这样的案例和你分享.希望再遇到相似的问题时,你可以做 ...
- 最全mysql笔记整理
mysql笔记整理 作者:python技术人 博客:https://www.cnblogs.com/lpdeboke Windows服务 -- 启动MySQL net start mysql -- 创 ...
- MySQL监控全部执行过的sql语句
MySQL监控全部执行过的sql语句 查看是否开启日志记录show variables like “general_log%” ; +——————+———-+|Variable_name|Value| ...
- 在myeclipse中配置DB Driver(数据库用MySql),并在myeclipse执行sql语句操作
在myeclipse中配置DB Driver(数据库用MySql),并在myeclipse执行sql语句操作 MyEclipse6.5 , mysq驱动jar包为mysql-connector ...
- Mysql中文乱码以及导出为sql语句和Excel问题解决
Mysql中文乱码以及导出为sql语句和Excel问题解决 这几天基于Heritrix写了一个爬虫,用到mysql,在导入导出数据时,遇到一些乱码问题,好不容易解决了,记录一下,以备查看.一.导出数据 ...
- day57-mysql-五种约束和sql语句逻辑执行顺序
二.sql语句逻辑执行顺序 () SELECT () DISTINCT <select_list> 去重复 () FROM <left_table> () <join_t ...
- MySQL 笔记整理(1) --基础架构,一条SQL查询语句如何执行
最近在学习林晓斌(丁奇)老师的<MySQL实战45讲>,受益匪浅,做一些笔记整理一下,帮助学习.如果有小伙伴感兴趣的话推荐原版课程,很不错. 1) --基础架构,一条SQL查询语句如何执行 ...
- MySQL 笔记整理(2) --日志系统,一条SQL查询语句如何执行
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> 2) --日志系统,一条SQL查询语句如何执行 MySQL可以恢复到半个月内任意一秒的状态,它的实现和日志系统有关.上一篇中记录了一 ...
- MySQL 笔记整理(19) --为什么我只查一行的语句,也执行这么慢?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 19) --为什么我只查一行的语句,也执行这么慢? 需要说明一下,如果M ...
随机推荐
- Python GIL(Global Interpreter Lock)
一,介绍 定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native t ...
- 深入理解数据库磁盘存储(Disk Storage)
数据库管理系统将数据存储在磁盘.磁带以及其他的裸设备上,虽然这些设备的访问速度相比内存慢很多,但其非易失性和大容量的特点使他们成为数据存储的不二之选. 本文主要讨论大型数据库产品的磁盘存储内部结构,这 ...
- 10 年三线小城 IT 开发的感悟
一贯都是写技术博客,从来没写过感悟类文章,因为文笔不好.今天看到了大飞的一篇文章,<技术人,请不要封闭自己>,真的感触太深了. 一 先说说我自己,我并非科班出身,大学毕业后一直没找到好的工 ...
- Go:学习笔记兼吐槽(2)
Go:学习笔记兼吐槽(1) Go:学习笔记兼吐槽(2) Go:学习笔记兼吐槽(3) 基本数据类型和string之间的转换 (1) 基本类型转string 使用 fmt.Sprintf(“%参数”, 表 ...
- 在阿里云服务器中用IP连接SQLserver2014提示40,53错误
在有些时候我们需要他人来连接我们的数据库,这个时候我们需要用我们本地的IP地址来连接,在连接的过程中可能会出现找不到网络路径提示40,53的错误 解决方案: 1.打开配置管理器 2.点开网络配置,点击 ...
- docker(1)应用场景以及安装
今年来了新公司,公司没有用什么新技术,架构就简单的前后分离,但是我推一下新的技术,在这基础上我要培训一下同事,让他们能接受,对新技术不感到陌生,并且认可愿意去学习.其实在这个过程中也能让他们认同我这个 ...
- 关于Redis和Memcache的比较
关于Redis和Memcache在应用中,都可以实现缓存的功能,但是,具体使用情况需要根据具体业务场景,尤其是对缓存数据有特性要求时,需要选择对应的缓存机制. 共同点: 都是基于内存的数据库,可用作缓 ...
- windows手动去重 通配符
在下载文件时,如果遇到重复文件,windows的默认做法时 文件名(数字) 这样的方式重命名的. 那么我们在排除重复文件时,可以使用 windows文件浏览器提供的查找功能, 用通配符 ~=& ...
- python3 装饰器初识 NLP第三条
还是先抄一条NLP假设... 三,有效果比有道理更重要 光说做法有道理或者正确而不顾是否有效果,是在自欺欺人. 在三赢(我好,人好,世界好)的原则基础上追求效果,比坚持什么是对的更有意义. 说道理 ...
- Linux 桌面玩家指南:09. X Window 的奥秘
特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用$标记数学公式的开始和结束.如果某条评论中出现了两个$,MathJax 会将两个$之 ...