学机器学习,不会数据处理怎么行?—— 一、NumPy详解
最近学习强化学习和机器学习,意识到数据分析的重要性,就开始补Python的几个科学计算库,并总结到博客中。本篇博客中用到的代码在这里下载。
什么是Numpy?
NumPy是Python数值计算最重要的基础包,支持高级大量的维度数组与矩阵运算,大多数提供科学计算的包都是使用Numpy的数组作为构建基础。Numpy内部解除了Python的PIL(全局解释器锁),运算效率极好,是大量机器学习框架的基础库!
其部分功能如下:
- ndarray,一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。
- 用于对整组数据进行快速运算的标准数学函数(无需编写循环)。
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
- 线性代数、随机数生成以及傅里叶变换功能
- 用于集成由C、C++、Fortran等语言编写的代码的工具
需要一提的是,NumPy本身没有提供那么多高级的数据分析功能,但理解NumPy数组,以及面向数组的计算将有助于更加高效地使用诸如pandas之类的工具。当然,如果只是想用pandas简单处理下数据,可以跳过NumPy的学习,直接学习pandas。
对于大部分数据分析应用而言,需要关注的功能主要集中在:
- 用于数据整理和清理、子集构造和过滤、转换等快速的矢量化数组运算。
- 常用的数组算法,如排序、唯一化、集合运算等。
- 高效地描述统计和数据聚合/摘要运算。
- 用于异构数据集的合并/连接运算的数据对齐和关系型数据运算。
- 将条件逻辑表述为数组表达式(而不是带有if-elif-else分支的循环)。
- 数据的分组运算(聚合、转换、函数应用等)。
为什么要使用NumPy?
NumPy数组在数值运算方面的效率优于Python提供的list容器。使用NumPy可以在代码中省去很多循环语句,因此其代码比等价的Python代码更为简洁。
NumPy数组一般是同质的(但有一种特殊的数组类型例外,它是异质的),即数组中的所有元素类型必须是一致的。这样有一个好处:如果我们知道数组中的元素均为同一类型,该数组所需的存储空间就很容易确定下来。
NumPy是在一个连续的内存块中储存数据,独立于其他Python内置对象,比起Python的内置序列,Numpy数组使用的内存更少。
Numpy可以在整个数组上执行复杂的计算,而不需要for循环。
执行下面代码进行验证
1 import numpy as np
2 my_arr = np.arange(1000000)
3 my_list = list(range(1000000))
4 %time for _ in range(10): my_arr2 = my_arr * 2
5 %time for _ in range(10): my_list2 = [x * 2 for x in my_list]
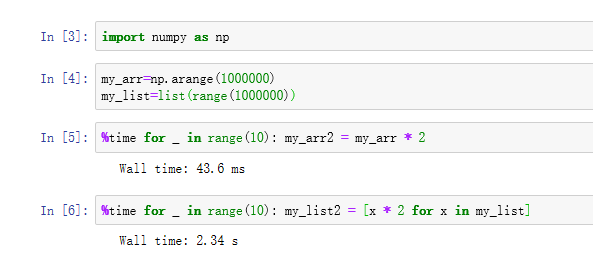
很明显,基于NumPy的算法要比纯Python快10到100倍(甚至更快),并且使用的内存更少。
Numpy的ndarray:一种多维数组对象
1.什么是ndarry
NumPy最重要的一个特点就是其N维数组对象(即ndarray),该对象是一个快速而灵活的大数据集容器。你可以利用这种数组对整块数据执行一些数学运算,其语法跟标量元素之间的运算一样。
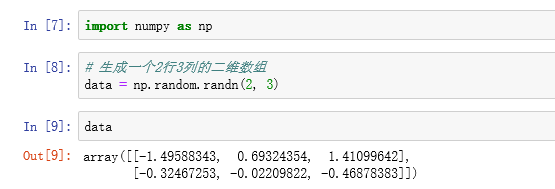
进行数学运算:
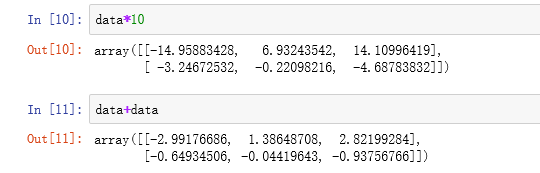
这里可以很清晰的看出NumPy数组对整组数组的计算操作的简便之处。
注:一般在import时都是使用 import numpy as np。当然,也可以使用 for numpy import * ,但不建议这么做,因为numpy的命名空间很大,包含很多函数,其中一些的名字与Python的内置函数重名(如min和max)。
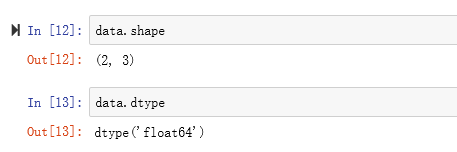
ndarray是一个通用的同构数据多维容器,也就是说,其中的所有元素必须是相同类型的。每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象):
2.创建ndarray
创建数组最简单的办法就是使用array函数。它接受一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的Numpy数组。
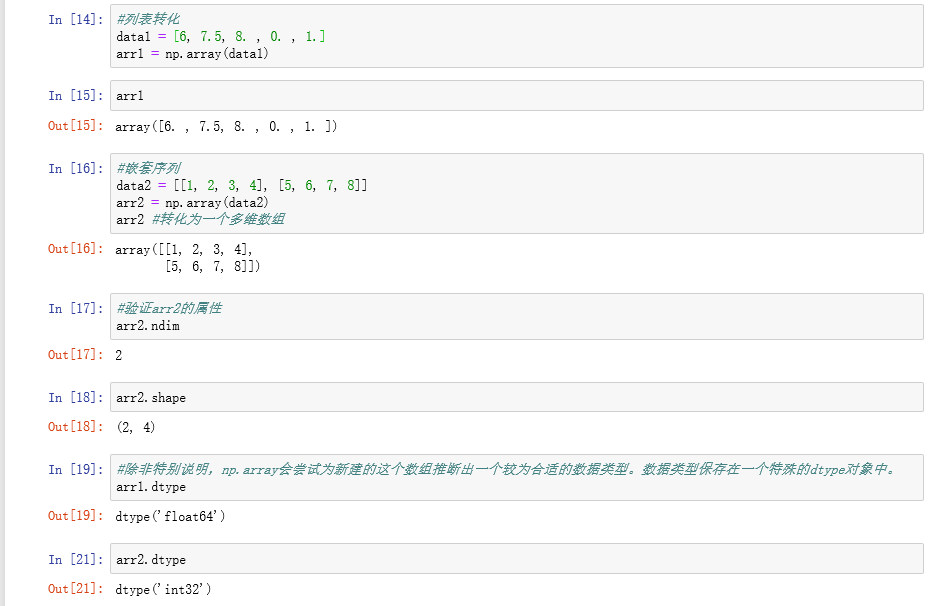
除np.array之外,还有一些函数也可以新建数组。比如,zeros和ones分别可以创建指定长度或形状的全0或全1数组。empty可以创建一个没有任何具体值的数组。要用这些方法创建多维数组,只需传入一个表示形状的元组即可。
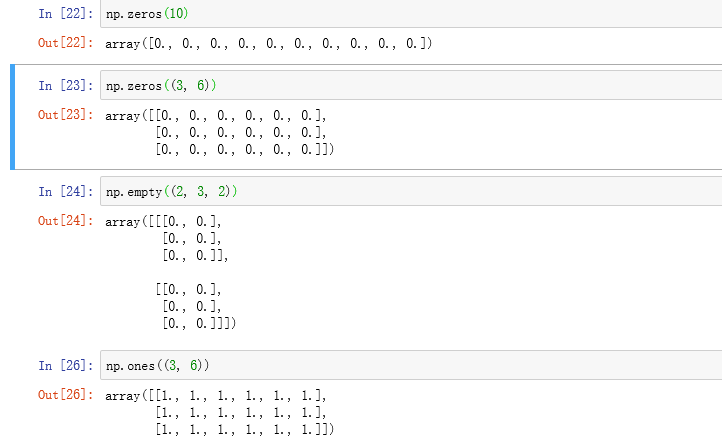
注:认为np.empty会返回全0数组的想法是不安全的。很多情况下(如前所示),它返回的都是一些未初始化的垃圾值。
arrange是Python内置函数的数组版:


3.ndarray的数据类型
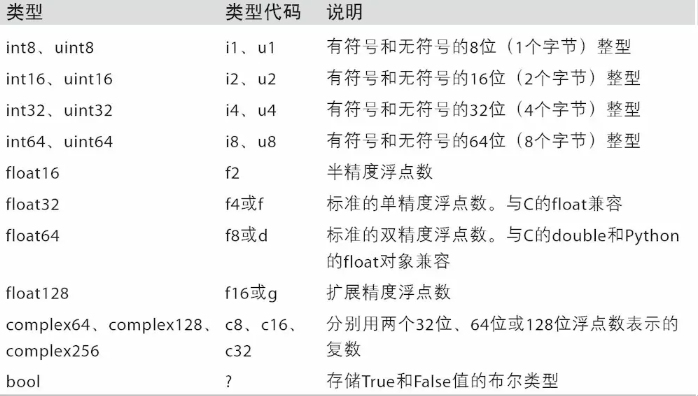
dtype(数据类型)是一个特殊的对象,它含有ndarray将一块内存解释为特定数据类型所需的信息。是NumPy灵活交互其它系统的源泉之一。多数情况下,它们直接映射到相应的机器表示,这使得“读写磁盘上的二进制数据流”以及“集成低级语言代码(如C、Fortran)”等工作变得更加简单。数值型dtype的命名方式相同:一个类型名(如float或int),后面跟一个用于表示各元素位长的数字。标准的双精度浮点值(即Python中的float对象)需要占用8字节(即64位)。因此,该类型在NumPy中就记作float64。下表列出了NumPy所支持的全部数据类型。


NumPy计算
这里将介绍Numpy的一些基本计算
1.条件运算


2.统计运算
求最大值

求最小值

平均值

方差

3.线性代数
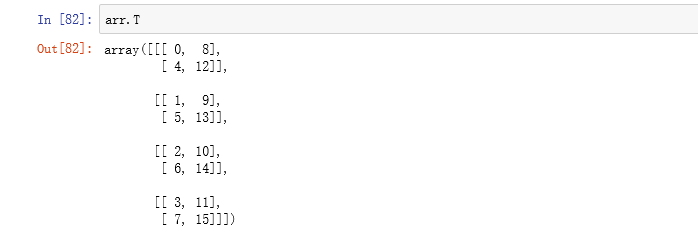
转置是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)。数组不仅有transpose方法,还有一个特殊的T属性
在进行矩阵计算时,经常需要用到该操作,比如利用np.dot计算矩阵内积

对于高维数组,我们可以使用transpose进行转置操作(有点难懂)

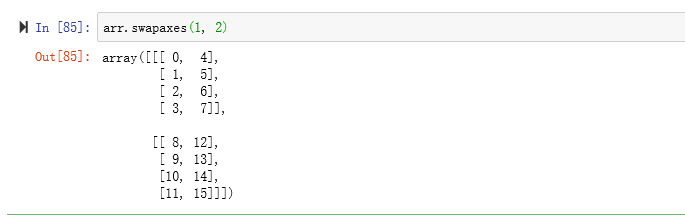
在这里,如果我们使用arr.shape(),则会返回(2,2,4),第一个2表示两组,第二个则表示每组都有两行,4则表示4列。而这三个数字由一个元组(0,1,2)进行索引,所以使用arr.transpose((1, 0, 2))时,则表示将第一位数与第二位数交换位置。最终会得到图中所示结果。
当然,我们也可以使用.T进行操作,不过.T进行的只是轴对换而已。
ndarray还有一个swapaxes方法,它需要接受一对轴编号
矩阵拼接
- 水平拼接
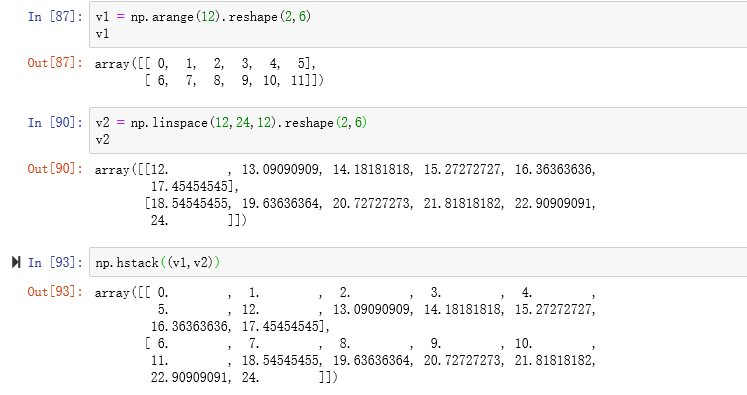
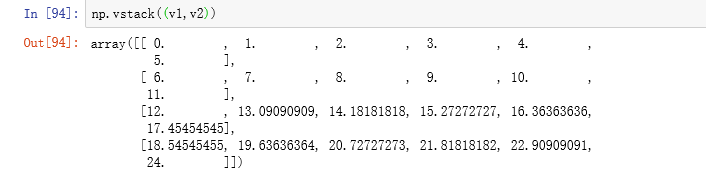
- 垂直拼接

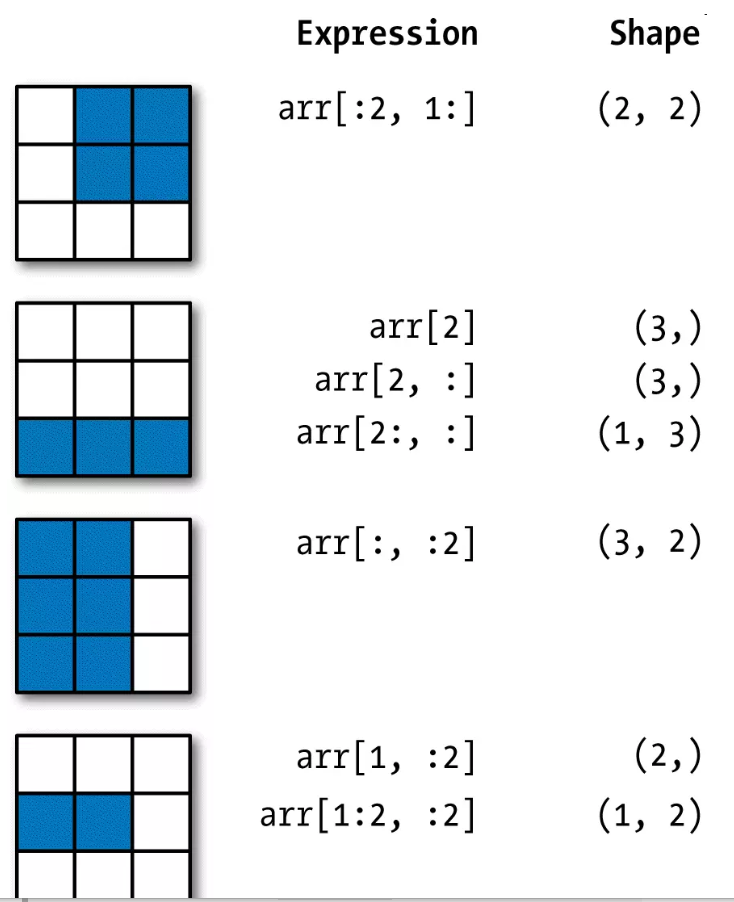
基本索引和切片
1.一维数组
NumPy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式有很多。一维数组很简单。从表面上看,它们跟Python列表的功能差不多

如上所示,当你将一个标量值赋值给一个切片时(如arr[5:8]=12),该值会自动传播到整个选区。跟列表最重要的区别在于,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上。
先创建一个arr的切片

修改其中的值,会发现数组arr中的值也会改变

切片[ : ]会给数组中所有的值赋值

2.高维数组
对于高维度数组,能做的事情更多。在一个二维数组中,各索引位置上的元素不再是标量而是一维数组

索引方式

在多维数组中,如果省略了后面的索引,则返回对象会是一个维度低一点的ndarray(它含有高一级维度上的所有数据),且标量值和数组都可用于赋值。

切片索引
ndarray的切片语法跟Python列表这样的一维对象差不多。对于之前的二维数组arr2d,其切片方式稍显不同
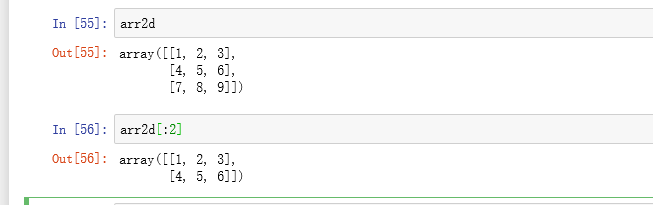
可以看出,它是沿着第0轴(即第一个轴)切片的。也就是说,切片是沿着一个轴向选取元素的。表达式arr2d[:2]可以被认为是“选取arr2d的前两行”。
当然,也可以一次传入多个切片,像传入多个索引那样

像这样进行切片时,只能得到相同维数的数组视图。通过将整数索引和切片混合,可以得到低维度的切片。
布尔型索引
来看这样一个例子,假设我们有一个用于存储数据的数组以及一个存储姓名的数组(含有重复项)。在这里,我将使用numpy.random中的randn函数(上面表格中漏了这个)生成一些正态分布的随机数据:
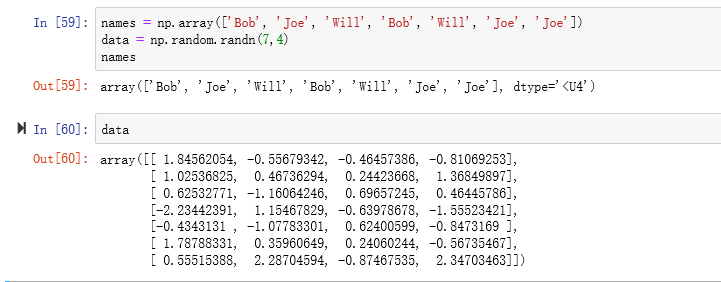
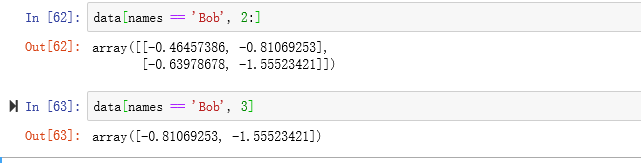
假设每个名字都对应data数组中的一行,而我们想要选出对应于名字"Bob"的所有行。跟算术运算一样,数组的比较运算(如==)也是矢量化的。因此,对names和字符串"Bob"的比较运算将会产生一个布尔型数组,这个布尔型数组课用于数组索引

注:布尔型数组的长度必须跟被索引的轴长度一致,如果布尔型数组的长度不对,布尔型选择就会出错。
此外,我们还可以将布尔型数组跟切片、整数(或整数序列)混合使用
如果我们要选取多个名字,则组合应用多个布尔条件,使用 &、| 之类的布尔算术运算符即可

注:通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此。
花式索引
花式索引(Fancy indexing)是一个NumPy术语,它指的是利用整数数组进行索引。假设我们有一个8×4数组
array([[ 0., 0., 0., 0.],
[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
[ 3., 3., 3., 3.],
[ 4., 4., 4., 4.],
[ 5., 5., 5., 5.],
[ 6., 6., 6., 6.],
[ 7., 7., 7., 7.]])
为了以特定顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray即可

使用负数索引将会从末尾开始选取行

一次传入多个索引数组会返回一个一维数组,其中的元素对应各个索引元组
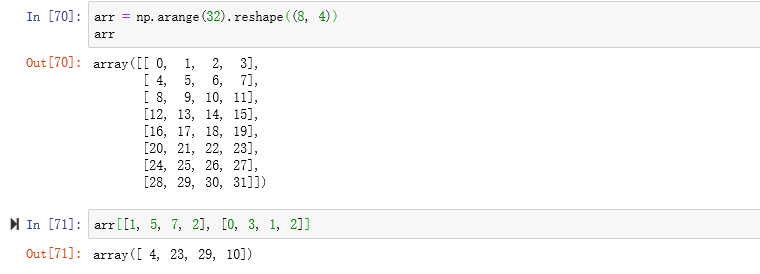
注:花式索引跟切片不一样,它总是将数据复制到新数组中。
随机数
1.伪随机数生成
NumPy可生成随机数,这些随机数是通过算法基于随机数生成器种子,在确定性条件下生成的,是伪随机数。我们可以使用normal来得到标准正态分布的样本数组,并且,在需要产生大量随机数时,NumPy的随机数生成速度比Python内置的random快了不止一个数量级

同时,我们可以用NumPy的np.random.seed更改随机数生成种子
np.random.seed(1234)
numpy.random的数据生成函数使用了全局的随机种子。要避免全局状态,我们可以使用numpy.random.RandomState,创建一个与其它隔离的随机数生成器
rng = np.random.RandomState(1234)
rng.randn(10) Out:
array([ 0.4714, -1.191 , 1.4327, -0.3127, -0.7206, 0.8872, 0.8596,
-0.6365, 0.0157, -2.2427])
下图给出了numpy.random中的部分函数


下面属于补充了
2.实例:随机漫步
我们可以通过模拟随机漫步来说明如何运用数组运算。先来看一个简单的随机漫步的例子:从0开始,步长1和-1出现的概率相等。

这提示就是随机漫步中各步的累计和,可以用一个数组运算来实现。因此,我用np.random模块一次性随机产生1000个“掷硬币”结果(即两个数中任选一个),将其分别设为1或-1,然后计算累计和
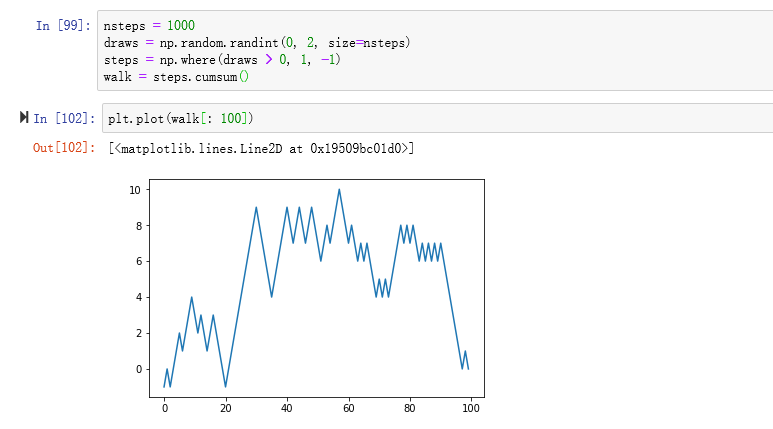
有了这些数据之后,我们就可以沿着漫步路径做一些统计工作了,比如求取最大值和最小值等
walk.min() walk.max()
再看一个复杂点的统计任务——首次穿越时间,即随机漫步过程中第一次到达某个特定值的时间。假设我们想要知道本次随机漫步需要多久才能距离初始0点至少10步远(任一方向均可)。np.abs(walk)>=10可以得到一个布尔型数组,它表示的是距离是否达到或超过10,而我们想要知道的是第一个10或-10的索引。可以用argmax来解决这个问题,它返回的是该布尔型数组第一个最大值的索引(True就是最大值):
In [103]:
(np.abs(walk) >= 10).argmax() Out[103]:
57
一次模拟多个随机漫步
如果你希望模拟多个随机漫步过程(比如5000个),只需对上面的代码做一点点修改即可生成所有的随机漫步过程。只要给numpy.random的函数传入一个二元元组就可以产生一个二维数组,然后我们就可以一次性计算5000个随机漫步过程的累计和了:
In [105]:
nwalks = 5000
nsteps = 1000
draws = np.random.randint(0, 2, size=(nwalks, nsteps))
steps = np.where(draws > 0, 1 , -1)
walks = steps.cumsum(1)
walks Out[105]:
array([[-1, 0, -1, ..., 12, 11, 10],
[ 1, 2, 3, ..., -2, -1, 0],
[-1, 0, 1, ..., 34, 35, 36],
...,
[ 1, 0, -1, ..., 32, 33, 32],
[ 1, 0, 1, ..., 20, 21, 22],
[-1, 0, -1, ..., 18, 19, 18]], dtype=int32)
剩下的数据处理就由你们自行发挥了。
结尾
上面只介绍了NumPy的部分内容,剩下的如归一化操作,排序,文件输入输出(大部分人都用pandas加载文本或表格数据)等等都没写入,但都在代码中给出了示例。头一回博客写这么长(虽说图片居多),中间还几次页面错误没保存。。。如有错误,欢迎大家指正。
参考博客:
https://www.jianshu.com/p/a380222a3292
https://www.jianshu.com/p/83c8ef18a1e8
https://blog.csdn.net/qq351469076/article/details/78817378
参考书籍:
《利用Python进行数据分析·第2版》
学机器学习,不会数据处理怎么行?—— 一、NumPy详解的更多相关文章
- Redis进阶实践之十四 Redis-cli命令行工具使用详解第一部分
一.介绍 redis学了有一段时间了,以前都是看视频,看教程,很少看官方的东西.现在redis的东西要看的都差不多看完了.网上的东西也不多了.剩下来就看看官网的东西吧,一遍翻译,一遍测试. ...
- Redis进阶实践之十四 Redis-cli命令行工具使用详解
转载来源:http://www.cnblogs.com/PatrickLiu/p/8508975.html 一.介绍 redis学了有一段时间了,以前都是看视频,看教程,很少看官方的东西.现在redi ...
- 【和我一起学python吧】Python安装、配置图文详解
Python安装.配置图文详解 目录: 一. Python简介 二. 安装python 1. 在windows下安装 2. 在Linux下安装 三. 在windows下配置python集成开发环境( ...
- Redis进阶实践之十五 Redis-cli命令行工具使用详解第二部分(结束)
一.介绍 今天继续redis-cli使用的介绍,上一篇文章写了一部分,写到第9个小节,今天就来完成第二部分.话不多说,开始我们今天的讲解.如果要想看第一篇文章,地址如下:http: ...
- 第九章 kubectl命令行工具使用详解
1.管理k8s核心资源的三种基础方法 陈述式管理方法:主要依赖命令行CLI工具进行管理 声明式管理方法:主要依赖统一资源配置清单(manifest)进行管理 GUI式管理方法:主要依赖图形化操作界面( ...
- 学数据库还不会Select,SQL Select详解,单表查询完全解析?
查询操作是SQL语言中很重要的操作,我们今天就来详细的学习一下. 一.数据查询的语句格式 SELECT [ALL|DISTINCT] <目标列表达式>[,<目标列表达式> .. ...
- PyQt(Python+Qt)学习随笔:QLineEdit行编辑器功能详解
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 一.概述 QLineEdit部件是一个单行文本编辑器,支持撤消和重做. ...
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理
摘要:这篇文章将详细讲解自然语言处理过程,基于机器学习和TFIDF的情感分类算法,并进行了各种分类算法(SVM.RF.LR.Boosting)对比 本文分享自华为云社区<[Python人工智能] ...
- 跟我一起学WCF(8)——WCF中Session、实例管理详解
一.引言 由前面几篇博文我们知道,WCF是微软基于SOA建立的一套在分布式环境中各个相对独立的应用进行交流(Communication)的框架,它实现了最新的基于WS-*规范.按照SOA的原则,相对独 ...
随机推荐
- jQuery——Js与jQuery的相互转换
$()与jQuery() jQuery中$函数,根据传入参数的不同,进行不同的调用,实现不同的功能.返回的是jQuery对象 jQuery这个js库,除了$之外,还提供了另外一个函数:jQuery j ...
- CentOS 6.8 部署django项目一
CentOS 6.8 部署django项目二 1.安装python3.5(默认是2.6) 参考:http://blog.csdn.net/shaobingj126/article/details/50 ...
- Windows域帐户
域的直观优点: 1.域帐户可以在任意一台已经加入域的电脑上登录. 2.将域用户组加入到SQL Server登录里,域用户组内所有人员便都可以使用域用户登录数据库,继承相关权限. 3.域用户登录Team ...
- MR运动静止用户区分
1.客户端打开菜单[MR]-[MR室内室外判定设置] 设置主小区是室外站且主小区信号比较强时RSRP门限 2.设置"上报数据用户临小区切换次数门限设置"值为15 mysql中t_m ...
- ARMV8 datasheet学习笔记1:预备知识
1. 前言 ARMv8的架构继承以往ARMv7与之前处理器技术的基础; 除了支持现有的16/32bit的Thumb2指令外,也向前兼容现有的A32(ARM 32bit)指令集. 基于64bit的AAr ...
- class_create(),device_create自动创建设备文件结点【转】
本文参考来自CSDN博客,转载请标明出处:http://blog.csdn.net/zhenwenxian/archive/2010/03/28/5424434.aspx 本文转自:http://ww ...
- springboot系列六、springboot配置错误页面及全局异常
一.spring1.x中处理方式 @Bean public EmbeddedServletContainerCustomizer containerCustomizer() { return new ...
- 转载:为什么选择Nginx(1.2)《深入理解Nginx》(陶辉)
原文:https://book.2cto.com/201304/19610.html 为什么选择Nginx?因为它具有以下特点: (1)更快 这表现在两个方面:一方面,在正常情况下,单次请求会得到更快 ...
- JDK1.5引入的concurrent包
并发是伴随着多核处理器的诞生而产生的,为了充分利用硬件资源,诞生了多线程技术.但是多线程又存在资源竞争的问题,引发了同步和互斥,并带来线程安全的问题.于是,从jdk1.5开始,引入了concurren ...
- centos7忘记登录密码修改
很多时候我们都会忘记Linux root 用户的口令,下面就教大家如果忘记root口令怎么办 第1步:开机后在内核上按“e”.截图如下 按e以后会进入内核启动页面,如下图 第2步:在linux16这行 ...