Caffe的运行mnist手写数字识别
老规矩,首先附上官方教程:http://caffe.berkeleyvision.org/gathered/examples/mnist.html
注:关于caffe的安装教程请看我的上一篇文章
1、必要软件
因为Caffe中使用的是Linux才能运行的shell脚本,因此首先的安装 wget(将wget放入C:\windows\system32)和 Git 方能运行。
2、而后按照官方教程,首先进入caffe路径的根目录,而后打开cmd输入命令:
./data/mnist/get_mnist.sh
这个命令是通过打开/data/mnist目录下的get_mnist.sh脚本来下载mnist的数据,若cmd出现错误可以直接进入打开get_mnist.sh脚本效果是一样的,运行完成后会出现如下4个数据文件:

而后继续输入以下命令,或者进入路径打开也一样
./examples/mnist/create_mnist.sh
若不存在该文件可以自己创建一个create_mnist.sh,具体的代码如下(注:第九行BUILD可能老版本的路径会不一样,根据自己路径来修改):
#!/usr/bin/env sh # This script converts the mnist data into lmdb/leveldb format,
# depending on the value assigned to $BACKEND.
set -e EXAMPLE=.
DATA=../../data/mnist
BUILD=../../scripts/build/examples/mnist/Release BACKEND="lmdb" echo "Creating ${BACKEND}..." rm -rf $EXAMPLE/mnist_train_${BACKEND}
rm -rf $EXAMPLE/mnist_test_${BACKEND} $BUILD/convert_mnist_data.exe $DATA/train-images-idx3-ubyte \
$DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
$BUILD/convert_mnist_data.exe $DATA/t10k-images-idx3-ubyte \
$DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND} echo "Done." read -p "回车继续..."
运行完成后会出现mnist_test_lmdb和mnist_train_lmdb两个文件夹:

cmd显示:

3、打开路径/scripts/build/examples/mnist/Release下的lenet_solver.prototxt(不同版本的caffe的路径不一样,有些老版本的caffe的路径为:/Build/x64/Release),根据自己的情况修改参数:
第二行:若lenet_train_test.prototxt和lenet_solver.prototxt不在同一路径下,则需要在其之前写上lenet_train_test.prototxt所在的路径
第23行:snapshot_prefix:生成的model为产生的训练模型,可根据自己来修改路径
最后一行为选择安装的caffe是CPU还是GPU,我这里安装的是GPU版本
注意:不要直接将文件路径复制过去,因为在这里面路径分隔符是/ ,而不是\,如果使用\后面运行时会出现以下错误(下面几步同样如此,如果不确定就照着我的写):
修改参数后的结果:
# The train/test net protocol buffer definition
net: "lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "E:/CaffeSource/caffe/data/mnist/model"
# solver mode: CPU or GPU
solver_mode: GPU
4、打开lenet_train_test.prototxt(上面第二行那个文件)
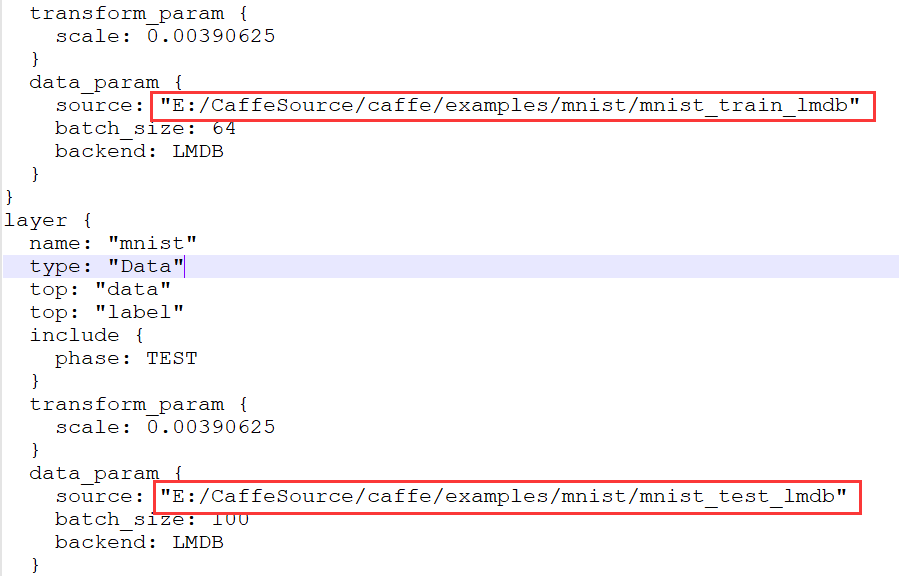
而后更改上图路径,这两个文件是执行./data/mnist/get_mnist.sh命令时下载的文件,将其路径添加进去
5、在目录\examples\mnist下新建一个train_lenet.txt文档,添加下面一段,然后改后缀名为.bat
..\..\Build\x64\Release\caffe.exe train --solver="lenet_solver.prototxt" --gpu 0
pause
或者在该目录下修改train_lenet.sh文件:
#!/usr/bin/env sh
set -e
BUILD=../../Build/x64/Release/
echo "Training lenet_solver.prototxt..." $BUILD/caffe.exe train --solver=lenet_solver.prototxt $@
echo "Done." read -p "回车继续..."
6、运行该文件,大概运行几分钟后结果如下:
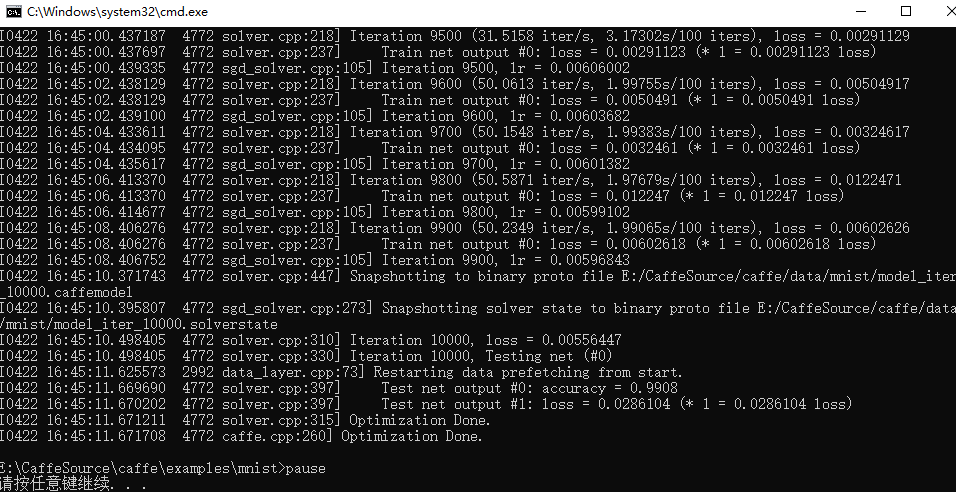
若没有报错,则测试就算大功告成啦!
可以看出准确度为99%,训练好的模型保存在 lenet_iter_10000.caffemodel, 训练状态保存在lenet_iter_10000.solverstate里,结果如下:

Caffe的运行mnist手写数字识别的更多相关文章
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
- 基于TensorFlow的MNIST手写数字识别-初级
一:MNIST数据集 下载地址 MNIST是一个包含很多手写数字图片的数据集,一共4个二进制压缩文件 分别是test set images,test set labels,training se ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
- 深度学习之 mnist 手写数字识别
深度学习之 mnist 手写数字识别 开始学习深度学习,先来一个手写数字的程序 import numpy as np import os import codecs import torch from ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 第三节,CNN案例-mnist手写数字识别
卷积:神经网络不再是对每个像素做处理,而是对一小块区域的处理,这种做法加强了图像信息的连续性,使得神经网络看到的是一个图像,而非一个点,同时也加深了神经网络对图像的理解,卷积神经网络有一个批量过滤器, ...
- mnist 手写数字识别
mnist 手写数字识别三大步骤 1.定义分类模型2.训练模型3.评价模型 import tensorflow as tfimport input_datamnist = input_data.rea ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- Tensorflow之MNIST手写数字识别:分类问题(1)
一.MNIST数据集读取 one hot 独热编码独热编码是一种稀疏向量,其中:一个向量设为1,其他元素均设为0.独热编码常用于表示拥有有限个可能值的字符串或标识符优点: 1.将离散特征的取值扩展 ...
随机推荐
- Ubuntu安装MariaDB教程
一.环境 服务器:Ubuntu 16.04.1 LTS(GUN/Linux 4.4.0-91-generic x86_64) 数据库版本:MariaDB 10.3 二.安装流程 2.1 进入Maria ...
- C语言--函数嵌套
一.实验作业 注意: 1.可以先初始化2个结构体数组数据以便测试. 2.要求用模块化方式组织程序结构,合理设计各自定义函数.同时,程序能够进行异常处理,检查用户输入数据的有效性,用户输入数据有错误,如 ...
- SQLSERVER2012的分页新功能
SQLSERVER2012的分页新功能 简介 SQL Server 2012中在Order By子句之后新增了OFFSET和FETCH子句来限制输出的行数从而达到了分页效果.相比较SQL Server ...
- 软件工程第三次作业-结对作业NO.1
第一次结对作业 结对人员: 潘伟靖 170320077 张 松 170320079 方案分析 我们对所供的资料进行分析,如下: 从提供的资料可以看出,需要解决的问题以及满足的需求主要有两类目标用户,各 ...
- 20145237 实验五《Java网络编程》
20145237 实验五<Java网络编程> 一.实验内容 •1.运行下载的TCP代码,结对进行,一人服务器,一人客户端: •2.利用加解密代码包,编译运行代码,一人加密,一人解密: •3 ...
- 算法题丨Two Sum
描述 Given an array of integers, return indices of the two numbers such that they add up to a specific ...
- python3+beautifulSoup4.6抓取某网站小说(四)多线程抓取
上一篇多文章,是二级目录,根目录"小说",二级目录"作品名称",之后就是小说文件. 本篇改造了部分代码,将目录设置为根目录->作者目录->作品目录- ...
- emqtt 试用(三)mqtt 知识
一.概念 MQTT 协议客户端库: https://github.com/mqtt/mqtt.github.io/wiki/libraries 例如,mosquitto_sub/pub 命令行发布订阅 ...
- Spring知识点回顾(03)Bean的 Scope
sigleton prototype request session globalsession stepscope
- Easyui Datagrid 修改显示行号列宽度
EasyUI中Datagrid的第一列显示行号,可是如果数据量大的的时候,显示行号的那一列数据会显示不完全的. 可以通过修改Datagrid的样式来解决这个问题,在样式中加入下面这个样式,就可以自己修 ...