Apache Hive 基本理论与安装指南
一、Hive的基本理论
Hive是在HDFS之上的架构,Hive中含有其自身的组件,解释器、编译器、执行器、优化器。解释器用于对脚本进行解释,编译器是对高级语言代码进行编译,执行器是对java代码的执行,优化器是在执行过程中进行优化。这里的代码就是Hadoop中的MapReduce,这里的MapReduce通过Hive往HDFS上执行、分析、查询数据。
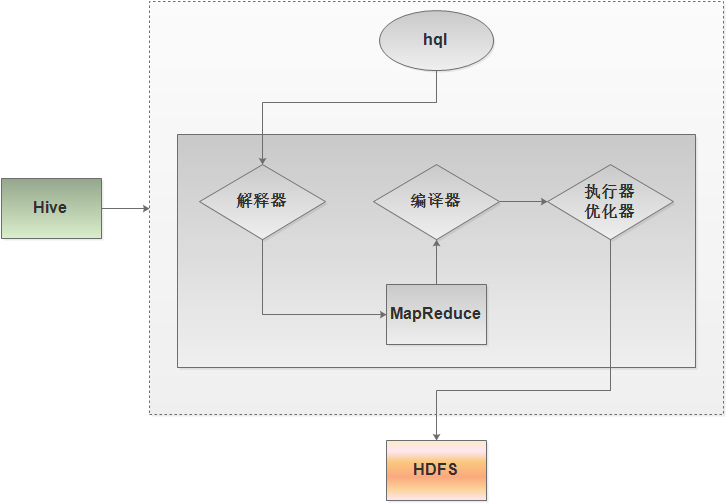
上图展示hql的执行过程,一个hql脚本首先到hive的解释器,转化为MapReduce(当然例如“select * from table_name;”这样的语句不用转化成MapReduce),解释器是用于解释脚本的,MapReduce是由脚本生成的;然后编译器再对MapReduce程序进行编译;再然后执行器对代码的执行以及优化器在执行过程优化。可见,Hive并没有更改数据的存储介质,数据仍然在HDFS上。Hive只是通过MapReduce对数据进行查询和分析,这时MapReduce不用进行解释、编译、优化,hive会帮助完成。这时写一个MapReduce程序就变成了写一个hql语句/脚本(或者说类似sql语句/脚本)。
Hive的本质不是一个数据库,更不是一个服务,它不需要端口,没有监听客户端。正因为hive不是一个服务,所以不需要考虑HA和分布式方面的问题,hive实际上就是一种工具,是一种把sql语句转化成MapReduce,然后再放到hadoop去执行MapReduce的一种工具。可以将hive理解为hadoop的一个客户端,因为是hive去连接hdfs,是hive去提交MapReduce程序到hadoop中的ResourceManager主节点。
hive也有其不足之处。虽然hive可以替代一部分MapReduce,但只能做统计查询,以及一些简单的统计分析,要想做数据挖掘仍需写MapReduce。因为hive的特点是基于hql脚本进行操作的,它非常接近关系型数据库的sql语句,所以它的数据结构一定是要有关系的那种才适合统计分析,这种统计分析有局限性。
二、Hive的安装
1. 环境的准备
从官方文档中可见,安装hive需要有jdk1.7(或更高版本)和hadoop2.x或hadoop1.x。但是官网上没有说需要一个关系型数据库,实际上hive内嵌了一个关系型数据库derby。但是内置的derby容量小,有些权限受限,不便于管理。
- Hadoop集群
hive必须要有MapReduce和HDFS,也就是要有hadoop集群。本文不对Apache Hadoop集群的部署作介绍,这部分内容作者已整理好并将在日后给出。
- 关系型数据库MySQL
hive将hdfs上的数据映射成一种表或字段的结构,在hdfs上分析数据时,其实大部分时候都可以变成一种表结构形式的,或者可以映射(当做)成一张表,其实不是表,在hdfs上以文件的形式存储。所以就需要一个存储映射关系数据的库,在hive中使用关系型数据库来存储hdfs文件与表映射关系的数据,这种数据称为元数据。
文件的数据如何对应成一张表?需要先查看数据是按什么分隔符分开的。第一个分隔符的第一个域,代表表中的某个字段,同理第二个域、第三个域、第四个域……都分别代表了表的相应的字段,这是一个一一映射的关系。
关系型数据库的安装可以参考作者的另一篇博文《使用阿里云主机离线部署CDH步骤详解》中的安装MySQL部分。
本文选择node1安装MySQL。并为了能让node5能连接MySQL,需要先添加用户和权限;另外,还需要为hive的元数据存储创建一个数据库,可以任意命名。
进入到MySQL:
mysql>create database hive_metadata;
mysql>grant all on hive_metadata.* to root@'%' identified by '';
mysql>quit;
- Hive机器上要有Hadoop的jar包和配置文件
准备安装hive的这台机器必须要有hdfs和ResourceManager的jar包,同时需要hadoop集群的配置文件。因为在服务器上执行MapReduce时,都需要hadoop的配置文件,而且配置文件要放在classpath路径下。hive要连hdfs也一样,因为hdfs是高可用的,不能指定主节点具体是哪台机器,因为主节点是可以切换的。所以必须要通过配置文件来配置Zookeeper,配置服务名称nameservice等。总之,安装hive的机器上需要有,hadoop的jar包和配置文件(即要有解压之后的hadoop,配置文件可以从Hadoop集群中拷贝),而这台机器的Hadoop是否运行起来无关紧要。
2. hive的安装
本文的Hadoop集群是node1、node2、node3、node4,准备安装hive的机器是node5。
- hive的下载
从Index of /apache/hive下载hive,本文使用的是1.2版本。
- 启动Hadoop集群
第一,关闭防火墙。
$ service iptables stop
第二,启动Zookeeper。
$ zkServer.sh start
第三,启动hadoop集群。
$ start-all.sh
第四,单独启动RM。
在两个ResourceManager节点启动RM
$ yarn-daemon.sh start resourcemanager
- 上传、解压、软链接
第一,上传。先将下载好的hive包上传到Linux中。
第二,解压及软链
$ tar -zxvf apache-hive-1.2.-bin.tar.gz
$ ln -sf /root/apache-hive-1.2.-bin /home/hive-1.2
第三,确保当前机器有hadoop集群的配置文件。查看是否有hadoop解压目录,如果有要检查里面的配置文件是否和hadoop集群中的一致。所以最好是直接从hadoop集群的机器中拷贝到当前机器。(当前机器处在hadoop集群中则无需这一步)。
- 在hive机器node5上配置hive的环境变量
$vi ~/.bash_profile
export HIVE_HOME=/home/hive-1.2
export PATH=$PATH:$HIEV_HOME/bin
source ~/.bash_profile
- 在hive机器node5上配置Hadoop的环境变量
hadoop集群时运行在node1-node4中,而hive在node5,hive是如何连接hadoop集群的?在hive机器上必须要有hadoop的环境变量,如果没有hive就找不到hadoop的配置文件,也找不到hadoop的jar包,这就不能连接hadoop集群了。
$vi ~/.bash_profile
export HADOOP_HOME=/home/hadoop-2.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
$ source ~/.bash_profile
到这一步,不需要修改任何配置文件,hive实际上已经可以运行了。在命令行中输入hive,就可以打开hive的命令行用户接口,在里面就可以敲sql语句了。(第一次打开比较耗时,因为它会检查hadoop、关系型数据库是否有问题)。由于目前还没有把hdfs上的文件映射到关系型数据库的表,所以这时的hive还没有表的概念。
- 设置关系型数据库
一般不使用hive内置的关系型数据库derby可以选择安装mysql,并修改配置文件,因为元数据很重要,元数据保存了映射关系。hive的元数据就相当于hdfs的元数据,如果hive的元数据丢失的话,它的表结构就会丢失,这时数据并不会丢失,但是需要重新建立表结构,会浪费很多时间。
修改$HIVE_HOME/conf/hive-default.xml.template配置文件。这个配置文件在默认情况下没有启用,需要先修改文件名。
$ cd $HIVE_HOME/conf/
$ cp hive-default.xml.template hive-site.xml
然后再修改hive-site.xml配置文件中的JDBC的四个属性:
第一,修改JDBC第一个属性ConnectionURL
可以发现其中JDBC的ConnectionURL如下:

其关系型数据库为derby,其缺陷有三:一是它的容量小,二是不能跨平台,三是不能由外部用户管理,所以要更换。随意在哪台机器上安装mysql,不一定要在hive机器上。
找到javax.jdo.option.ConnectionURL
将其value值改为:jdbc:mysql://node1:3306/hive_metadata
第二,修改JDBC的第二个属性ConnectionDriverName
找到属性名为javax.jdo.option.ConnectionDriverName的位置,将其属性值修改为:com.mysql.jdbc.Driver,这个驱动实际上就是一个jar包,要放到hive中。
安装driver驱动。上传mysql-connector-java-5.1.32.tar.gz到hive机器,解压,并进入解压目录,可见其中有一个jar包mysql-connector-java-5.1.32-bin.jar。注意jar包的版本要和MySQL一致,如果MySQL使用yum安装,默认安装的是5.1的。将jar包复制到$HIVE_HOME/lib/中:
$ cp -a mysql-connector-java-5.1.-bin.jar /home/hive-1.2/lib/
第三,修改JDBC的第三个属性ConnectionUserName
找到属性名为javax.jdo.option.ConnectionUserName的位置,修改其属性值为:root。这是刚才在mysql中建hive_metadata库时使用的用户名。
第四,修改JDBC的第四个属性ConnectionPassword
找到属性名为javax.jdo.option.ConnectionPassword的位置,修改其属性值为:12345678。这里的密码也是对应mysql数据库中建hive_metadata库时的密码。
第五,修改system:java.io.tmpdir路径。
如果不修改,启动时会报错如下 Exception in thread "main" java.lang.RuntimeException: java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D。原因是装载不了这个变量所对应的路径system:java.io.tmpdir。这个路径是hive的临时目录的路径。所以要修改环境变量,或者修改配置文件中的临时目录。
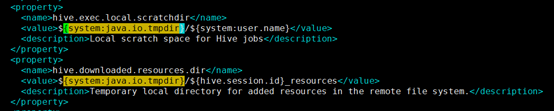
在hive-site.xml中使用/${system:java.io.tmpdir,可以找到四处。所以可以将名为hive.server2.logging.operation.log.location的属性值改为/tmp/hive/operation_logs;将名为hive.exec.scratchdir的属性值改为/tmp/hive;将名为hive.exec.local.scratchdir的属性值改为/tmp/hive;将名为hive.downloaded.resources.dir的属性值改为/tmp/hive/resources。保存退出。
- 启动hive
使用hive即可进入hive的命令行用户接口。
初次启动比较慢,是因为在mysql数据库中,hive会自动在这个刚创建的数据库hive_metadata中建表,可以进入node1的mysql中的hive_metadata数据库中查看。
mysql>use hive_metadata;
mysql>show tables;

Apache Hive 基本理论与安装指南的更多相关文章
- Apache Hive处理数据示例
继上一篇文章介绍如何使用Pig处理HDFS上的数据,本文将介绍使用Apache Hive进行数据查询和处理. Apache Hive简介 首先Hive是一款数据仓库软件 使用HiveQL来结构化和查询 ...
- Apache Hive 存储方式、压缩格式
简介: Apache hive 存储方式跟压缩格式! 1.Text File hive> create external table tab_textfile ( host string com ...
- 解决kylin sync table报错:MetaException(message:java.lang.ClassNotFoundException Class org.apache.hive.hcatalog.data.JsonSerDe not found
在kylin-gui中sync表default.customer_visit时报错: -- ::, ERROR [http-bio--exec-] controller.BasicController ...
- Spring boot with Apache Hive
5.29.1. Maven <dependency> <groupId>org.springframework.boot</groupId> <artif ...
- Apache Hive 安装文档
简介: Apache hive 是基于 Hadoop 的一个开源的数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,将 SQL 语句转换为 MapReduce 任务 ...
- Apache Hive (四)Hive的连接3种连接方式
转自:https://www.cnblogs.com/qingyunzong/p/8715925.html 一.CLI连接 进入到 bin 目录下,直接输入命令: [hadoop@hadoop3 ~] ...
- Hive 0.12.0安装指南
目录 目录 1 1. 前言 1 2. 约定 1 3. 服务端口 2 4. 安装MySQL 2 4.1. 安装MySQL 2 4.2. 创建Hive元数据库 2 5. 安装步骤 3 5.1. 下载Hiv ...
- Apache Hive 建表操作的简单描述
客户端连接hive [root@bigdata-02 bin]# ./beeline Beeline version by Apache Hive beeline: Connecting : Ente ...
- Apache Hive 简介及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. 主要用途:用来 ...
随机推荐
- Java多线程基础(二)
信号量Semaphore,类似于锁的功能,用于多线程中对一组资源的控制. acquire方法用于尝试获取一个资源,未获取前将一直等待.release用于释放一个资源,release的前提是已经获得了一 ...
- BZOJ 1593: [Usaco2008 Feb]Hotel 旅馆 [线段树]
传送门 题意: 操作1:找长为$len$的空区间并填满,没有输出$0$ 操作2:将$[l,r]$之间的区间置空 我真是太弱了这种线段树还写了一个半小时,中间为了查错手动模拟了$30min$线段树操作, ...
- 有关static静态方法知识的收集
1.何时使用静态方法: 如果某些操作不依赖具体实例,那它就是静态的,反之如果某些操作是依赖具体实例的(例如访问一个特定会员的名称),那它就应该是实例化的. 2.静态方法和实例方法的区别主要体现在两个方 ...
- WPF项目学习.一
WPF项目搭建 版权声明:本文为博主初学经验,未经博主允许不得转载. 一.前言 记录在学习与制作WPF过程中遇到的解决方案. 使用MVVM的优点是 数据和视图分离,双向绑定,低耦合,可重用行,相对独立 ...
- 【Oracle】虚拟表Dual
Dual是个虚拟表,用来构成SELECT语句的语法规则,Oracle保证Dual里面永远只有一条记录.可以用它来做很多事情,例如,查看当前用户:用来调用系统函数:得到序列的下一个值或者当前值:可以用作 ...
- Android 进程间通信
什么鬼!单例居然失效了,一个地方设置值,另个地方居然取不到,这怎么可能?没道理啊!排查半天,发现这两就不在一个进程里,才恍然大悟-- 什么是进程 按照操作系统中的描述:进程一般指一个执行单元,在 PC ...
- memcached 的实践操作
memcached安装和使用 yum install -y libevent memcached libmemcached 启动命令: /etc/init.d/memcached st ...
- OpenCMS模板的导出和OpenCMS网站的导出
1.OpenCMS模板的导出 (1)切换到Administration视图,单击Module Management,如图所示: (2)导出位置:tomcat根目录\webapps\opencms\ ...
- MySQL主从复制_复制过滤
关于主从过滤,建议只在从服务器做设定,在Master 端为保证二进制日志的完整, 不建议使用二进制日志过滤. Master 可用参数: binlog-do-db= #定义白名单,仅将制定数据库的相关操 ...
- 两种简单的方法Docker构建LANMP
在初步入门学习Docker的过程中一步步了解了Docker容器在团队开发中所起到的作用,一边学习一边操作基本命令,当然到现在还处于一个擦边的入门阶段. 尝试一下用Docker构建一个集成开发环境. S ...