ML平台_饿了么实践
(转载至:https://zhuanlan.zhihu.com/p/28592540) 说到机器学习、大数据,大家听到的是 Hadoop 和 Spark 居多,它们跟 TensorFlow 是一个什么样的关系呢?是不是有 TensorFlow 就不需要 Spark 这些?
像 Hadoop 跟 Spark,背后都是 MapReduce。Hadoop 更多是去写文件,Spark 更多是通过内存。它们通过 MapReduce,下发 task 给这些 executor 去做。它们擅长的这种并行运算叫“Embarrassingly Parallel”,这种并行是非常完美的并行,要非常完美,最后收集结果。那么 Hadoop、Spark 用在哪?
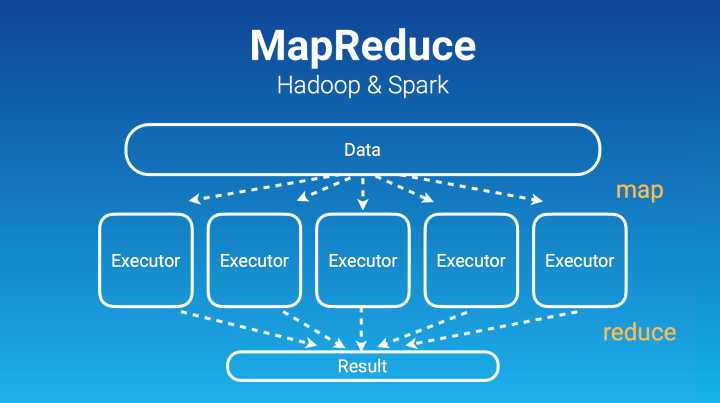
机器学习第一步非常关键,就是对数据的预处理,因为互联网公司有非常多结构化数据,存在 Hive、MySQL 里面。这些数据经过处理以后才能供机器学习使用。这类的预处理非常适合用 Hadoop、Spark 这些来做。
TensorFlow 特别擅长做深度学习,如果一些神经网络,最后放在一个 graph 上看的话,很轻松就会达到一个很复杂的程度。所以,这样一个 graph,用前面的 MapReduce 其实很难写,而且它也没办法那样完美并行,而且深度学习还有个反向传播的过程,更难做了。所以 Hadoop 跟 Spark 从架构本质上,根本就是做不了深度学习的。所以就出现了 TensorFlow。
为什么需要 TensorFlow 来做深度学习?TensorFlow 大体的思路是这样,用 Python,一般是用 Python 定义好深度学习神经网络以后,TensorFlow 会做成 DAG,有向无环图,然后把 DAG 交给 TensorFlow 的 C++ Core 来运行,这样保证它的运算效率非常高。所以我个人认为,对于一个 framework 是否支持深度学习,最关键的就是:它是否支持构建 DAG 和进行 DAG 运算

数据准备好了之后,我们把数据放在分布式存储里面。上面跑分布式 TensorFlow,然后 TensorFlow 用集群里的 CPU 资源和 GPU 资源做 training。 当模型训练好,用 TensorFlow Serving 能够接收线上的请求,实时做出预测。分布式存储和计算,这样两块组合起来,这是深度学习平台 elearn 做的事情

overview
elearn 是 TaaS (TensorFlow as a Service),去年 8 月底开始研发,受到 Google CloudML 的启发。我们 elearn 的一个核心想法就是:我们让算法工程师可以专注于算法,他们不用再多花精力去搞 CPU 资源、去搞发布。他们只要专心写算法就可以了,后面的事情全部交给 elearn。繁琐的事情,比如分布式存储、计算资源的弹性伸缩、IP / port 的管理、container 的生命周期,全部变成 API,不用管了。尤其这里面 IP 的管理 pod 的管理,本来也不应该算法工程师操心的。
而他们的现在现状是什么呢?现在算法工程师要操心非常多,他写完了之后,不知道怎么转化成工程产品;怎样大规模做 training;怎么做模型的版本管理,再到上线了以后,预测的性能不行。
这一切,导致深度学习没有办法拓展到更多业务,无法拓展到工程师这边来。然后让我们觉得 Deep Learning 好像有一点束之高阁的感觉
GPU: 讲到深度学习,大家一般都比较好奇 GPU 这方面的东西。GPU 很有意思,一般服务器会装好多块 GPU 卡,但是如果用的时候不做限制,就会导致 10 块卡全部用满。因此,需要所有同事建个微信群,大家商量好,你用 1 号卡,我用 2 号卡,第三个人用 3 号卡,基本上沟通靠微信群。这样 10 块卡的利用率极低。关键问题就在于需要手动设置两个环境变量 CUDA_DEVICE_ORDER 和 CUDA_VISIBLE_DEVICES 来限制使用 GPU。
你要知道没有开发者能一定记得每次设置这两个环境变量,而且这两个环境变量不能写在 .bashrc 这样的配置里面,因为每个人每次能够用的空闲 GPU 卡是不一样的。
但是如果在 elearn 的 container 里看到的,机器上虽然有 10 块卡,如果你只要一块卡,那么 elearn 就能做到让你在 container 里就只能看到一块卡,即使用爆了,也只能用这一张卡。这就是为什么要通过 container 来使用 GPU。
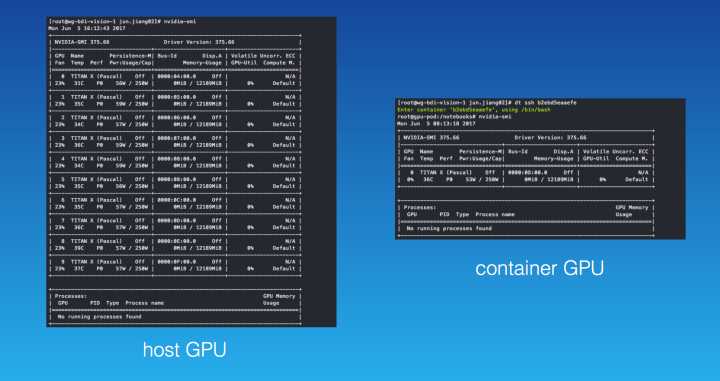
- 说到 GPU,提一句它的“内存”,跟平常的内存不一样, TensorFlow 里它默认是抢占式的,一上来就把这块 GPU 所有的内存都抢掉,防止后续的内存碎片问题,但这个设置其实是可以取消的。
- 再看 GPU 的 Docker image 直接用 Nvidia 打的 image 就可以了,还有基于此的 TensorFlow官方GPU image,非常好用。
- 最后讲到 GPU 跟 Docker。一说到在 Docker 上用 GPU,很多人都以为一定要用 Nvidia 修改版的 nvidia-docker 才行。其实根本不需要,直接用原生 Docker 就能做到前面的效果,而且 Kubernetes 也是这样做的。Kubernetes 只是帮你分 GPU ID,剩下的事情,比如原来 nvidia-docker 帮你做掉的事情,是需要 elearn 帮你做的。
分布式 training
- 说起分布式 training,就得提 TensorFlow 的上一代产品,DistBelief。它是谷歌内部的上一代机器学习框架。这一代的出现,就已经解决 model 的变量 size 超过了 GPU 显存的范围的问题了。随着公司的发展,大家多多少少会在这方面遇到这样的问题。就跟谷歌在好多年前就已经开始用 Borg,而直到现在,我们大家才用上 Kubernetes,才意识到企业确实需要这样一个东西。另外,分布式 training 可以给训练的过程加速。

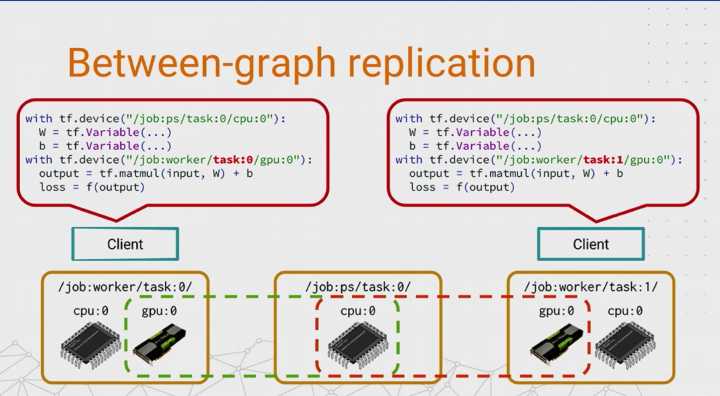
- 从单机版变成分布式 training,其原理,首先是把模型参数这块单独拆出来,放在单独的 PS (parameter server) 上面
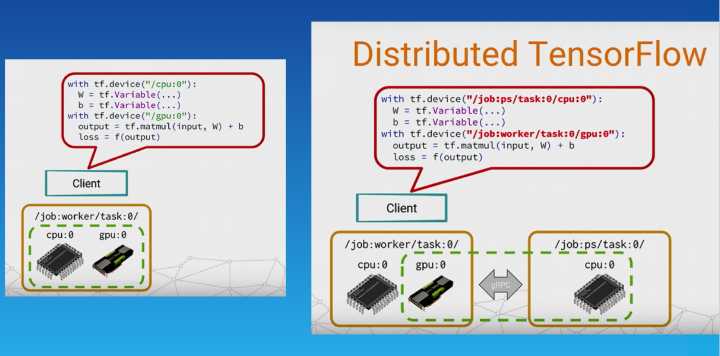
- 这个 PS 也是可以分布式的,这样就对模型大小理论上没有限制了。当再加一个 worker 进来的时候,每个 worker 在每一轮训练开始时,去拉 model 的最新状态。当它自己 Training 完了再把更新的内容告诉 PS,这样完成一次 Training。如果两个甚至更多 worker 在同时做这样的事情,那么就有两种模式,一种是同步,一种是异步
- 但值得注意的是,TensorFlow 只是一个代码框架,它是不管你如何启动运行的。所以一个 TensorFlow cluster 的启动运行全得靠工程师自己来。
- 如果想启动一个 10 台服务器组成的 cluster,你需要登录 10 台服务器、记下每个 DNS、IP、Port,设计 10 条不一样的启动命令,手动敲 10 遍等等;然后,还要自己搞分布式存储,mkdir 把模型存放整齐。一个月后,你或许早就忘了你的模型存在哪台机器的哪台目录了。这还没完,training 的时候,算法工程师要看 TensorBoard,才能知道训练得好不好(如果训练到一半,看效果不好,就可以直接把训练停掉了)。

- 好了,做这么多事情,到现在只训练了一个模型。业务上希望每周,甚至每天的新数据都要训练一版型模型,如果训练一个都这样麻烦,谁还受得了。
elearn 功能介绍
-
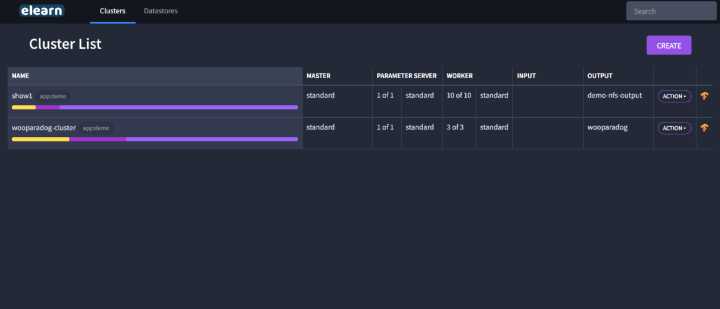
- 上图是elearn 主界面,在上面可以轻松创建 TensorFlow cluster,现在只需要提供你的 Docker image。然后借助 Datastore 定义任何的数据来源,启动命令。这和算法工程师在本地开发的时候敲命令一模一样,没有很大的迁移成本。
- 看到这里,你可能会发现 elearn 不仅仅可以做分布式 training,如果做单机版 training 怎么办?把 PS 和 worker 两项写成 0,只靠 master 工作,就是单机版 training
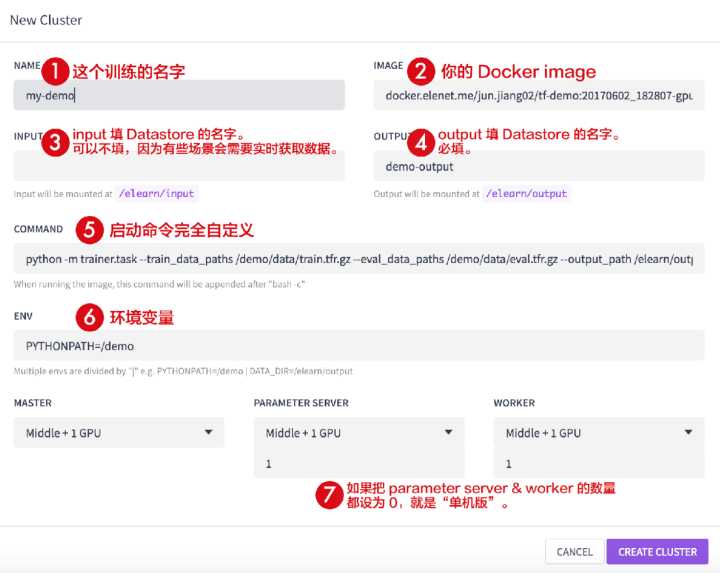
- 有了 elearn,要跑一个这样的 GPU & CPU 跑分就非常轻松,发四个 API 请求给 elearn, 过一会儿就可以看到结果

- 这里面进行了分布式 GPU 对比和 GPU & CPU 的对比,依次是 3 块 GPU、6 块 GPU、9 块 GPU。可以看到多块 GPU 一起接近于线性的性能提升。
- 这里即使大家觉得 GPU 很牛,但是 CPU 跟 GPU 到底差多少?这个地方也能看出来,同样是 9 个 CPU 和 9 个 GPU,性能差 9 到 10 倍,这算比较好的情况了。
- 也就是说 GPU 并没有你想想中的那么夸张,比如说 100 倍、1000 倍的提升,但是 GPU 的提升意义也非常大,以前训练等 10 天要出结果,现在用了 GPU 等 1 天就出结果了。
- 但是 GPU 非常贵,在企业里面 CPU 非常多非常多,如果 9 个 CPU 能顶一个 GPU。(当然再往上去,就不可以做这样的数学运算了,CPU 多了,瓶颈在于网络通讯之间的消耗了) 至少我觉得 1 块 GPU 跟 10 块 CPU 对于一个企业的成本是不一样的
Model + Serving
- 用户用着自己带来的 Datastore 做 training,model 也是先往用户的 Datastore 上面存。当你觉得这个 model 训练得效果比较好,就可以选择把这个 model 存进 elearn,由 elearn 帮你托管 model。这个 model 存了几次,都会记录好不同的版本。
- 当在线上使用 model 做预测的时候,有两种方式:第一种,由 elearn,启动 GRPC Serving,可以水平扩展;第二种,你可以把这个 model 下载,用 Golang、Java 这些语言把 model 直接加载进代码里,跟随着业务一起上线

实现过程思考
第一,为 TensorFlow 量身打造的。目前为止 elearn 是为 TensorFlow 量身打造的。包括现在 Amazon 的 MXNet 和 Facebook pyTorch,还有一些新的 framework,尤其是新手,觉得非常乱,社区和微信群各种横向的比拼,不知改选哪个。
其实,你要知道为什么 TensorFlow 会被 Google 发明出来,就是因为谷歌意识到每个算法工程师,都是自己实现一套代码,只能做某一件事,别人很难看懂。等工程师应用的时候,根本没有办法分布式用、没有办法大范围用。这就造成了科学家、算法工程师跟实际场景的脱节。这个时候谷歌才推出了 TensorFlow,用同一个 framework 写,大家都能看懂,工具很多,还保证性能不错。所以 TensorFlow 被发明出来了,就不要再折腾别的框架了,好好把 TensorFlow 做好。
除非有一种情况,需要再接受一个框架,就是当“下一代”架构被设计出来的时候,那么“下一代”框架可以取代 TensorFlow,这时 elearn 也只要多写个 driver 就可以立马支持。但是在此之前,我不会那么做,我们把 TensorFlow 支持好,其他 framework 的所谓特色功能,TensorFlow 一定在未来版本实现不了吗?Google 有着非常丰富的社区运营经验,TensorFlow 的社区会让 TensorFlow更加领先。第二,我在设计 elearn 的 cloud interfaces 的时候,不是设计成“以 Pod 为最小单元”,如果以这样作为接口来写 interfaces,就可以轻松接各种 cloud了,但一旦这样做了以后,elearn 就只能用各个 cloud 功能的交集,也就是只剩下最通用的部分,而忽略了每个 cloud 编排的特色。
所以我在做 elearn cloud interfaces 的时候是面向功能的。这个同样可以实现功能,同样可以写其他的 Driver 来轻松支持 Kubernetes 以外的 cloud,而且这样还能够用到每个 cloud 特色的编排和功能。所以 elearn 是用了非常多 Kubernetes 所特有的编排特性的。
第三,我在这个项目中第一次尝试,把 Kubernetes 真的当成一个 OS 来用,这是什么意思呢?举个最简单的例子,以 save model 为例,如果按往常,一个很自然的想法,在一个中心化的存储上面启动一个 daemon,完成文件操作的请求。但这样的劣势就是所有的瓶颈阻塞在那台 daemon 上。所以我们对于 post run,保存 model,这些都是一个个独立的 Kubernetes Job,并不在 elearn server 或某台专门的 server 上运行。Kubernetes 调度 Job 就像 OS 调度一个进程一样,让 Job 完全分布式运行。
elearn:未来
在 elearn 的基础上,我们还会提供更多工具。使深度学习的训练变得方便,才能有助于它在应用上真正发力。
ML平台_饿了么实践的更多相关文章
- ML平台_小米深度学习平台的架构与实践
(转载:http://www.36dsj.com/archives/85383)机器学习与人工智能,相信大家已经耳熟能详,随着大规模标记数据的积累.神经网络算法的成熟以及高性能通用GPU的推广,深度学 ...
- ML平台_微博深度学习平台架构和实践
( 转载至: http://www.36dsj.com/archives/98977) 随着人工神经网络算法的成熟.GPU计算能力的提升,深度学习在众多领域都取得了重大突破.本文介绍了微博引入深度学 ...
- ML平台_设计要点
如果说机器是人类手的延伸.交通工具是人类腿的延伸,那么人工智能就是人类大脑的延伸,甚至可以帮助人类自我进化,超越自我.人工智能也是计算机领域最前沿和最具神秘色彩的学科,科学家希望制造出代替人类思考的智 ...
- 云之讯融合通讯开放平台_提供融合语音,短信,VoIP,视频和IM等通讯API及SDK。
云之讯融合通讯开放平台_提供融合语音,短信,VoIP,视频和IM等通讯API及SDK. undefined 全明星之极验证 - SendCloud undefined [转载]国内外几个主流的在线开发 ...
- 实时竞价RTB广告平台_传漾科技_中国领先的智能数字营销引擎
实时竞价RTB广告平台_传漾科技_中国领先的智能数字营销引擎 Programmatic Framework™ 传漾程序化购买框架
- 涂鸦基于OAuth2在开发者平台上的探索与实践
前言 开发授权(OAuth2)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资料(如照片.视频.联系人列表),而无需将用户名和密码提供给第三方应用. OAuth2允许用户提供一 ...
- (转) Android平台上关于IM的实践总结
前言 IM通信在互联网发展到现在已经是码农的世界里人尽皆知的技术,特别在当下移动互联网迅猛发展的时代这种技术的开发也更加火热,其中老牌的代表作就有QQ和MSN,和最近新崛起的微信,默默,易信,来往等眼 ...
- ML平台_Angel参考
Angel 是腾讯开源基于参数服务器(Parameter Server)理念的机器学习框架(为支持超大维度机器学习模型运算而生).核心设计理念围绕模型,它将高维度的大模型切分到多个参数服务器节点,并通 ...
- 开源|性能优化利器:数据库审核平台Themis的选型与实践
作者:韩锋 出处:DBAplus社群分享:来源:宜信技术学院 Themis开源地址:https://github.com/CreditEaseDBA 一.面临的挑战 1.运维规模及种类 我相信,这也是 ...
随机推荐
- 整理有关浏览器兼容性的css样式
去掉IE自带的删除功能的×号 input::-ms-clear{display:none;} 去掉IE自带密码框的眼睛样式 input::-ms-reveal{display:none;}
- hadoop day 3
1.map:局部处理:reduce:汇总 mapper对数据做切分,一份程序在不同的DataNode上独立运行对数据进行处理,reduce程序将所有DataNode上的统计数据进行汇总 Mapper& ...
- C++数组初始化
局部数组:没有默认值,如果声明的时候不定义,则会出现随机数(undefined): 全局数组:声明时不赋值,默认值为0
- day03用户交互、基本数据类型、运算符
用户交互 在实际应用中,我们经常需要用户输入相应信息,根据用户输入信息进行反馈,此时我们需要input/output信息 python中提供了便捷的输入方法input()和print() 在pytho ...
- xdoj-1279(有趣的线段树--吉司机?!)
题目链接 一 核心: f(x)=91 (x<=100) f(x)=x-10 (x>100) 那么同一区间就可能不同的操作,那么该怎么解决呢? 我门直到同一区间的数据属于同一类别的时候再进行 ...
- //生成四位数的验证码--->
- SkyWalking+SkyApm-dotnet分布式链路追踪系统
SkyWalking+SkyApm-dotnet分布式链路追踪系统 对于普通系统或者服务来说,一般通过打日志来进行埋点,然后再通过elk或splunk进行定位及分析问题,更有甚者直接远程服务器,直接操 ...
- acm 2072
////////////////////////////////////////////////////////////////////////////////#include<iostream ...
- ionic项目中 软键盘弹出之后的问题:
Android SDK目前提供的软键盘弹出模式接口只有两种: 一是弹出时自动回冲界面,将所有元素上顶: 一种则是不重绘界面,直接将控件元素遮住: 1. ionic 中弹出键盘遮挡住输入框(覆盖 ...
- LinkedList(实现了queue,deque接口,List接口)实现栈和队列的功能
LinkedList是用双向链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢. 底层是一个双向链表,链表擅长插入和删除操作,队列和栈最常用的2种操作都设计到插入和删除 impo ...