十九、Hadoop学记笔记————Hbase和MapReduce
概要:

hadoop和hbase导入环境变量:

要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到:
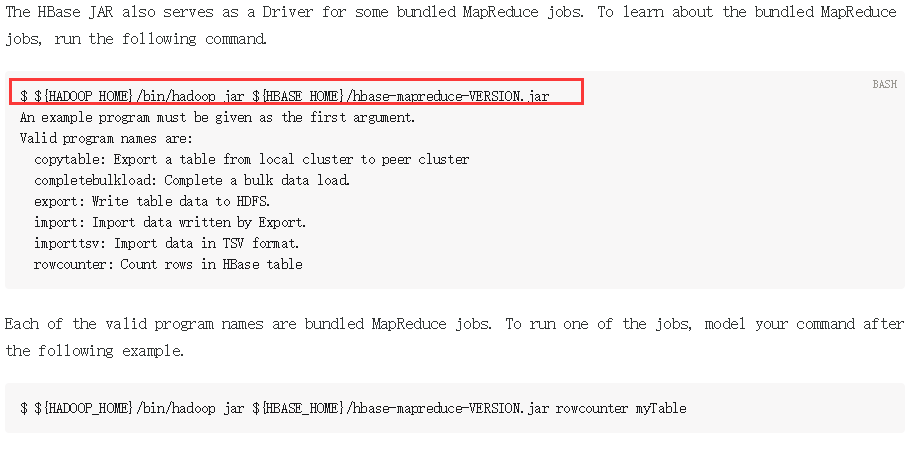
如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问Hbase的jar包:

参考官网可解决:

运行后解决:

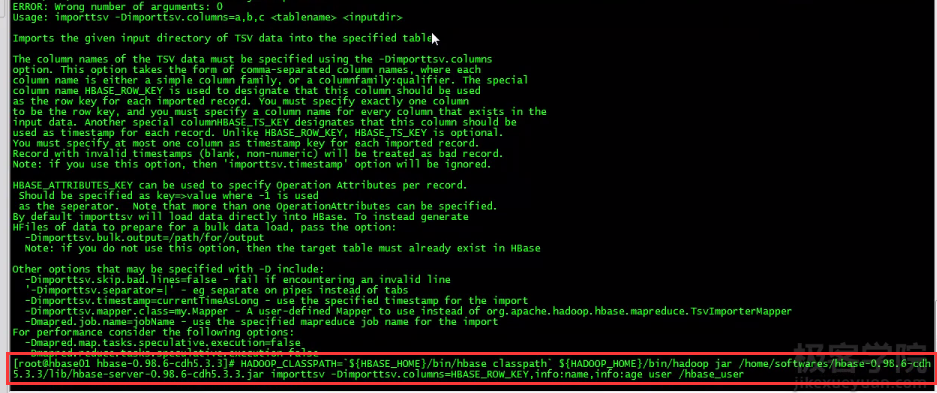
导入数据运行指令:
tsv是指以制表符为分隔符的文件
先创建测试数据,创建user文件:

上传至hdfs,并且启动hbase shell:

创建表:

之后导入数据:
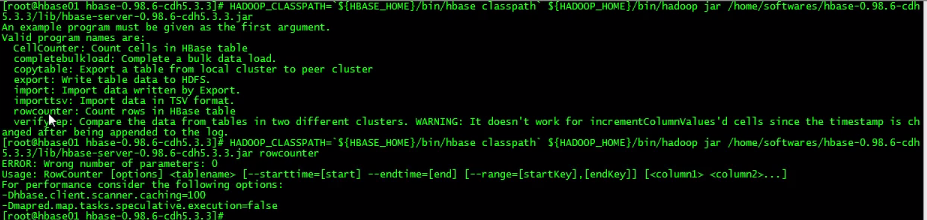
还有一些其他的方法,比如rowcounter统计行数:
接下来演示用sqoop将mysql数据考入hbase,构建测试数据:
使用import,需要先配置hbase环境变量:


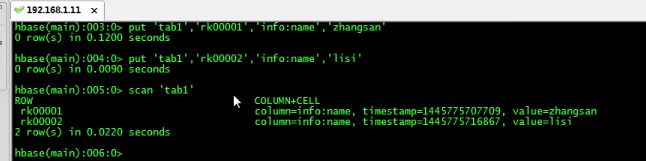
Hbase表数据的迁移:

之后编写MapReduce程序,代码如下:
package com.tyx.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class Tab2TabMapReduce extends Configured implements Tool { // mapper class
public static class TabMapper extends TableMapper<Text, Put> {
private Text rowkey = new Text(); @Override
protected void map(ImmutableBytesWritable key, Result value,Context context)
throws IOException, InterruptedException {
byte[] bytes = key.get();
rowkey.set(Bytes.toString(bytes)); Put put = new Put(bytes); for (Cell cell : value.rawCells()) {
// add cell
if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) {
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
put.add(cell);
}
}
} context.write(rowkey, put);
}
} // reduce class
public static class TabReduce extends TableReducer<Text,Put, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<Put> values,Context context)
throws IOException, InterruptedException {
for (Put put : values) {
context.write(null, put);
} }
} @Override
public int run(String[] args) throws Exception {
//create job
Job job = Job.getInstance(this.getConf(), this.getClass().getSimpleName()); // set run class
job.setJarByClass(this.getClass()); Scan scan = new Scan();
scan.setCaching(500);
scan.setCacheBlocks(false); // set mapper
TableMapReduceUtil.initTableMapperJob(
"tab1", // input table
scan , // scan instance
TabMapper.class, // set mapper class
Text.class, // mapper output key
Put.class, //mapper output value
job // set job
); TableMapReduceUtil.initTableReducerJob(
"tab2" , // output table
TabReduce.class, // set reduce class
job // set job
); job.setNumReduceTasks(1); boolean b = job.waitForCompletion(true); if(!b) {
System.err.print("error with job!!!");
} return 0;
} public static void main(String[] args) throws Exception { //create config
Configuration config = HBaseConfiguration.create(); //submit job
int status = ToolRunner.run(config, new Tab2TabMapReduce(), args); //exit
System.exit(status);
} }
运行指令:


接下来是hdfs中文件导入Hbase:
构造数据:


然后编写MapReduce程序:
package com.jkxy.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class HDFS2TabMapReduce extends Configured implements Tool{ public static class HDFS2TabMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { ImmutableBytesWritable rowkey = new ImmutableBytesWritable(); @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { String[] words = value.toString().split("\t");
//rk0001 zhangsan 33 Put put = new Put(Bytes.toBytes(words[0]));
put.add(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(words[1]));
put.add(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(words[2])); rowkey.set(Bytes.toBytes(words[0])); context.write(rowkey, put);
}
} @Override
public int run(String[] args) throws Exception { // create job
Job job = Job.getInstance(this.getConf(), this.getClass().getSimpleName()); // set class
job.setJarByClass(this.getClass()); // set path
FileInputFormat.addInputPath(job, new Path(args[0])); //set mapper
job.setMapperClass(HDFS2TabMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class); // set reduce
TableMapReduceUtil.initTableReducerJob(
"user", // set table
null,
job);
job.setNumReduceTasks(0); boolean b = job.waitForCompletion(true); if(!b) {
throw new IOException("error with job!!!");
} return 0;
} public static void main(String[] args) throws Exception {
//get configuration
Configuration conf = HBaseConfiguration.create(); //submit job
int status = ToolRunner.run(conf, new HDFS2TabMapReduce(), args); //exit
System.exit(status);
} }
运行指令
接下来演示使用BulkLaod将数据从Hdfs导入Hbase,使用该方式可以绕过WAL,memstor等步骤,加快海量数据的效率,代码如下:
package com.jkxy.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.mapreduce.PutSortReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class HFile2TabMapReduce extends Configured implements Tool { public static class HFile2TabMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { ImmutableBytesWritable rowkey = new ImmutableBytesWritable(); @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { String[] words = value.toString().split("\t"); Put put = new Put(Bytes.toBytes(words[0]));
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(words[1]));
put.add(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(words[2]));
rowkey.set(Bytes.toBytes(words[0])); context.write(rowkey, put);
}
} @Override
public int run(String[] args) throws Exception { //create job
Job job = Job.getInstance(getConf(), this.getClass().getSimpleName()); // set run jar class
job.setJarByClass(this.getClass()); // set input . output
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2])); // set map
job.setMapperClass(HFile2TabMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class); // set reduce
job.setReducerClass(PutSortReducer.class); HTable table = new HTable(getConf(), args[0]);
// set hfile output
HFileOutputFormat2.configureIncrementalLoad(job, table ); // submit job
boolean b = job.waitForCompletion(true);
if(!b) {
throw new IOException(" error with job !!!");
}
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(getConf());
// load hfile
loader.doBulkLoad(new Path(args[2]), table); return 0;
} public static void main(String[] args) throws Exception {
// get configuration
Configuration conf = HBaseConfiguration.create(); //run job
int status = ToolRunner.run(conf, new HFile2TabMapReduce(), args); // exit
System.exit(status); } }
使用如下指令:
十九、Hadoop学记笔记————Hbase和MapReduce的更多相关文章
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算 Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Y ...
- 二十一、Hadoop学记笔记————kafka的初识
这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统 Apache flume系统,用于日志收集 Apache storm系统,用于实时数据处理 Spark ...
- 学记笔记 $\times$ 巩固 · 期望泛做$Junior$
最近泛做了期望的相关题目,大概\(Luogu\)上提供的比较简单的题都做了吧\(233\) 好吧其实是好几天之前做的了,不过因为太颓废一直没有整理-- \(Task1\) 期望的定义 在概率论和统计学 ...
随机推荐
- Java学习笔记(三)Java2D组件
一 概述 Java2D的一切都基于java.awt包中的Graphics2D类,它是Graphics的子类. 为了绘制图形,需要使用面板作为画布,例如使用JPanel作为画布,面板有一个paintC ...
- PS 图像调整算法——黑白
这个算法是参考自 阿发伯 的博客: http://blog.csdn.net/maozefa 黑白调整 Photoshop CS的图像黑白调整功能,是通过对红.黄.绿.青.蓝和洋红等6种颜色的比例调节 ...
- Objective-C的面向对象特性(二)
在Objective-C语言中, 类别.类扩展(也称为匿名类别)以及协议是Objective-C 语言级别支持的模式,用来实现对类进行功能扩展. 一.类别--用来增加方法到已存在类 声明一个类别的语法 ...
- 数据结构之---二叉树C实现
学过数据结构的都知道树,那么什么是树? 树(tree)是包含n(n>0)个结点的有穷集,其中: (1)每个元素称为结点(node): (2)有一个特定的结点被称为根结点或树根(root). (3 ...
- LeetCode(40)-Merge Sorted Array
听到初爱有感 开头啰嗦两句,刚在做算法题目的时候,听到了杨宗纬的<初爱>,突然有了一种本科时候的感觉,想想自己现在研二了,青春喂了狗,我果断喝了一罐啤酒,循环这首歌到吐-.. 题目: Gi ...
- javascript语言扩展:可迭代对象(4)
js 1.7中还包含一个数组推导(array comprehension)的特性,如果不在最后介绍它好像显得不怎么完整. 数组推导其实很简单: let a = [x*x for(x in range( ...
- C# 设置Word文档保护(加密、解密、权限设置)
对于一些重要的word文档,出于防止资料被他人查看,或者防止文档被修改的目的,我们在选择文档保护时可以选择文档打开添加密码或者设置文档操作权限等,在下面的文章中将介绍如何使用类库Free Spire. ...
- PLSQL 创建自定义函数注意事项
2017-6-8周四,今天遇到的需求是,从数据库中查找出某张表的某些数据,并将这些数据做简单的加减运算再得到结果集,没有思路,后来问辉哥,给我的建议是给这些运算封装成一个SQL函数,select选择字 ...
- 什么是shell? bash和shell有什么关系?
什么是shell? bash和shell有什么关系? 博客分类: Linux 什么是Shell? shell是你(用户)和Linux(或者更准确的说,是你和Linux内核)之间的接口程序 ...
- 多台或者集群环境下如何保证spring定时器只执行一个
先说一下我们的系统, 在65和66上分别部署有weblogic节点,共计四个,在项目中我们的定时器会隔一段时间就从其它的五个系统中取数据,这时就出现了问题,本来取一次数据就可以的,现在重复执行了三次, ...