ha环境下重新格式化hdfs报错
datanode启动不成功,如下所示,我的136,137.138都是datanode,都启动不了。
查看datanode日志文件发现报错:
一个报错Incompatible clusterIDs in /home/hadoop/data/datanode,需要删除core-site.xml中配置的hadoop.tmp.dir临时目录下的东西。
第二个报错需要删除hdfs-site.xml中配置dfs.datanode.data.dir对应的目录下的东西。
然后重新格式化hdfs后,重启hdfs就可以了。
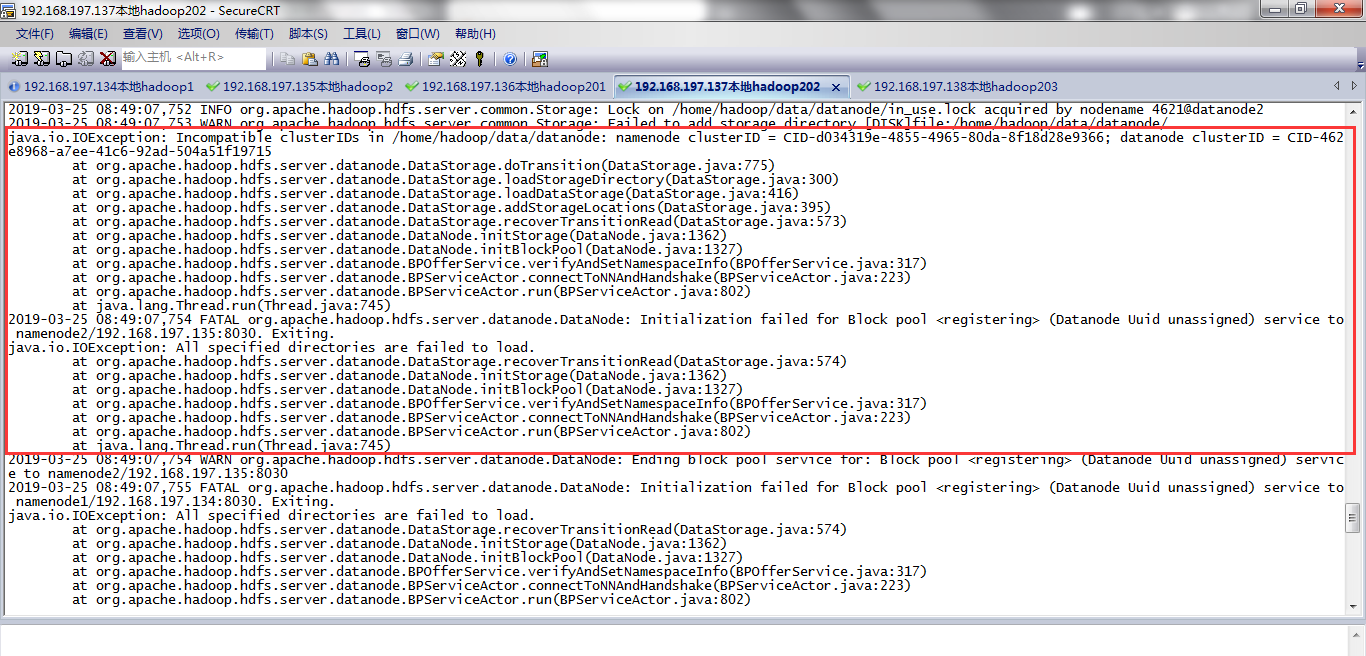
2019-03-25 08:49:07,753 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/hadoop/data/datanode/
java.io.IOException: Incompatible clusterIDs in /home/hadoop/data/datanode: namenode clusterID = CID-d034319e-4855-4965-80da-8f18d28e9366; datanode clusterID = CID-462e8968-a7ee-41c6-92ad-504a51f19715
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:775)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:300)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:416)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:573)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1362)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1327)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745)
2019-03-25 08:49:07,754 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to namenode2/192.168.197.135:8030. Exiting.
java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:574)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1362)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1327)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745)
ha环境下重新格式化hdfs报错的更多相关文章
- hadoop ha环境下的datanode启动报错java.lang.NumberFormatException: For input string: "10m"
hadoop ha环境启动start-dfs.sh的时候datanode启动不了,并且报错. [hadoop@datanode2 ~]$ cat /home/hadoop/hadoop-2.7.3/l ...
- Hadoop格式化HDFS报错java.net.UnknownHostException: localhost.localdomain: localhost.localdomain
异常描述: 在对HDFS格式化,执行hadoop namenode -format命令时,出现未知的主机名的问题,异常信息如下所示: [shirdrn@localhost bin]$ hadoop n ...
- window环境下npm install node-sass报错
最近准备想用vue-cli初始化一个项目,需要sass-loader编译: 发现window下npm install node-sass和sass-loader一直报错, window 命令行中提示我 ...
- thinkphp 5.0 lnmp环境下 无法访问,报错500(public目录)
两种方法: 1.修改fastcgi的配置文件 /usr/local/nginx/conf/fastcgi.conf fastcgi_param PHP_ADMIN_VALUE "open_b ...
- windows环境下安装scrapy框架报错问题--最快捷有效的解决方案
windows在执行如下命令,安装scrapy的过程中会报错: pip install scrapy 报错分析: windows环境下,会出现如下错误: 1.提示的错误是编译环境的问题,字面意思看需要 ...
- ubuntu1604环境下mariadb启动卡住报错和apparmor基本使用
问题描述:Ubuntu 1604 新环境下使用apt安装的mariadb10版本,结果第二天就起不来了,很是郁闷 启动时会卡住,当时就慌了,这什么情况啊,昨天好好的今天就起不来了,过了一会儿就有返回信 ...
- windows10环境下pip安装Scrapy报错
问题描述 当前环境win10,python_3.6.1,64位. 在windows下,在dos中运行pip install Scrapy报错: building 'twisted.test.raise ...
- Hadoop格式化HDFS报错java.net.UnknownHostException: centos64
异常描述 在对HDFS格式化,执行hadoop namenode -format命令时,出现未知的主机名的问题,异常信息如下所示: [shirdrn@localhost bin]$ hadoop na ...
- ubuntu环境下重启mysql服务报错“No directory, logging in with HOME=-”
前提:使用系统的环境 3.13.0-24-generic mysql的版本:5.6.33 错误描述: 首先用mysqld_safe启动报错如下: root@zabbix-forFunction:~# ...
随机推荐
- Python知识点整理,基础1 - 基本语法
- JavaEE开发的颠覆者 Spring Boot实战--笔记
1.Spring boot的三种启动模式 Spring 的问题 Spring boot的特点,没有特别的地方 1.Spring 基础 PS:关于spring配置 PS: 现在都已经使用 java配置, ...
- nginx配置基于域名的虚拟主机
其实基于域名和基于ip的虚拟主机配置是差不多的,在配置基于ip的虚拟主机上我们只需要修改几个地方就能变成基于域名的虚拟主机,一个是要修改域名,一个是host文件直接看代码 [root@localhos ...
- day 60 Bootstrip学习
图标地址 http://fontawesome.io/icons/ 图标用法地址 http://fontawesome.io/examples/ 实现代码 <!DOCTYPE html> ...
- Python的itertools模块
本章将介绍Python自建模块itertools,更多内容请参考:Python参考指南 python的自建模块itertools提供了非常有用的用于操作迭代对象的函数. 首先,我们看看itertool ...
- 晒一晒Jenkins那些常用插件
Jenkins插件大师 作为CI/CD的调度中心,Jenkins具有十八般武艺,目前已有1700多个插件,功能强大到似乎有点过分了.本文主要列出平时我们常用的插件. 以下这两个网站是Jenkins ...
- python-廖雪峰,map/reduce学习笔记
# _*_ coding:utf-8 _*_from functools import reduce def str2int(s): digits = {'0': 0, '1': 1, '2': 2, ...
- java考试感受
开学不久,我们进行了一次java程序考试.在此之前,老师要求我们在假期自学java并提前发了一个考试样卷,要求用数组编写一个学生信息管理系统并能够实现一系列的功能.由于我早早的便完成了这道题.因此对这 ...
- 关联本地文件夹到 GitLab 项目
关联本地文件夹到 GitLab 项目的 dev 分支: rm -rf .git git init git remote add origin git pull git checkout dev git ...
- mysql查询各个知识点
临时表 group by http://www.ywnds.com/?p=10174 https://blog.csdn.net/wuseyukui/article/details/72627667 ...