hadoop 伪分布式安装
0. 关闭防火墙
重启后失效
service iptables start ;#立即开启防火墙,但是重启后失效。
service iptables stop ;#立即关闭防火墙,但是重启后失效。
重启后生效
chkconfig iptables on ;#开启防火墙,重启后生效
chkconfig iptables off ;#关闭防火墙,重启后生效
1. 配置主机
注意安装hadoop的集群主机名不能有下划线!!不然会找不到主机!无法启动!
配置主机名
# vim /etc/sysconfig/network
例如:
NETWORKING=yes
HOSTNAME=hadoop01

# source /etc/sysconfig/network
2. 配置Hosts
# vim /etc/hosts
填入以下内容:
192.168.22.130 hadoop01

注意:一定是外网IP,ifconfig查看外网IP
其他主机和ip对应信息。。。
注意:如果是Centos7,那么需要再编辑/etc/hostname文件,将其中的内容改为指定的主机名

3. 配置免密码互通
生成自己的公钥和私钥,生成的公私钥将自动存放在/root/.ssh目录下。
[root@hadoop01 software]# ssh-keygen
把生成的公钥copy到远程机器上
[root@hadoop01 software]# ssh-copy-id [user]@[host]
例如:
[root@hadoop01 software]# ssh-copy-id root@hadoop01
此时在远程主机的/root/.ssh/authorized_keys文件中保存了公钥,在known_hosts中保存了已知主机信息,当
再次访问的时候就不需要输入密码了。
$ ssh [host]
通过此命令远程连接,检验是否可以不需密码连接

重启计算机 reboot
4. 安装JDK
5. 安装hadoop
通过fz将hadoop安装包上传到linux
解压安装包 tar -zxvf [hadoop安装包位置]
[root@hadoop01 hadoop-2.7.1]# cd ./etc/hadoop/
[root@hadoop01 hadoop]# vim hadoop-env.sh
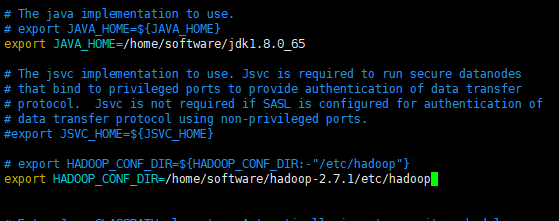
[root@hadoop01 hadoop]# source hadoop-env.sh
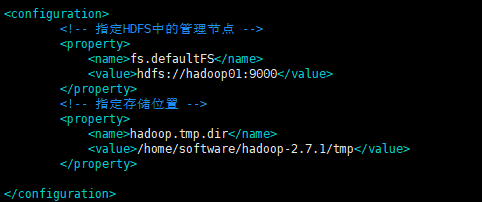
[root@hadoop01 hadoop]# vim core-site.xml
<!-- 指定HDFS中的管理节点 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 指定存储位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>
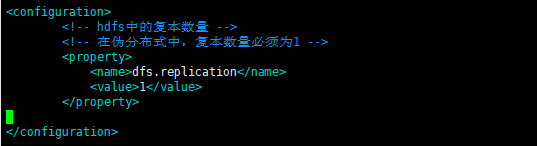
[root@hadoop01 hadoop]# vim hdfs-site.xml
<!-- hdfs中的复本数量 -->
<!-- 在伪分布式中,复本数量必须为1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
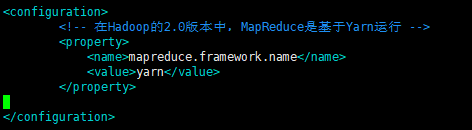
[root@hadoop01 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@hadoop01 hadoop]# vim mapred-site.xml
<!-- 在Hadoop的2.0版本中,MapReduce是基于Yarn运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
[root@hadoop01 hadoop]# vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

[root@hadoop01 hadoop]# vim slaves

[root@hadoop01 hadoop]# vim /etc/profile
export HADOOP_HOME=/home/software/hadoop-2.7.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@hadoop01 hadoop]# source /etc/profile
[root@hadoop01 hadoop]# hadoop namenode -format

[root@hadoop01 hadoop]# start-all.sh
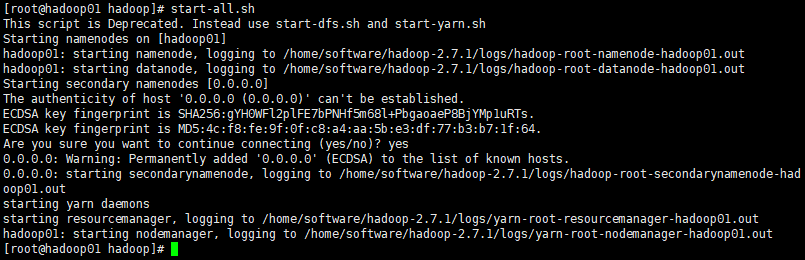
19. 如果启动成功,可以在浏览器中输入地址:50070访问hadoop的页面
v\:* {behavior:url(#default#VML);}
o\:* {behavior:url(#default#VML);}
w\:* {behavior:url(#default#VML);}
.shape {behavior:url(#default#VML);}
Normal
0
false
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;
mso-font-kerning:1.0pt;}
hadoop 伪分布式安装的更多相关文章
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- apache hadoop 伪分布式安装
1. 准备工作 1.1. 软件准备 1.安装VMWare 2.在VMWare上安装CentOS6.5 3.安装XShell5,用来远程登录系统 4.通过rpm -qa | grep ssh 检查cen ...
- Hadoop 伪分布式安装、运行测试例子
1. 配置linux系统环境 centos 6.4 下载地址:http://pan.baidu.com/s/1geoSWuv[VMWare专用CentOS.rar](安装打包好的VM压缩包) 并配置虚 ...
- 【Hadoop学习之二】Hadoop伪分布式安装
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 伪分布式就 ...
- 基于centos6.5 hadoop 伪分布式安装
步骤1:修改IP 地址和主机名: vi /etc/sysconfig/network-scripts/ifcfg-eth0 如果该文件打开为空白文件代表你计算机上的网卡文件不是这个名称“ifcfg-e ...
- Hadoop伪分布式安装步骤(hadoop0.20.2版本)
最近在学习hadoop,自己下了个视频教程,他的教学版本是hadoop0.20.2版本,现在的最新版本都到了3.0了,版本虽然有点老,但是还是学了一下,觉得有借鉴的价值. 不废话了,开始介绍: 先说一 ...
- [大数据] hadoop伪分布式安装
注意:节点主机的hostname不要带"_"等字符,否则会报错. 一.安装jdk rpm -i jdk-7u80-linux-x64.rpm 配置java环境变量: vi + /e ...
- hadoop伪分布式安装
hadoop的伪分布安装:一台实体机或虚拟机的安装. 环境:Windows7.VMWare.CentOS 1.1 设置ip地址 说明:在CentOS中的网络的类型: 仅主机模式:虚拟机在Windows ...
- macbook 下hadoop伪分布式安装
1 准备原材料 1.1 jdk 1.8.0_171(事先安装并配置环境变量HAVA_HOME,PATH) 1.2 Hadoop 2.8.3 2 免密登陆配置(否则安装过程需要不断输入密码) 2.1 ...
随机推荐
- innerHTML与innerText功能的强大
例: <div id="study"> <span style="color:red">学习</span>study < ...
- [Codeforces Round #492 (Div. 1) ][B. Suit and Tie]
http://codeforces.com/problemset/problem/995/B 题目大意:给一个长度为2*n的序列,分别有2个1,2,3,...n,相邻的位置可以进行交换,求使所有相同的 ...
- 【HDOJ1529】【差分约束+SPFA+二分】
http://acm.hdu.edu.cn/showproblem.php?pid=1529 Cashier Employment Time Limit: 2000/1000 MS (Java/Oth ...
- 《DSP using MATLAB》Problem 6.23
代码: %% ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ %% Output In ...
- python基础-函数基本特性和用法
函数: 初中数学函数定义:一般的,在一个变化过程中,如果有两个变量x和y,并且对于x的每一个确定的值,y都有唯一确定的值与其对应,那么我们就把x称为自变量,把y称为因变量,y是x的函数.自变量x的取值 ...
- Js 向表单中添加多个元素
@{ ViewBag.title = "地图导航"; } @model YT.XWAJ.Public.Application.MapNavigation.Dto.MapNaviga ...
- SQL Server 表分区备忘
1.创建的代码如下: )) AS RANGE LEFT FOR VALUES ( N', N', N',... ) CREATE PARTITION SCHEME [01_SubjectiveScor ...
- 系统限制和选项limit(一)
从shell中获取系统限制和选项 终端输入getconf value [pathname] [root@bogon code]# getconf ARG_MAX 2097152 [root@bogon ...
- 新建 django 项目
安装 django ,就不必多说,python 环境是 python 3.6,django 安装的命令为: pip3 install django==2.1.7 开始demo,名字为 guest dj ...
- 配置zabbix当内存剩余不足15%的时候触发报警
zabbix默认的剩余内存报警:Average Lack of available memory on server {HOST.NAME}{Template OS Linux:vm.memory.s ...