spark概念、编程模型和模块概述
http://blog.csdn.net/pipisorry/article/details/50931274
spark基本概念
Spark一种与 Hadoop 相似的通用的集群计算框架,通过将大量数据集计算任务分配到多台计算机上,在性能和迭代计算上很有看点,提供高效内存计算,现在是Apache孵化的顶级项目。
Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架,而Scala的语言特点也铸就了大部分Spark的成功。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。
虽然 Spark 与 Hadoop 有相似之处,但它提供了具有有用差异的一个新的集群计算框架。首先,Spark 是为集群计算中的特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。为了优化这些类型的工作负载,Spark 引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟。
Spark 还引进了名为 弹性分布式数据集 (RDD) 的抽象。RDD 是分布在一组节点中的只读对象集合。这些集合是弹性的,如果数据集一部分丢失,则可以对它们进行重建。重建部分数据集的过程依赖于容错机制,该机制可以维护 “血统”(即充许基于数据衍生过程重建部分数据集的信息)。RDD 被表示为一个 Scala 对象,并且可以从文件中创建它;一个并行化的切片(遍布于节点之间);另一个 RDD 的转换形式;并且最终会彻底改变现有 RDD 的持久性,比如请求缓存在内存中。
Spark 中的应用程序称为驱动程序,这些驱动程序可实现在单一节点上执行的操作或在一组节点上并行执行的操作。与 Hadoop 类似,Spark 支持单节点集群或多节点集群。对于多节点操作,Spark 依赖于 Mesos 集群管理器。Mesos 为分布式应用程序的资源共享和隔离提供了一个有效平台。该设置充许 Spark 与 Hadoop 共存于节点的一个共享池中。
如果你熟悉Hadoop,那么你知道分布式计算框架要解决两个问题:如何分发数据和如何分发计算。Hadoop使用HDFS来解决分布式数据问题,MapReduce计算范式提供有效的分布式计算。类似的,Spark拥有多种语言的函数式编程API,提供了除map和reduce之外更多的运算符,这些操作是通过一个称作弹性分布式数据集(resilient distributed datasets, RDDs)的分布式数据框架进行的。本质上,RDD是种编程抽象,代表可以跨机器进行分割的只读对象集合。RDD可以从一个继承结构(lineage)重建(因此可以容错),通过并行操作访问,可以读写HDFS或S3这样的分布式存储,更重要的是,可以缓存到worker节点的内存中进行立即重用。由于RDD可以被缓存在内存中,Spark对迭代应用特别有效,因为这些应用中,数据是在整个算法运算过程中都可以被重用。大多数机器学习和最优化算法都是迭代的,使得Spark对数据科学来说是个非常有效的工具。另外,由于Spark非常快,可以通过类似Python REPL的命令行提示符交互式访问。
Spark库本身包含很多应用元素,这些元素可以用到大部分大数据应用中,其中包括对大数据进行类似SQL查询的支持,机器学习和图算法,甚至对实时流数据的支持。
spark核心组件
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。对熟悉Hive和HiveQL的人,Spark可以拿来就用。
Spark Streaming:允许对实时数据流进行处理和控制。很多实时数据库(如Apache Store)可以处理实时数据。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。之前可选的大数据机器学习库Mahout,将会转到Spark,并在未来实现。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
由于这些组件满足了很多大数据需求,也满足了很多数据科学任务的算法和计算上的需要,Spark快速流行起来。不仅如此,Spark也提供了使用Scala、Java和Python编写的API;满足了不同团体的需求,允许更多数据科学家简便地采用Spark作为他们的大数据解决方案。
spark.mllib和spark.ml
Spark MLlib 历史比较长了,1.0 以前的版本中已经包含了,提供的算法实现都是基于原始的 RDD,从学习角度上来讲,其实比较容易上手。如果您已经有机器学习方面的经验,那么您只需要熟悉下 MLlib 的 API 就可以开始数据分析工作了。想要基于这个包提供的工具构建完整并且复杂的机器学习流水线是比较困难的。
Spark ML Pipeline 从 Spark1.2 版本开始,目前已经从 Alpha 阶段毕业,成为可用并且较为稳定的新的机器学习库。ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件,使用 ML Pipeline API,我们可以很方便的把数据处理,特征转换,正则化,以及多个机器学习算法联合起来,构建一个单一完整的机器学习流水线。显然,这种新的方式给我们提供了更灵活的方法,而且这也更符合机器学习过程的特点。
从官方文档来看,Spark ML Pipeline 虽然是被推荐的机器学习方式,但是并不会在短期内替代原始的 MLlib 库,因为 MLlib 已经包含了丰富稳定的算法实现,并且部分 ML Pipeline 实现基于 MLlib。而且就笔者看来,并不是所有的机器学习过程都需要被构建成一个流水线,有时候原始数据格式整齐且完整,而且使用单一的算法就能实现目标,我们就没有必要把事情复杂化,采用最简单且容易理解的方式才是正确的选择。
Spark的执行
本质上,Spark应用作为独立的进程运行,由驱动程序中的SparkContext协调。这个context将会连接到一些集群管理者(如YARN),这些管理者分配系统资源。集群上的每个worker由执行者(executor)管理,执行者反过来由SparkContext管理。执行者管理计算、存储,还有每台机器上的缓存。
重点是应用代码由驱动程序发送给执行者,执行者指定context和要运行的任务。执行者与驱动程序通信进行数据分享或者交互。驱动程序是Spark作业的主要参与者,因此需要与集群处于相同的网络。这与Hadoop代码不同,Hadoop中你可以在任意位置提交作业给JobTracker,JobTracker处理集群上的执行。
Spark-0.8源码流程图

spark相关论文
M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica, “Spark: cluster computing with working sets,” in Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, 2010, pp. 10–10.
M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauley, M. J. Franklin, S. Shenker, and I. Stoica, “Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing,” in Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation, 2012, pp. 2–2.
Spark编程模型
1.1 术语定义
l应用程序(Application): 基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor;
l驱动程序(Driver Program):运行Application的main()函数并且创建SparkContext,通常用SparkContext代表Driver Program;
l执行单元(Executor): 是为某Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors;
l集群管理程序(Cluster Manager): 在集群上获取资源的外部服务(例如:Standalone、Mesos或Yarn);
l操作(Operation):作用于RDD的各种操作分为Transformation和Action;
1.2 模型组成
Spark应用程序可分两部分:Driver部分和Executor部分
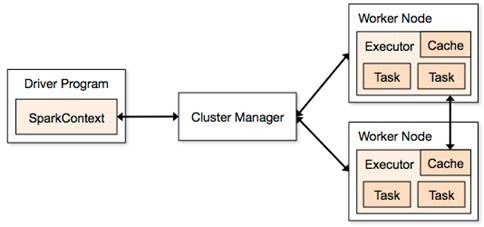
1.2.1 Driver部分
Driver部分主要是对SparkContext进行配置、初始化以及关闭。初始化SparkContext是为了构建Spark应用程序的运行环境,在初始化SparkContext,要先导入一些Spark的类和隐式转换;在Executor部分运行完毕后,需要将SparkContext关闭。
1.2.2 Executor部分
Spark应用程序的Executor部分是对数据的处理,数据分三种:
1.2.2.1 原生数据
包含原生的输入数据和输出数据
l对于输入原生数据,Spark目前提供了两种:
Ø Scala集合数据集:如Array(1,2,3,4,5),Spark使用parallelize方法转换成RDD
Ø Hadoop数据集:Spark支持存储在hadoop上的文件和hadoop支持的其他文件系统,如本地文件、HBase、SequenceFile和Hadoop的输入格式。例如Spark使用txtFile方法可以将本地文件或HDFS文件转换成RDD
l对于输出数据,Spark除了支持以上两种数据,还支持scala标量
Ø 生成Scala标量数据,如count(返回RDD中元素的个数)、reduce、fold/aggregate;返回几个标量,如take(返回前几个元素)。
Ø 生成Scala集合数据集,如collect(把RDD中的所有元素倒入 Scala集合类型)、lookup(查找对应key的所有值)。
Ø 生成hadoop数据集,如saveAsTextFile、saveAsSequenceFile
1.2.2.2 RDD
RDD具体在下一节中详细描述,RDD提供了四种算子:
l输入算子:将原生数据转换成RDD,如parallelize、txtFile等
l转换算子:最主要的算子,是Spark生成DAG图的对象,转换算子并不立即执行,在触发行动算子后再提交给driver处理,生成DAG图 --> Stage --> Task --> Worker执行。
l缓存算子:对于要多次使用的RDD,可以缓冲加快运行速度,对重要数据可以采用多备份缓存。
l行动算子:将运算结果RDD转换成原生数据,如count、reduce、collect、saveAsTextFile等。
1.2.2.3 共享变量
在Spark运行时,一个函数传递给RDD内的patition操作时,该函数所用到的变量在每个运算节点上都复制并维护了一份,并且各个节点之间不会相互影响。但是在Spark Application中,可能需要共享一些变量,提供Task或驱动程序使用。Spark提供了两种共享变量:
l广播变量(Broadcast Variables):可以缓存到各个节点的共享变量,通常为只读
– 广播变量缓存到各个节点的内存中,而不是每个 Task
– 广播变量被创建后,能在集群中运行的任何函数调用
– 广播变量是只读的,不能在被广播后修改
– 对于大数据集的广播, Spark 尝试使用高效的广播算法来降低通信成本
使用方法:
val broadcastVar = sc.broadcast(Array(1, 2, 3))
l累计器:只支持加法操作的变量,可以实现计数器和变量求和。用户可以调用SparkContext.accumulator(v)创建一个初始值为v的累加器,而运行在集群上的Task可以使用“+=”操作,但这些任务却不能读取;只有驱动程序才能获取累加器的值。
使用方法:
val accum = sc.accumulator(0)
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum + = x)
accum.value
val num=sc.parallelize(1 to 100)
弹性分布式数据集RDD
[Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD]
Spark模块概述
spark的ML和MLLib两个包区别和联系
1.技术角度上,面向的数据集类型不一样:ML的API是面向Dataset的(Dataframe是Dataset的子集,也就是Dataset[Row]),mllib是面对RDD的。Dataset和RDD有啥不一样呢?Dataset的底端是RDD。Dataset对RDD进行了更深一层的优化,比如说有sql语言类似的黑魔法,Dataset支持静态类型分析所以在compiletime就能报错,各种combinators(map,foreach等)性能会更好,等等。
2. 编程过程上,构建机器学习算法的过程不一样:ML提倡使用pipelines,把数据想成水,水从管道的一段流入,从另一端流出:
大体概念:DataFrame => Pipeline => A new DataFrame
Pipeline: 是由若干个Transformers和Estimators连起来的数据处理过程
Transformer:入:DataFrame => 出: Data Frame
Estimator:入:DataFrame => 出:Transformer
Mllib就是一些机器学习算法的合集,无组织无纪律,一盘散沙,形态各异,经常不带作业,常年出去罚站。所以Mllib很杂很难写。
3. 对于开发者来言:如果你只是处理数据,构建机器学习算法来解决工程问题,就别想mllib和rdd了,出活最重要。如果你是Spark的开发者或者拓展者,那你必须配着茴香豆学习mllib和rdd的四种写法啊。不过撸出来一定要符合Spark 2.0的API规范哦。要不然没人用你的程序。
4. 如说上升到哲学玄学周易的角度上:我觉得Scala一直缺一个对“集”这个概念的有效表达。虽然有一个scala.collection,可是现在的数据量,这货明显不够撸啊。Dataset目前是对“集”这个概念最合理抽象。就像给哑巴一张嘴,可以说出关于数据的很多故事。
It divides into two packages:
- spark.mllib contains the original API built on top of RDDs.
- spark.ml provides higher-level API built on top of DataFrames for constructing ML pipelines.
Using spark.ml is recommended because with DataFrames the API is more versatile and flexible. But we will keep supportingspark.mllib along with the development of spark.ml. Users should be comfortable using spark.mllib features and expect more features coming. Developers should contribute new algorithms to spark.ml if they fit the ML pipeline concept well, e.g., feature extractors and transformers.
[请问各位大神,spark的ML和MLLib两个包区别和联系?!?]
from: http://blog.csdn.net/pipisorry/article/details/50931274
ref: [别再比较Hadoop和Spark了,那不是设计人员的初衷]
[DPark安装及相关资料整理{DPark是豆瓣开发的基于Mesos的开源分布式计算框架,是spark的python版克隆}https://github.com/douban/dpark/]
spark概念、编程模型和模块概述的更多相关文章
- Spark之编程模型RDD
前言:Spark编程模型两个主要抽象,一个是弹性分布式数据集RDD,它是一种特殊集合,支持多种数据源,可支持并行计算,可缓存:另一个是两种共享变量,支持并行计算的广播变量和累加器. 1.RDD介绍 S ...
- Spark Streaming 实现思路与模块概述
一.基于 Spark 做 Spark Streaming 的思路 Spark Streaming 与 Spark Core 的关系可以用下面的经典部件图来表述: 在本节,我们先探讨一下基于 Spark ...
- spark wordcount 编程模型详解
spark wordcount中一共经历多少个RDD?以及RDD提供的toDebugString 在控制台输入spark-shell 系统会默认创建一个SparkContext sc h ...
- Spark 编程模型(上)
Spark的编程模型 核心概念(注意对比MR里的概念来学习) Spark Application的组成 Spark Application基本概念 Spark Application编程模型 回顾sc ...
- Spark编程模型(博主推荐)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Spark1.0.0 编程模型
Spark Application能够在集群中并行执行,其关键是抽象出RDD的概念(详见RDD 细解),也使得Spark Application的开发变得简单明了.下图浓缩了Spark的编程模型. w ...
- Spark编程模型
主要参考: Spark官方文档:http://spark.apache.org/docs/latest/programming-guide.html 炼数成金PPT:02Spark编程模型和解析 本文 ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- DataFrame编程模型初谈与Spark SQL
Spark SQL在Spark内核基础上提供了对结构化数据的处理,在Spark1.3版本中,Spark SQL不仅可以作为分布式的SQL查询引擎,还引入了新的DataFrame编程模型. 在Spark ...
随机推荐
- glusterfs 4.0.1 api 分析笔记1
一般来说,我们写个客户端程序大概的样子是这样的: /* glfs_example.c */ // gcc -o glfs_example glfs_example.c -L /usr/lib64/ - ...
- Docker 基础 : 镜像
目录 获取镜像 查看镜像信息 搜索镜像 删除镜像 创建镜像 导出和导入镜像 上传镜像 总结 镜像是 Docker 的三大核心概念之一.Docker 运行容器前需要本地存在对应的镜像,如果本地没有对应的 ...
- Linux学习之CentOS(十二)----磁盘管理之 认识ext文件系统(转)
认识ext文件系统 硬盘组成与分割 文件系统特性 Linux 的 EXT2 文件系统(inode) 与目录树的关系 EXT2/EXT3 文件的存取与日志式文件系统的功能 Linux 文件系统的运行 挂 ...
- SpringMVC中HandlerMapping的三种配置方式
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE beans PUBLIC "-/ ...
- python显示中文出错以及抛出UnicodeDecodeError的处理办法
程序开头粘贴如下代码即可: # -*- coding:utf-8 -*- import sys default_encoding = 'utf-8' if sys.getdefaultencoding ...
- 63. Unique Paths II(中等, 能独立做出来的DP类第二个题^^)
Follow up for "Unique Paths": Now consider if some obstacles are added to the grids. How m ...
- Lintcode393 Best Time to Buy and Sell Stock IV solution 题解
[题目描述] Say you have an array for which the i th element is the price of a given stock on day i. Desi ...
- Ubuntu 16.04LTS 安装 MATLAB 2014B
环境:Ubuntu 16.04LTS 软件:MATLAB 2014B MATLAB 2014B 下载地址(带Crack): 链接: https://pan.baidu.com/s/1nvGtmEd 密 ...
- 排序算法的C语言实现(上 比较类排序:插入排序、快速排序与归并排序)
总述:排序是指将元素集合按规定的顺序排列.通常有两种排序方法:升序排列和降序排列.例如,如整数集{6,8,9,5}进行升序排列,结果为{5,6,8,9},对其进行降序排列结果为{9,8,6,5}.虽然 ...
- 实验与作业(Python)-03 Python程序实例解析
截止日期: 要求: 下周实验课前上交,做好后在实验课上检查可获取平时分. 做出进阶或选做的的请用清晰的标致标识出来,方便老师批改 本次作业:可提交也可不提交.作业算平时成绩. 本次作业内容量较大,请组 ...