java集合HashMap、HashTable、HashSet详解
一、Set和Map关系
Set代表集合元素无序,集合元素不可重复的集合,Map代表一种由多个key-value组成的集合,map集合是set集合的扩展只是名称不同,对应如下

二、HashMap的工作原理
public V put(K paramK, V paramV) {
//如果key为空,调用putForNullKey方法
if (paramK == null)
return putForNullKey(paramV);
//根据key的keyCode计算Hash值
int i = hash(paramK.hashCode());
//搜索指定hash值的对应在table中的索引
int j = indexFor(i, this.table.length);
//如果j索引处的Entry不为空,通过循环遍历localEntry元素的下一个元素
for (Entry localEntry = this.table[j]; localEntry != null; localEntry = localEntry.next) {
Object localObject1;
//找到指定key与放入key相等(hash值相同,通过equals比较返回true)
if ((localEntry.hash == i)
&& ((((localObject1 = localEntry.key) == paramK) || (paramK
.equals(localObject1))))) {
Object localObject2 = localEntry.value;
localEntry.value = paramV;
localEntry.recordAccess(this);
return localObject2;
}
}
//如果j索引Entry为null,此处没有Entry
this.modCount += 1;
//将key、value添加到i索引处
addEntry(i, paramK, paramV, j);
return null;
}
void addEntry(int paramInt1, K paramK, V paramV, int paramInt2) {
//获取指定bucketIndex索引处Entry
Entry localEntry = this.table[paramInt2];
//将新创建的Entry放入bucketIndex索引处,并让新的Entry指向原来的Entry
this.table[paramInt2] = new Entry(paramInt1, paramK, paramV, localEntry);
//如果map中的key-value数量超过
if (this.size++ >= this.threshold)
//table对象的长度扩充到2倍
resize(2 * this.table.length);
}
put方法三种情况,如图:
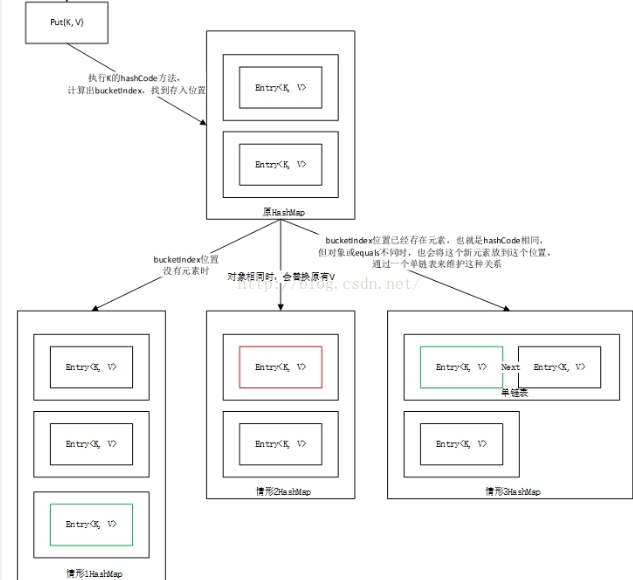
get()方法:当HashMap的每个bucket里存储的Entry只是单个Entry,即没有通过指针产生Entry链时,此时HashMap具有最好的性能。当程序通过key取出对应value时,系统先计算出该key的hashCode()返回值,再根据该hashCode返回值找出该key在table数组中的索引,然后取出该索引处的Entry,最后返回该key对应的value值。get源码如下:
public V get(Object paramObject) {
//如果key为空,调用getForNullKey取出对应的value
if (paramObject == null)
return getForNullKey();
//根据key的hashCode值计算hash码
int i = hash(paramObject.hashCode());
//直接取出table数组中指定索引处的值
Entry localEntry = this.table[indexFor(i, this.table.length)];
while (localEntry != null) {
Object localObject;
//如果该Entry的key与被搜索key相同
if ((localEntry.hash == i)
&& ((((localObject = localEntry.key) == paramObject) || (paramObject
.equals(localObject)))))
return localEntry.value;
//搜索该Entry链的下一个
localEntry = localEntry.next;
}
return null;
}
从代码看出,HashMap的每个bucket里只有一个Entry,HashMap可以根据索引快速取出该bucket里的Entry。
在发生Hash冲突的情况下,单个bucket里存储的不是一个Entry,而是一个Entry链,系统只能按顺序遍历每个Entry,直到找到想搜索的Entry。
HashMap有两个参数影响其性能:
1. 初始容量和加载因子。默认初始容量是16,加载因子是0.75。容量是哈希表中桶(Entry数组)的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,通过调用rehash 方法将容量翻倍。
2. 加载因子过高虽然减少了空间开销,但同时也增加了查询成本(加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地降低rehash 操作次数。如果初始容量大于最大条目数除以加载因子(实际上就是最大条目数小于初始容量*加载因子),则不会发生 rehash 操作。
3.HashMap存放的元素越来越多,到达临界值(阀值)threshold时,就要对Entry数组扩容,这是Java集合类框架最大的魅力,HashMap在扩容时,新数组的容量将是原来的2倍,由于容量发生变化,原有的每个元素需要重新计算bucketIndex,再存放到新数组中去,也就是所谓的rehash。HashMap默认初始容量16,加载因子0.75,也就是说最多能放16*0.75=12个元素,当put第13个时,HashMap将发生rehash,rehash的一系列处理比较影响性能,所以当我们需要向HashMap存放较多元素时,最好指定合适的初始容量和加载因子,否则HashMap默认只能存12个元素,将会发生多次rehash操作。
三、HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,主要的区别有:线程安全性,同步(synchronization),以及速度。HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
java集合HashMap、HashTable、HashSet详解的更多相关文章
- 【java基础】java集合之HashTable,HashSet,HashMap
[一]HashSet (1)HashSet内部维护的是一个HashMap,具体原理见java集合之HashMap [二]HashTable (1)HashTable内部维护的是一个Entry的数组.E ...
- JAVA集合LIST MAP SET详解
1. 集合框架介绍 我们知道,计算机的优势在于处理大量的数据,在编程开发中,为处理大量的数据,必须具备相应的存储结构,之前学习的数组可以用来存储并处理大量类型相同的数据,但是通过上面的课后练习,会发现 ...
- Java集合04——fail-fast&fail-safe 详解
在前几个回合中,我们已经详细了解过了 Java 集合中的List.Set 和 Map,对这部分内容感兴趣的朋友可以关注我的公众号「Java面典」了解.今天我们将为各位介绍集合的失败机制--fail-f ...
- Java集合——TreeMap源码详解
)TreeMap 是一个有序的key-value集合,它是通过红黑树实现的.因为红黑树是平衡的二叉搜索树,所以其put(包含update操作).get.remove的时间复杂度都为log(n). (2 ...
- Java集合——HashMap,HashTable,ConcurrentHashMap区别
Map:“键值”对映射的抽象接口.该映射不包括重复的键,一个键对应一个值. SortedMap:有序的键值对接口,继承Map接口. NavigableMap:继承SortedMap,具有了针对给定搜索 ...
- Java集合——LinkedHashMap源码详解
个KV.LinkedHashMap不仅像HashMap那样对其进行基于哈希表和单链表的Entry数组+ next链表的存储方式,而且还结合了LinkedList的优点,为每个Entry节点增加了前驱和 ...
- Java集合——ArrayList源码详解
) ArrayList 实现了RandomAccess, Cloneable, java.io.Serializable三个标记接口,表示它自身支持快速随机访问,克隆,序列化. public clas ...
- Java集合——LinkedList源码详解
)LinkedList直接继承于AbstractSequentialList,同时实现了List接口,也实现了Deque接口. AbstractSequentialList为顺序访问的数据存储结构提供 ...
- java的集合框架最全详解
java的集合框架最全详解(图) 前言:数据结构对程序设计有着深远的影响,在面向过程的C语言中,数据库结构用struct来描述,而在面向对象的编程中,数据结构是用类来描述的,并且包含有对该数据结构操作 ...
- (7)Java数据结构--集合map,set,list详解
MAP,SET,LIST,等JAVA中集合解析(了解) - clam_clam的专栏 - CSDN博---有颜色, http://blog.csdn.net/clam_clam/article/det ...
随机推荐
- Ubuntu快速截图
以前截图,都是按Print键全屏截图,Alt+Print可以截当前的窗口.同时把系统自带的截图工具放到面板上,用的时候点击一下,再选择区域截图,很是不方便.不过,Ubuntu允许自己定义快捷键.要自己 ...
- Java深拷贝浅拷贝
首先,Java中常用的拷贝操作有三个,operator = .拷贝构造函数 和 clone()方法.由于Java不支持运算符重载,我们无法在自己的自定义类型中定义operator=.拷贝构造函数大家应 ...
- ThreadLocal深入理解 修订版
本文是传智博客多线程视频的学习笔记. 原版本见 http://blog.csdn.net/dlf123321/article/details/42531979 ThreadLocal是一个和线程安全相 ...
- Linxu命令与文件的搜索 - which, whereis, locate, find
which (寻找『运行档』) [root@www ~]# which [-a] command 选项或参数: -a :将所有由 PATH 目录中可以找到的命令均列出,而不止第一个被找到的命令名称 范 ...
- application之OnLowMemory()和 OnTrimMemory(level)讲解
1. OnLowMemory OnLowMemory是Android提供的API,在系统内存不足,所有后台程序(优先级为background的进程,不是指后台运行的进程)都被杀死时,系统会调用OnLo ...
- ruby TkPackage can't find package BWidget 之解决办法
一个特别短的ruby/tk代码: require 'tkextlib\iwidgets' require 'tkextlib\bwidget' x = 0 101.times {|i| x+=i} T ...
- webpack 4.x 遇到的错误
由于之前重装电脑,很多之前的小Demo 现在都跑不起来.特别是webpack一直在报错. webpack 安装node 全局安装webpack,webpack-cli(一定要全局安装) 项目初始化 w ...
- Axis创建webservice客户端和服务端
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本人声明.否则将追究法律责任. 作者:永恒の_☆ 地址:http://blog.csdn.net/chenghui0317/ ...
- Android反编译和再打包神器:Apktool
首先推荐一下这东东,官网:https://ibotpeaches.github.io/Apktool/ 安装.使用之类的看官方文档吧,写这个博客主要是mark一下这东西. 这玩意只能供打包党来用,要想 ...
- Using SSH and SFTP in Mac OS X
http://answers.stat.ucla.edu/groups/answers/wiki/7a848/ SH and SFTP are command line applications av ...