pd.concat/merge/join
pandas的拼接分为两种:
- 级联:pd.concat, pd.append
- 合并:pd.merge, pd.join
一.回顾numpy.concatenate
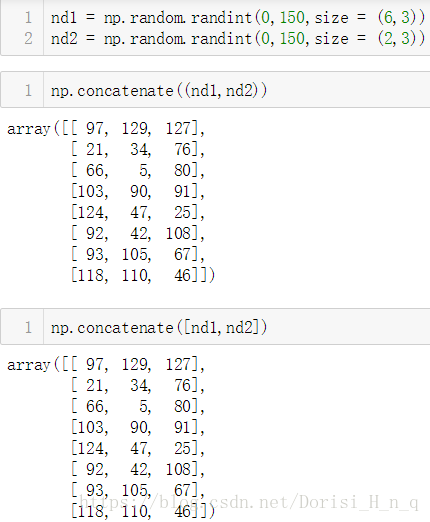
生成1个6*3的矩阵,一个2*3的矩阵,对其分别进行两个维度上的级联
nd1 = np.random.randint(0,150,size = (6,3))
nd2 = np.random.randint(0,150,size = (2,3))
np.concatenate((nd1,nd2))
np.concatenate([nd1,nd2])
二. concat
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
参数:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False)
参数说明:
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列 ,默认axis=0
join:连接的方式 inner,或者outer
1.相同字段的表首尾相接
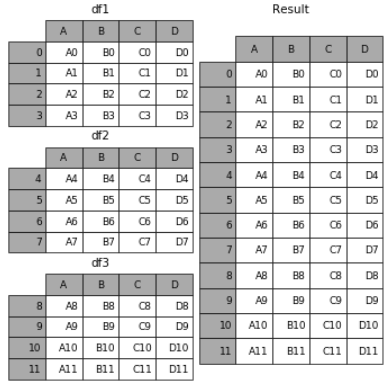
# 现将表构成list,然后在作为concat的输入
frames = [df1, df2, df3] result = pd.concat(frames)
要在相接的时候在加上一个层次的key来识别数据源自于哪张表,可以增加key参数
result = pd.concat(frames, keys=['x', 'y', 'z'])
效果如下:

2. 横向表拼接(行对齐)
有三种级联方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
- 连接指定轴:join_axes
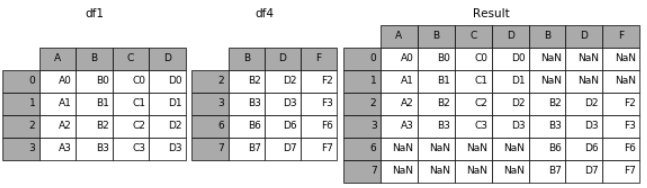
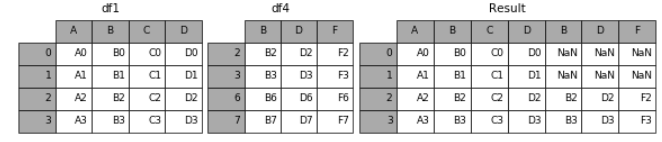
(1)axis
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
result = pd.concat([df1, df4], axis=1)
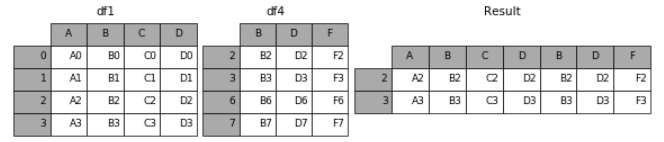
(2)join
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集。
result = pd.concat([df1, df4], axis=1, join='inner')
(3)join_axes
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
3. append
append是series和dataframe的方法,使用它就是默认沿着列进行凭借(axis = 0,列对齐)
result = df1.append(df2)

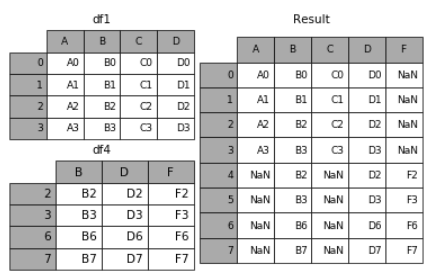
4. 无视index的concat
如果两个表的index都没有实际含义,使用ignore_index参数,置true,合并的两个表就是根据列字段对齐,然后合并。最后再重新整理一个新的index。
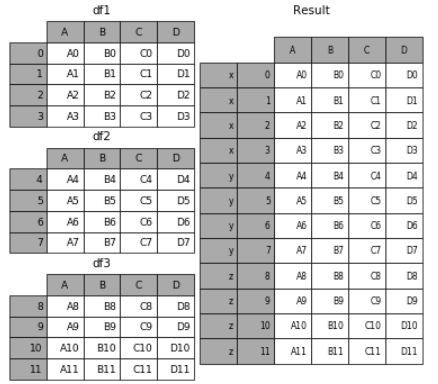
5. 合并的同时增加区分数据组的键
前面提到的keys参数可以用来给合并后的表增加key来区分不同的表数据来源
(1)可以直接用key参数实现
result = pd.concat(frames, keys=['x', 'y', 'z'])
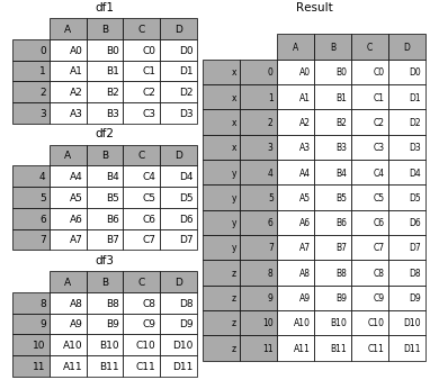
(2)传入字典来增加分组键
pieces = {'x': df1, 'y': df2, 'z': df3}
result = pd.concat(pieces)
6. 在dataframe中加入新的行
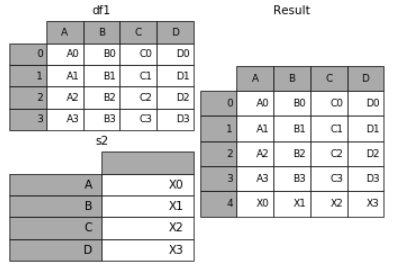
append方法可以将 series 和 字典的数据作为dataframe的新一行插入。
s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
result = df1.append(s2, ignore_index=True)
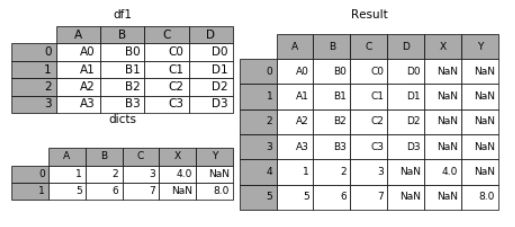
7. 表格列字段不同的表合并
如果遇到两张表的列字段本来就不一样,但又想将两个表合并,其中无效的值用nan来表示。那么可以使用ignore_index来实现。
dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4}, {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
result = df1.append(dicts, ignore_index=True)
三. merge()
merge的参数
- on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。
- left_on:左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
- right_on:右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
- left_index/ right_index: 如果是True的haunted以index作为对齐的key
- how:数据融合的方法。
- sort:根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现。
merge的默认合并方法:merge用于表内部基于 index-on-index 和 index-on-column(s) 的合并,但默认是基于index来合并。
1. 通过on指定数据合并对齐的列
pd.merge(left, right)# 默认merge会将重叠列的列名当做键,即how='inner',有多个重复列名则选取重复列名值都相同的行 # 指定“on”作为连接键,left和right两个DataFrame必须同时存在“on”列,连接键也可N对N(少用)
pd.merge(left, right, on="key")#默认how='inner',两个表取key的交集行,right的的列放在left列右边
pd.merge(left, right, on=["key1", "key2"])#两个表取key1,key2都相同的行,right的的列放在left列右边 pd.merge(left, right, left_on="key", right_on="key")#两个表取key列行相同的行,其他重复列名变为column_x,column_y,与on='key'相同 # suffixes:用于追加到重叠列名的末尾,默认为("_x", "_y")
pd.merge(left, right, on="key", suffixes=("_left", "_right")) # 指定连接方式:“inner”(默认),“left”,“right”,“outer”
pd.merge(left, right,on='key' how="outer")#产生以left和right的key值并集的行的dataframe pd.merge(left_frame, right_frame, on='key', how='left')#产生以left_frame的key所有值为行的dataframe,right_frame中的key没有该值的话那些列数据为NaN pd.merge(left_frame, right_frame, on='key', how='right')#同上相似 pd.merge(left, right, left_on="lkey", right_on="rkey")#左边表lkey和右边表rkey值相同的行,所有列都显示,重复的_x,_y
2. join方法
dataframe内置的join方法是一种快速合并的方法。它默认以index作为对齐的列。
(1)how参数
join中的how参数和merge中的how参数一样,用来指定表合并保留数据的规则。
(2)on参数
在实际应用中如果右表的索引值正是左表的某一列的值,这时可以通过将 右表的索引和左表的列对齐合并这样灵活的方式进行合并。
result = left.join(right, on='key')
(3)suffix后缀参数
如果和表合并的过程中遇到有一列两个表都同名,但是值不同,合并的时候又都想保留下来,就可以用suffixes给每个表的重复列名增加后缀。
result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
3. 组合多个dataframe
一次组合多个dataframe的时候可以传入元素为dataframe的列表或者tuple。一次join多个,一次解决多次烦恼~
result = left.join([right, right2])
merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。注意每一列元素的顺序不要求一致
df_id = DataFrame({'id':[1,2,3,4]},index = list('ABCD'))
df_id
df2 = DataFrame(np.random.randint(0,150,size=(4,3) ),index=list('ABCD'),columns=['语文','政治','历史'])
df2 = pd.concat([df2,df_id],axis = 1)
df2

(1)一对一合并
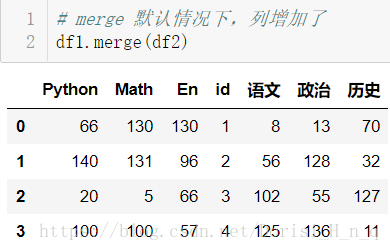
# merge 默认情况下,列增加了
df1.merge(df2)
(2)多对一合并
(3)多对多合并
4. key的规范化
- 使用on=显式指定哪一列为key,当有多个key相同时使用
# 指明on根据那一列进行融合,不指名,根据根据所有的共同的列名进行融合
# 不指明的时候,语文和id都是共同列
df2.merge(df3,on = 'id',suffixes=('_期中','_期末') )

# df2 左边
# df4 右边
df2.merge(df4,left_on='id',right_on='Id')

- 使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不相等时使用
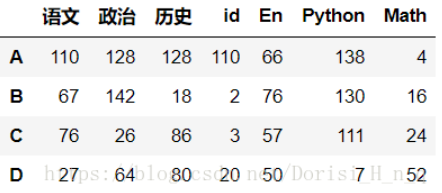
df2.merge(df5,left_on='id',right_index=True)
5. 内合并和外合并
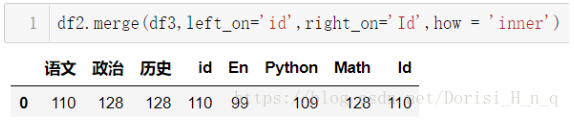
- 内合并:只保留两者都有的key(默认模式)
df2.merge(df3,left_on='id',right_on='Id',how = 'inner')
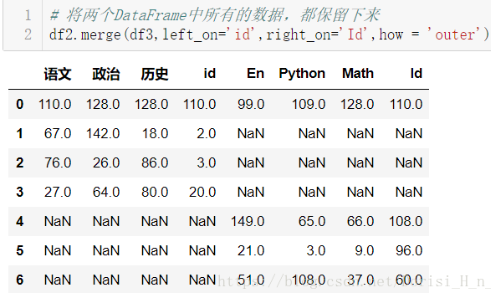
- 外合并 how='outer':补NaN
# 将两个DataFrame中所有的数据,都保留下来
df2.merge(df3,left_on='id',right_on='Id',how = 'outer')
- 左合并、右合并:how='left',how='right',
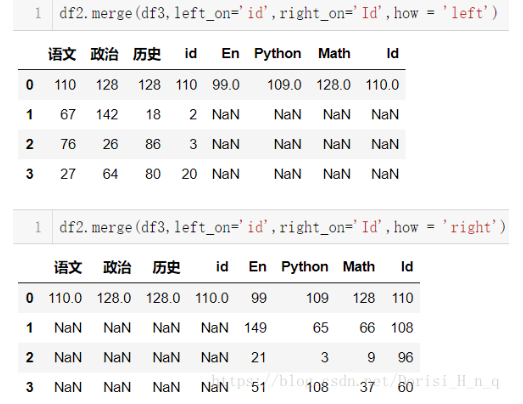
df2.merge(df3,left_on='id',right_on='Id',how = 'left')
df2.merge(df3,left_on='id',right_on='Id',how = 'right')
6. 列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名,可以使用suffixes=自己指定后缀
参考文献:
【2】pandas的拼接操作
pd.concat/merge/join的更多相关文章
- python pandas 合并数据函数merge join concat combine_first 区分
pandas对象中的数据可以通过一些内置的方法进行合并:pandas.merge,pandas.concat,实例方法join,combine_first,它们的使用对象和效果都是不同的,下面进行区分 ...
- Pandas -- Merge,join and concatenate
Merge, join, and concatenate pandas provides various facilities for easily combining together Series ...
- Python Pandas Merge, join and concatenate
Pandas提供了基于 series, DataFrame 和panel对象集合的连接/合并操作. Concatenating objects 先来看例子: from pandas import Se ...
- concat merge
# concat import numpy as np import pandas as pd from pandas import Series,DataFrame df1 = DataFrame( ...
- 9-Pandas之数据合并与轴向连接(pd.concat()的详解)
数据合并:由于数据可能是不同的格式,且来自不同的数据源,为了方便之后的处理与加工,需要将不同的数据转换成一个DataFrame. Numpy中的concatenate().vstack().hstac ...
- python数据拼接: pd.concat
1.concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=Non ...
- pandas常用操作详解——pd.concat()
concat函数基本介绍: 功能:基于同一轴将多个数据集合并 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=Fa ...
- 排序合并连接(sort merge join)的原理
排序合并连接(sort merge join)的原理 排序合并连接(sort merge join)的原理 排序合并连接(sort merge join) 访问次数:两张表都只会访 ...
- Sort merge join、Nested loops、Hash join(三种连接类型)
目前为止,典型的连接类型有3种: Sort merge join(SMJ排序-合并连接):首先生产driving table需要的数据,然后对这些数据按照连接操作关联列进行排序:然后生产probed ...
随机推荐
- yii2优化 - 开启 Schema 缓存
开启 Schema 缓存 Schema 缓存是一个特殊的缓存功能,每当你使用活动记录时应该要开启这个缓存功能.如你所知, 活动记录能智能检测数据库对象的集合(例如列名.列类型.约束)而不需要手动地描述 ...
- css学习_css三大特性
css三大特性 1.层叠性(就近原则) 2.继承性(和文字有关的会继承) 3.优先级 (权重问题) 权重:0,0,0,0 0001 ---标签选择器(注意:即使有20个标签选择器也不会比一个伪类选 ...
- arcengine新建要素类
ArcGIS里面新建数据集,看起来简单,平时都是默认创建,实际上好多细节问题我们都没注意到 一.在数据集上新建要素类: How to create a feature class within a f ...
- 知乎如何基于开源Druid打造下一代数据平台?
https://mp.weixin.qq.com/s/WXA_Pn5xwlL-cA4JaGRw6Q
- elasticsearch in docker/ and aggregation,,performance tune ;throughout
Docker环境中Elasticsearch的安装 ]https://wenchao.ren/archives/category/elasticsearch/page/2 [ElasticSearch ...
- [knowledge] 停止等待协议
再读TCP/IP详解 说到流量控制, 可能便涉及了两方面 1. 停止等待协议. https://baike.baidu.com/item/%E5%81%9C%E6%AD%A2%E7%AD%89%E5% ...
- [troubleshoot][archliunx][chromium][flash] chrome提示flash不是最新
最近chrome总是在提示flash不是最新要求更新. 原来以前用的flash包 chromium-pepper-flash 不见了,改名变成了pepper-flash. /home/tong [to ...
- Flink - watermark生成
参考,Flink - Generating Timestamps / Watermarks watermark,只有在有window的情况下才用到,所以在window operator前加上assig ...
- web.xml中 /和/*的区别
< url-pattern>/</url-pattern> 会匹配到/login这样的路径型url,不会匹配到模式为*.jsp这样的后缀型url< url-patter ...
- 转:eclipse maven build、maven install 等区别
原文地址:eclipse maven build.maven install 等区别