生成式模型之 GAN
生成对抗网络(Generative Adversarial Networks,GANs),由2014年还在蒙特利尔读博士的Ian Goodfellow引入深度学习领域。2016年,GANs热潮席卷AI领域顶级会议,从ICLR到NIPS,大量高质量论文被发表和探讨。Yann LeCun曾评价GANs是“20年来机器学习领域最酷的想法”。
Generative Adversarial Nets(GAN)
Generative Adversarial Networks论文提出了一种通过对抗过程来评估生成模型。其训练两个模型:仿照原始数据分布生成数据的模型G和评估数据来源(原始数据/生成数据)的模型D。训练G的目标是最大化D犯错的概率,训练D的目标是最大化区分真实训练样本与G生成的样本的能力。
如果能够知道训练样本的分布\(p(x)\),那么就可以在分布中随机采样得到新样本,大部分的生成式模型都采用这种思路,GAN则是在学习从随机变量z到训练样本x的映射关系,其中随机变量可以选择服从正太分布,那么就能得到一个由多层感知机组成的生成网络\(G(z;\theta_g)\),网络的输入是一个一维的随机变量,输出是一张图片。
GAN的优化是一个极小极大博弈问题,公式如下:
\[
\underset{G}{\min} \: \underset{D}{\max}V(D,G) =\mathbb E_{x\sim p_{data}(x)}[logD(x)]+\mathbb E_{z\sim p_{z}(z)}[log(1-D(G(z)))]
\]
优化这个函数,使\(p_z(x)\)接近\(p_{data}\).下面首先去掉期望符号:
\[
\begin{align}
V(G,D)&=\int_x p_{data}(x)\log(D(x))dx+\int_zp_z(z)\log(1-D(g(z)))dz \\
&=\int_x [p_{data}(x)\log(D(x))+p_g(x)\log(1-D(x))]dx
\end{align}
\]
先固定G,求\(\underset{D}{\max}V(D,G)\),令其导数等于0,求得D的最优解
\[
D^*_G(x)={p_{data}(x)\over p_{data}(x)+p_g(x)}
\]
现在固定D,优化G:将\(D^*_G\)带入目标函数。
\[
\begin{align}
\underset{G}\min V(G,D^*_G) &= \int_x [p_{data}(x)\log{p_{data}(x)\over p_{data}(x)+p_g(x)}+p_g(x)\log{p_g(x)\over p_{data}(x)+p_g(x)}]dx \\
&= \mathbb E_{x\sim p_{data}}[\log{p_{data}(x)\over p_{data}(x)+p_g(x)}]+\mathbb E_{x\sim p_g}[\log{p_g(x)\over p_{data}(x)+p_g(x)}] \\
&= -\log 4+KL(p_{data}\|{p_{data}+p_g\over 2})+KL(p_g\|{p_{data}+p_g\over 2}) \\
&= -\log 4+2JS(p_{data}\|p_g)
\end{align}
\]
其中KL散度:\(KL(P\|Q)=\mathbb E_{x\sim P}\log{P\over Q}=\int_xP(x)\log{P(x)\over Q(x)}dx\)
JS散度:\(JS(P\|Q)={1\over 2}KL(P\|{P+Q\over 2})+{1\over 2}KL(Q\|{P+Q\over 2})\)
JS散度具有对称性,而KL没有。
只要P和Q没有一点重叠或者重叠部分可忽略,JS散度就固定是常数,而这对于梯度下降方法意味着——梯度为0!此时对于最优判别器来说,生成器得不到梯度信息;即使对于接近最优的判别器来说,生成器也有很大机会面临梯度消失的问题。
参考 WGAN的介绍。
f-GAN
在GAN中可以使用任意的f-divergency,相关论文f-GAN(Sebastian Nowozin, Botond Cseke, Ryota Tomioka, “f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization”, NIPS, 2016)
f-divergence
P和Q是两个分布,p(x),q(x)是x的分布概率
\[
D_f(P||Q)=\int_x q(x)f({p(x)\over q(x)})dx
\]
其中f是凸函数且f(1)=0,\(D_f(P||Q)\)衡量了P和Q之间的距离.
当\(\forall x,p(x)=q(x)\)时,\(D_f(P||Q)\)具有最小值0.
当\(f(x)=x\log x\)时,\(D_f(P||Q)=\int_xp(x)\log({p(x)\over q(x)})\),即KL divergence.
当\(f(x)=-\log x\)时,\(D_f(P||Q)=\int_xq(x)\log({q(x)\over p(x)})\),即reverse KL divergence.
当\(f(x)=(x-1)^2\)时,\(D_f(P||Q)=\int_x{(p(x)-q(x))^2\over q(x)}dx\)为Chi Square divergence.
Fenchel Conjugate
每个凸函数f都有一个与之相对的conjugate function f*:
\(f^* (t)=\max_{x\in dom(f)}\{xt-f(x)\}\),且(f ) = f.
\(f(x)=\max_{t\in dom(f^*)}\{xt-f^*(t)\}\),带入\(D_f(P||Q)\)得:
\[
\begin{align}
D_f(P||Q) &=\int_x q(x)f({p(x)\over q(x)})dx \\
&=\int_xq(x)(\max_{t\in dom(f^*)}\{{p(x)\over q(x)}t-f^*(t)\})dx \\
&=\max_D\int_x p(x)D(x)dx-\int_x q(x)f^*(D(x))dx \\
&\text{(t=D(x))}
\end{align}
\]
因此GAN中
\[
D_f(P_{data}\|P_G)=\max_D\{E_{x\sim P_{data}}[D(x)]-E_{x\sim P_G}[f^*(D(x))]\}
\]
可以使用任何的f-divergence,如JS,Jeffrey,Pearson.
WGAN
原始版本:weight clipping,改进版本:gradient penalty.
论文:
- Martin Arjovsky, Soumith Chintala, Léon Bottou, Wasserstein GAN, arXiv preprint, 2017
- Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville,“Improved Training of Wasserstein GANs”, arXiv preprint, 2017
主要思想:使用Earth Mover's Distance(Wasserstein Distance)来评估两个分布之间的距离.推土机距离表示将一个分布搬运变为另一个分布的最小搬运的量.
之前GAN所采用的JS divergence的缺点是当两个分布没有交集时,距离是0,梯度为0,网络很难学习.Earth Mover's Distance便可以解决这个问题.此时网络能够持续学习,但为了防止梯度爆炸,需要weight clipping等手段.
对抗样本(adversarial examples)
14年的时候Szegedy在研究神经网络的性质时,发现针对一个已经训练好的分类模型,将训练集中样本做一些细微的改变会导致模型给出一个错误的分类结果,这种虽然发生扰动但是人眼可能识别不出来,并且会导致误分类的样本被称为对抗样本,他们利用这样的样本发明了对抗训练(adversarial training),模型既训练正常的样本也训练这种自己造的对抗样本,从而改进模型的泛化能力[1]。如下图所示,在未加扰动之前,模型认为输入图片有57.7%的概率为熊猫,但是加了之后,人眼看着好像没有发生改变,但是模型却认为有99.3%的可能是长臂猿。
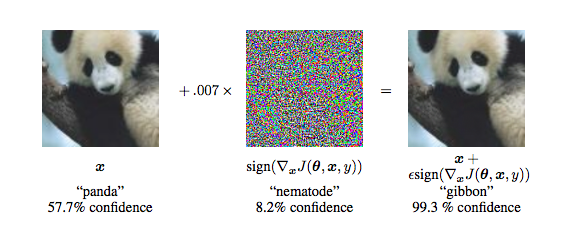
对抗样本跟生成式对抗网络没有直接的关系,对抗网络是想学样本的内在表达从而能够生成新的样本,但是有对抗样本的存在在一定程度上说明了模型并没有学习到数据的一些内部表达或者分布,而可能是学习到一些特定的模式足够完成分类或者回归的目标而已。
GAN生成的图片能否用于CNN训练?
现在来说,应当不可以。由于GAN是从较小的分布中采样生成的,是真实世界的极小的一部分,所以拿来训练没有广泛的适用性。另外,当前的GAN生成较大的图片比较困难(32x32以上)。
参考资料
- GAN作者Ian Goodfellow的教程论文NIPS 2016 Tutorial: Generative Adversarial Networks
- 台大李宏毅 deep learning tutorial
生成式模型之 GAN的更多相关文章
- 生成式对抗网络(GAN)实战——书法字体生成练习赛
https://www.tinymind.cn/competitions/ai 生成式对抗网络(GAN)是近年来大热的深度学习模型. 目前GAN最常使用的场景就是图像生成,作为一种优秀的生成式模型,G ...
- 生成式对抗网络GAN 的研究进展与展望
生成式对抗网络GAN的研究进展与展望.pdf 摘要: 生成式对抗网络GAN (Generative adversarial networks) 目前已经成为人工智能学界一个热门的研究方向. GAN的基 ...
- 预测学习、深度生成式模型、DcGAN、应用案例、相关paper
我对GAN"生成对抗网络"(Generative Adversarial Networks)的看法: 前几天在公开课听了新加坡国立大学[机器学习与视觉实验室]负责人冯佳时博士在[硬 ...
- 【神经网络与深度学习】生成式对抗网络GAN研究进展(五)——Deep Convolutional Generative Adversarial Nerworks,DCGAN
[前言] 本文首先介绍生成式模型,然后着重梳理生成式模型(Generative Models)中生成对抗网络(Generative Adversarial Network)的研究与发展.作者 ...
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- AI 判别式模型和生成式模型
判别式模型(discriminative model) 生成式模型(generative model) 对于输入x,类别标签y:产生式模型估计它们的联合概率分布P(x,y)判别式模型估计条件概率分布P ...
- 生成式模型 VS 判别式模型
1 定义 1.1 生成式模型 生成式模型(Generative Model)会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得 p(yi|x),然后选取使得p(yi|x) 最大的 yi,即 ...
- 判别式模型 vs. 生成式模型
1. 简介 生成式模型(generative model)会对\(x\)和\(y\)的联合分布\(p(x,y)\)进行建模,然后通过贝叶斯公式来求得\(p(y|x)\), 最后选取使得\(p(y|x) ...
- 产生式模型(生成式模型)与判别式模型<转载>
转自http://dongzipnf.blog.sohu.com/189983746.html 产生式模型与判别式模型 产生式模型(Generative Model)与判别式模型(Discrimiti ...
随机推荐
- java.net.UnknownHostException
java.net.UnknownHostException 错误解决方向 查看 测试真机或者模拟机是否连上了网络. 如果不是第一步错误的话,一般就是测试机没有链接上网络,可以打开个网页或者其他 ...
- Hibernate5环境搭建
1.导包 Hibernate开发包 数据库的驱动包 2.核心配置文件 核心配置文件(赋值到src下) 1.核心配置文件 对于hibernate的核心配置文件它有两种方式(选其中一种即可 ...
- webpack打包速度和性能再次优化
一. 改单dll为双dll 因为上图原因,使用CommonsChunkPlugin时,导致其打包出来的vendors.js内的模块ID会因为其他文件引用模块数量的变化而变化. 所以现利用DllPlug ...
- WaitForSingleObject函数
WaitForSingleObject函数 VC声明 DWORD WaitForSingleObject( HANDLE hHandle, DWORD dwMilliseconds ); VB声明 D ...
- R语言︱文本挖掘之中文分词包——Rwordseg包(原理、功能、详解)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:与前面的RsowballC分词不同的 ...
- STM32——GPIO之从库函数到寄存器的前因后果
例子为单片机的"Hello World"级的流水灯实验--虽然只有一个,其中并不是将完整的代码给出,只是给出关键部分来说明"如何调用ST公司的的库来完成对硬件的控制,以及 ...
- Java Web项目(Extjs)报错五
1. Java Web项目(Extjs)报错五 具体报错如下: usage: java org.apache.catalina.startup.Catalina [ -config {pathname ...
- Java中的大小写字母相互转换(不利用Java自带的方法)
Java中的大小写字母相互转换(不利用Java自带的方法) 1.设计源码 /** * * @title:UpperAndLower.java * @Package:com.you.utils * @D ...
- R语言实现二分查找法
二分查找时间复杂度O(h)=O(log2n),具备非常高的效率,用R处理数据时有时候需要用到二分查找法以便快速定位 Rbisect <- function(lst, value){ low=1 ...
- 关于省市联动的bug
一,问题描述 1.1,原来的思路 1.1.1,初始化加载省份 $.ajax({ 'type' : 'POST', 'dataType' : 'json', 'url' : '${rc.contextP ...