SpringCloud实战8-Bus消息总线
好了现在我们接着上一篇的随笔,继续来讲。上一篇我们讲到,我们如果要去更新所有微服务的配置,在不重启的情况下去更新配置,只能依靠spring cloud config了,但是,是我们要一个服务一个服务的发送post请求,
我们能受的了吗?这比之前的没配置中心好多了,那么我们如何继续避免挨个挨个的向服务发送Post请求来告知服务,你的配置信息改变了,需要及时修改内存中的配置信息。
这时候我们就不要忘记消息队列的发布订阅模型。让所有为服务来订阅这个事件,当这个事件发生改变了,就可以通知所有微服务去更新它们的内存中的配置信息。这时Bus消息总线就能解决,你只需要在springcloud Config Server端发出refresh,就可以触发所有微服务更新了。
如下架构图所示:

Spring Cloud Bus除了支持RabbitMQ的自动化配置之外,还支持现在被广泛应用的Kafka。在本文中,我们将搭建一个Kafka的本地环境,并通过它来尝试使用Spring Cloud Bus对Kafka的支持,实现消息总线的功能。
Kafka使用Scala实现,被用作LinkedIn的活动流和运营数据处理的管道,现在也被诸多互联网企业广泛地用作为数据流管道和消息系统。
Kafak架构图如下:
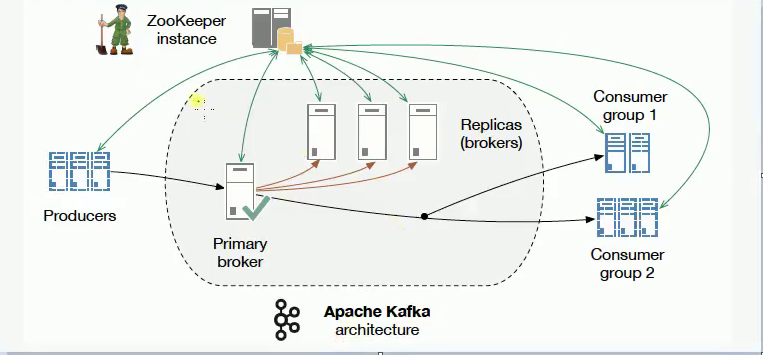
Kafka是基于消息发布/订阅模式实现的消息系统,其主要设计目标如下:
1.消息持久化:以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
2.高吞吐:在廉价的商用机器上也能支持单机每秒100K条以上的吞吐量
3.分布式:支持消息分区以及分布式消费,并保证分区内的消息顺序
4.跨平台:支持不同技术平台的客户端(如:Java、PHP、Python等)
5.实时性:支持实时数据处理和离线数据处理
6.伸缩性:支持水平扩展
Kafka中涉及的一些基本概念:
1.Broker:Kafka集群包含一个或多个服务器,这些服务器被称为Broker。
2.Topic:逻辑上同Rabbit的Queue队列相似,每条发布到Kafka集群的消息都必须有一个Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个Broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
3.Partition:Partition是物理概念上的分区,为了提供系统吞吐率,在物理上每个Topic会分成一个或多个Partition,每个Partition对应一个文件夹(存储对应分区的消息内容和索引文件)。
4.Producer:消息生产者,负责生产消息并发送到Kafka Broker。
5.Consumer:消息消费者,向Kafka Broker读取消息并处理的客户端。
6.Consumer Group:每个Consumer属于一个特定的组(可为每个Consumer指定属于一个组,若不指定则属于默认组),组可以用来实现一条消息被组内多个成员消费等功能。
可以从kafka的架构图看到Kafka是需要Zookeeper支持的,你需要在你的Kafka配置里面指定Zookeeper在哪里,它是通过Zookeeper做一些可靠性的保证,做broker的主从,我们还要知道Kafka的消息是以topic形式作为组织的,Producers发送topic形式的消息,
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
<version>1.4..RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.3..RELEASE</version>
</dependency> <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
<version>1.3..RELEASE</version>
</dependency>
接着要注意一下,client1的配置文件要改为bootstrap.yml,因为这种配置格式,是优先加载的,上一篇随笔有讲过,client1的配置如下:
server:
port:
spring:
application:
name: cloud-config
cloud:
config:
#启动什么环境下的配置,dev 表示开发环境,这跟你仓库的文件的后缀有关,比如,仓库配置文件命名格式是cloud-config-dev.properties,所以profile 就要写dev
profile: dev
discovery:
enabled: true
#这个名字是Config Server端的服务名字,不能瞎写。
service-id: config-server
#注册中心
eureka:
client:
service-url:
defaultZone: http://localhost:8888/eureka/,http://localhost:8889/eureka/
#是否需要权限拉去,默认是true,如果不false就不允许你去拉取配置中心Server更新的内容
management:
security:
enabled: false
接着启动类如下:
@SpringBootApplication
@EnableDiscoveryClient
public class Client1Application { public static void main(String[] args) {
SpringApplication.run(Client1Application.class, args);
}
}
接着将client中的TestController赋值一份到client1中,代码如下:
@RestController
//这里面的属性有可能会更新的,git中的配置中心变化的话就要刷新,没有这个注解内,配置就不能及时更新
@RefreshScope
public class TestController { @Value("${name}")
private String name;
@Value("${age}")
private Integer age; @RequestMapping("/test")
public String test(){
return this.name+this.age;
}
}
接着还要在先前的随笔中的模块中的Config Server加入如下配置:
#是否需要权限拉去,默认是true,如果不false就不允许你去拉取配置中心Server更新的内容
management:
security:
enabled: false
接着还要做一点就是,在config-client,config-client1,和config-Server都要引入kafka的依赖,如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
<version>1.3..RELEASE</version>
</dependency>
我们工程准备好了,暂时先放在这里,下面进行Kafka的安装下载,首先我们去Kafka官网kafka.apache.org/downloads 下来官网推荐的版本,
首先我们进到下载好的Kafka目录中kafka_2.11-1.1.0\bin\windows 下编辑kafka-run-class.bat如下:
找到这条配置 如下:
set COMMAND=%JAVA% %KAFKA_HEAP_OPTS% %KAFKA_JVM_PERFORMANCE_OPTS% %KAFKA_JMX_OPTS% %KAFKA_LOG4J_OPTS% -cp %CLASSPATH% %KAFKA_OPTS% %*
可以看到%CLASSPATH%没有双引号,
因此用双引号括起来,不然启动不起来的,报你JDK没安装好,修改后如下:
set COMMAND=%JAVA% %KAFKA_HEAP_OPTS% %KAFKA_JVM_PERFORMANCE_OPTS% %KAFKA_JMX_OPTS% %KAFKA_LOG4J_OPTS% -cp "%CLASSPATH%" %KAFKA_OPTS% %*
接着,打开config文件夹中的server.properties配置如下:
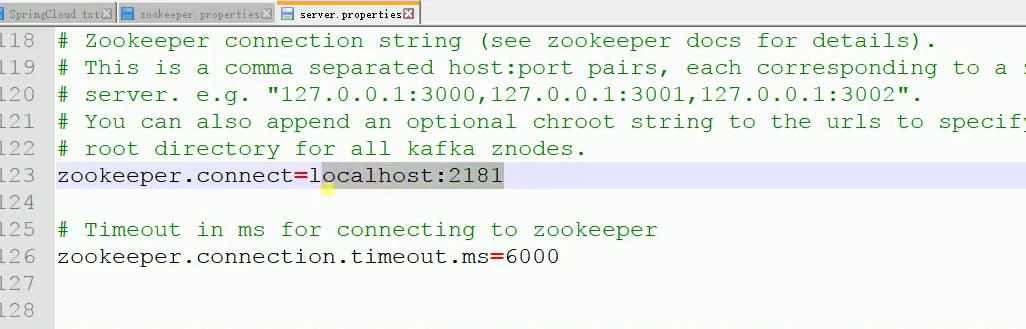
可以看到是连接到本地的zookeeper就行了。
接着我们进行先启动zookeeper,再启动Kafka,如下:
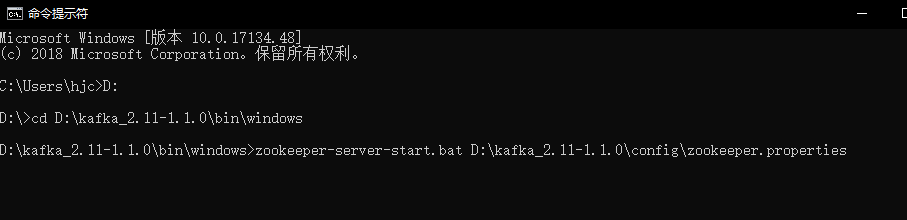


当看到上面的信息证明启动Zookeeper启动成功。、
接下来再开一个CMD启动Kafka,如下:
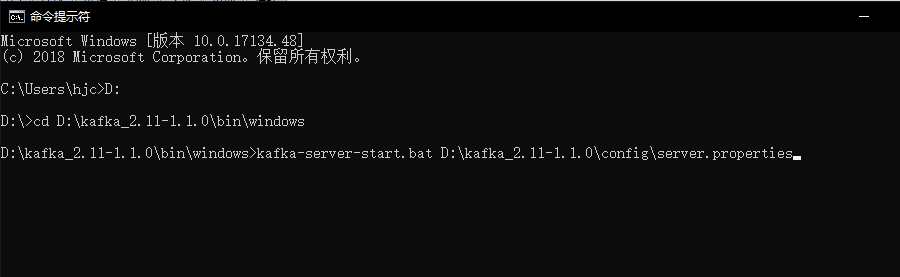

看到这些信息说明Kafka启动成功了
好了,接下来把前面的工程,两个注册中心,一个springcloud-config-server,两个springcloud-config-client,springcloud-config-client1启动起来,
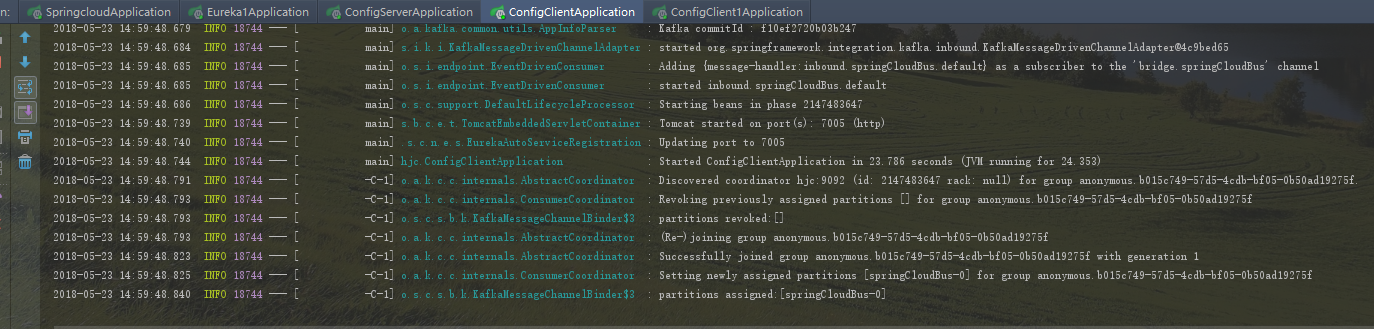
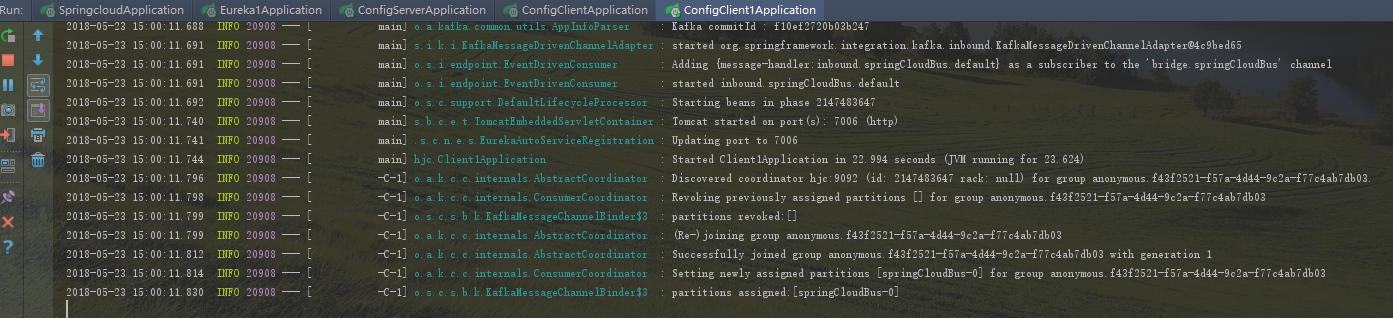
可以看到springcloudBus是在0分片上,如果两个config-client启动都出现上面信息,证明启动成功了。
好了现在我们进行访问一下config-server端,如下:

再访问两个client,如下:
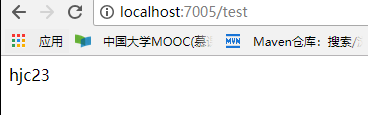

好了,好戏开始了,现在我们去git仓库上修改配置中心的文件,将年龄改为24,如下:

接下来,我们我们用refresh刷新配置服务端配置,通知两个client去更新内存中的配置信息。用postman发送localhost:7000/bus/refresh,如下:

可以看到没有返回什么信息,但是不要担心,这是成功的通知所有client去更新了内存中的信息了。
接着我们分别重新请求config-server,两个client,刷新页面,结果如下:
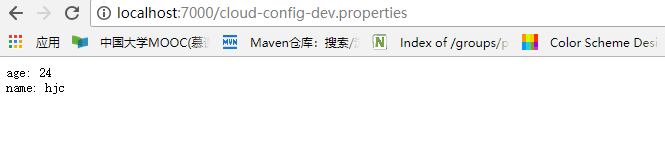
两个client如下:
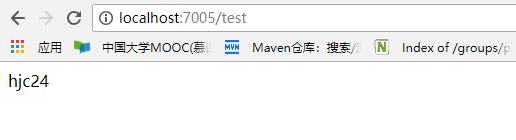
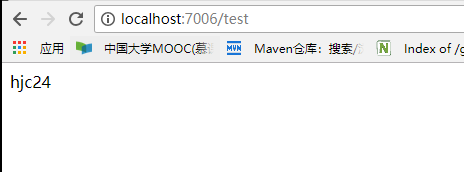
可以看到所有client自动更新内存中的配置信息了。
到目前为止,上面都是刷新说有的配置的信息的,如果我们想刷新某个特定服务的配置信息也是可以的。我们可以指定刷新范围,如下:
指定刷新范围
上面的例子中,我们通过向服务实例请求Spring Cloud Bus的/bus/refresh接口,从而触发总线上其他服务实例的/refresh。但是有些特殊场景下(比如:灰度发布),我们希望可以刷新微服务中某个具体实例的配置。
Spring Cloud Bus对这种场景也有很好的支持:/bus/refresh接口还提供了destination参数,用来定位具体要刷新的应用程序。比如,我们可以请求/bus/refresh?destination=服务名字:9000,此时总线上的各应用实例会根据destination属性的值来判断是否为自己的实例名,
若符合才进行配置刷新,若不符合就忽略该消息。
destination参数除了可以定位具体的实例之外,还可以用来定位具体的服务。定位服务的原理是通过使用Spring的PathMatecher(路径匹配)来实现,比如:/bus/refresh?destination=customers:**,该请求会触发customers服务的所有实例进行刷新。
SpringCloud实战8-Bus消息总线的更多相关文章
- SpringCloud学习之Bus消息总线实现配置自动刷新(九)
前面两篇文章我们聊了Spring Cloud Config配置中心,当我们在更新github上面的配置以后,如果想要获取到最新的配置,需要手动刷新或者利用webhook的机制每次提交代码发送请求来刷新 ...
- 多项目如何高效协同合作 | springcloud系列之bus消息总线
前言 在springcloud config章节中我们完成了配种中心的搭建,以及通过配置中心完成配置的抽离通过springcloud config模块我们将配置抽离到git仓库中我们不必要每次为了改配 ...
- 跟我学SpringCloud | 第八篇:Spring Cloud Bus 消息总线
SpringCloud系列教程 | 第八篇:Spring Cloud Bus 消息总线 Springboot: 2.1.6.RELEASE SpringCloud: Greenwich.SR1 如无特 ...
- SpringCloud之Config配置中心+BUS消息总线原理及其配置
一.配置中心作用 在常规的开发中,每个微服务都包含代码和配置.其配置包含服务配置.各类开关和业务配置.如果系统结构中的微服务节点较少,那么常规的代码+配置的开发方式足以解决问题.当系统逐步迭代,其微服 ...
- SpringCloud(六)Bus消息总线
Bus 消息总线 概述 分布式自动刷新配置功能 Spring Cloud Bus 配合 Spring Cloud Config使用可以实现配置的动态刷新 Bus支持两种消息代理:RabbitMQ和Ka ...
- Spring Cloud(十一)高可用的分布式配置中心 Spring Cloud Bus 消息总线集成(RabbitMQ)
详见:https://www.w3cschool.cn/spring_cloud/spring_cloud-jl8a2ixp.html 上一篇文章,留了一个悬念,Config Client 实现配置的 ...
- Spring Cloud 系列之 Bus 消息总线
什么是消息总线 消息代理中间件构建一个共用的消息主题让所有微服务实例订阅,当该消息主题产生消息时会被所有微服务实例监听和消费. 消息代理又是什么?消息代理是一个消息验证.传输.路由的架构模式,主要用来 ...
- spring cloud bus 消息总线 动态刷新配置文件 【actuator 与 RabbitMQ配合完成】
1.前言 单机刷新配置文件,使用actuator就足够了 ,但是 分布式微服务 不可能是单机 ,将会有很多很多的工程 ,无法手动一个一个的发送刷新请求, 因此引入了消息中间件 ,常用的 消息中间件 是 ...
- SpringCloud系列——Bus 消息总线
前言 SpringCloud Bus使用轻量级消息代理将分布式系统的节点连接起来.然后可以使用此代理广播状态更改(例如配置更改)或其他管理指令.本文结合RabbitMQ+GitHub的Webhook实 ...
- SpringCloud Bus消息总线
在微服务架构中,通常会使用轻量级的消息代理来构建一个共用的消息主题来连接各个微服务实例,它广播的消息会被所有在注册中心的微服务实例监听和消费,也称消息总线. SpringCloud中也有对应的解决方案 ...
随机推荐
- os x下如何挂载iso镜像
在linux下可以使用 mount -o loop 在os x下mount好想没有loop选项,不过可以用系统自带的命令 hdiutil mount xxx.iso 即可,弹出可以用 hdiutil ...
- 剑指offer面试题48: 最长不含重复字符的子字符串
Given a string, find the length of the longest substring without repeating characters.(请从子字符串中找出一个最长 ...
- C#中使用双缓冲来避免绘制图像过程中闪烁
自己所做项目中,在显示医学图像的界面中,当鼠标拖动图像时,不断刷新从后台获取新的图像,而整个过程就很诡异,一直闪个不停. 找到的一个可行方法是:在用户控件的构造函数中加入以下代码: SetStyle( ...
- [坑况]——windows升级node最新版本报错【npm install -g n】
我本来是下载一个vue-cli的,然后技术日新月异,告知我要先把我的node升级到8以上(目前是v6.1.13) 升级就升级,升级就报错 尝试第一种方法,网上最多的一种方法,估计也是成功最多的一种吧( ...
- WSGI及gunicorn指北(二)
pyg0已经大概了解了wsgi.现在他决定深入探索他们实际在生产环境里用到的web 服务器 -gunicorn. 先来看看官网的介绍:Gunicorn 是一个运行在Unix上的python WSGI ...
- springboot + mybatis 前后端分离项目的搭建 适合在学习中的大学生
人生如戏,戏子多半掉泪! 我是一名大四学生,刚进入一家软件件公司实习,虽说在大学中做过好多个实训项目,都是自己完成,没有组员的配合.但是在这一个月的实习中,我从以前别人教走到了现在的自学,成长很多. ...
- MySql 时间操作(今天,昨天,7天,30天,本月,上月)
1 . 查看当天日期 select current_date(); 2. 查看当天时间 select current_time(); 3.查看当天时间日期 select current_timesta ...
- Linux常用资源(不断改进中)
Linux常用命令全集: http://linux.chinaitlab.com/special/linuxcom/Index.html ubuntu 12.04 配置指南: http://www. ...
- pg_dump命令帮助信息
仅为参考查阅方便,完全命令行帮助信息,无阅读价值. pg_dump dumps a database as a text file or to other formats. Usage: pg_du ...
- 畅通工程-HZNU寒假集训
畅通工程 某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇.省政府"畅通工程"的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只 ...