TensorFlow queue多线程读取数据
一、tensorflow读取机制图解
我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
解决这个问题方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
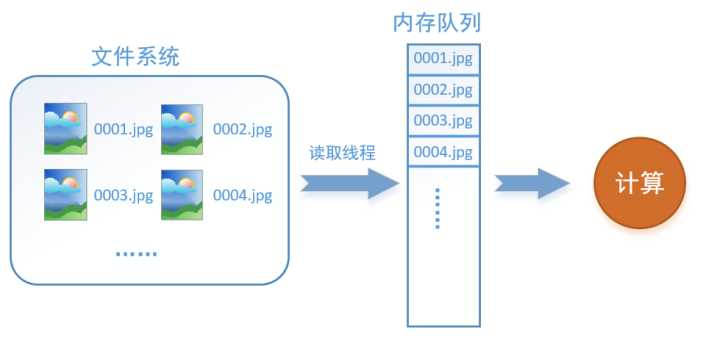
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。
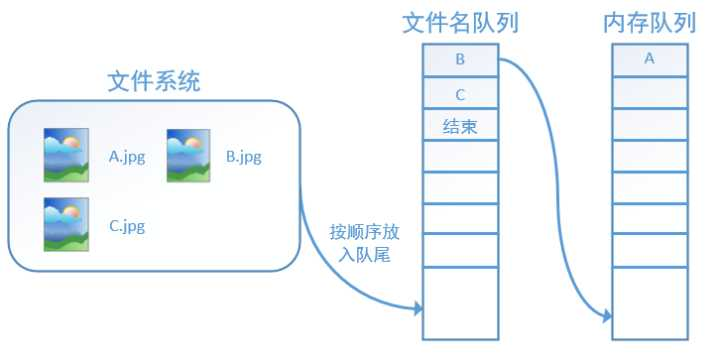

如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。
二、tensorflow读取数据机制的对应函数
对于文件名队列,我们使用tf.train.string_input_producer函数。这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,表示epoch数。另外一个就是shuffle是指在一个epoch内文件的顺序是否被打乱。
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了。
在我们使用tf.train.string_input_producer创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中,此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。使用tf.train.start_queue_runners之后,才会启动填充队列的线程,这时系统就不再“停滞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了。
reader每次读取一张图片并保存。
import tensorflow as tf # 新建一个Session
with tf.Session() as sess:
# 我们要读三幅图片A.jpg, B.jpg, C.jpg
filename = ['A.jpg', 'B.jpg', 'C.jpg']
# string_input_producer会产生一个文件名队列
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader从文件名队列中读数据。对应的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之后,才会开始填充队列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 获取图片数据并保存
image_data = sess.run(value)
with open('read/test_%d.jpg' % i, 'wb') as f:
f.write(image_data)
三个概念:
Queue是TF队列和缓存机制的实现QueueRunner是TF中对操作Queue的线程的封装Coordinator是TF中用来协调线程运行的工具
Queue:
- tf.FIFOQueue 按入列顺序出列的队列
- tf.RandomShuffleQueue 随机顺序出列的队列
- tf.PaddingFIFOQueue 以固定长度批量出列的队列
- tf.PriorityQueue 带优先级出列的队列
创建函数的参数:
tf.FIFOQueue(capacity, dtypes, shapes=None, names=None ...)
import tensorflow as tf
tf.InteractiveSession() q = tf.FIFOQueue(2, "float")
init = q.enqueue_many(([0,0],)) x = q.dequeue()
y = x+1
q_inc = q.enqueue([y]) init.run()
q_inc.run()
q_inc.run()
q_inc.run()
x.eval() # 返回1
x.eval() # 返回2
x.eval() # 卡住
QueueRunner
Tensorflow的计算主要在使用CPU/GPU和内存,而数据读取涉及磁盘操作,速度远低于前者操作。因此通常会使用多个线程读取数据,然后
使用一个线程消费数据,QueueRunner就是来管理这些读写队列的线程。
import tensorflow as tf
import sys
q = tf.FIFOQueue(10, "float")
counter = tf.Variable(0.0) #计数器
# 给计数器加一
increment_op = tf.assign_add(counter, 1.0)
# 将计数器加入队列
enqueue_op = q.enqueue(counter) # 创建QueueRunner
# 用多个线程向队列添加数据
# 这里实际创建了4个线程,两个增加计数,两个执行入队
qr = tf.train.QueueRunner(q, enqueue_ops=[increment_op, enqueue_op] * 2) # 主线程
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# 启动入队线程
qr.create_threads(sess, start=True)
for i in range(20):
print (sess.run(q.dequeue()))
增加计数的进程会不停的后台运行,执行入队的进程会先执行10次(因为队列长度只有10),然后主线程开始消费数据,当一部分数据消费被后,入队的进程又会开始执行。最终主线程消费完20个数据后停止,但其他线程继续运行,程序不会结束。
Coordinator:
用来保存线程组运行状态的协调器对象
import tensorflow as tf
import threading, time # 子线程函数
def loop(coord, id):
t = 0
while not coord.should_stop():
print(id)
time.sleep(1)
t += 1
# 只有1号线程调用request_stop方法
if (t >= 2 and id == 1):
coord.request_stop() # 主线程
coord = tf.train.Coordinator()
# 使用Python API创建10个线程
threads = [threading.Thread(target=loop, args=(coord, i)) for i in range(10)] # 启动所有线程,并等待线程结束
for t in threads: t.start()
coord.join(threads)
所有的子线程执行完两个周期后都会停止,主线程会等待所有子线程都停止后结束,从而使整个程序结束。由此可见,只要有任何一个线程调用了Coordinator的request_stop方法,所有的线程都可以通过should_stop方法感知并停止当前线程。
ALL:
第一种,显式的创建QueueRunner,然后调用它的create_threads方法启动线程。例如下面这段代码:
import tensorflow as tf # 1000个4维输入向量,每个数取值为1-10之间的随机数
data = 10 * np.random.randn(1000, 4) + 1
# 1000个随机的目标值,值为0或1
target = np.random.randint(0, 2, size=1000) # 创建Queue,队列中每一项包含一个输入数据和相应的目标值
queue = tf.FIFOQueue(capacity=50, dtypes=[tf.float32, tf.int32], shapes=[[4], []]) # 批量入列数据(这是一个Operation)
enqueue_op = queue.enqueue_many([data, target])
# 出列数据(这是一个Tensor定义)
data_sample, label_sample = queue.dequeue() # 创建包含4个线程的QueueRunner
qr = tf.train.QueueRunner(queue, [enqueue_op] * 4) with tf.Session() as sess:
# 创建Coordinator
coord = tf.train.Coordinator()
# 启动QueueRunner管理的线程
enqueue_threads = qr.create_threads(sess, coord=coord, start=True)
# 主线程,消费100个数据
for step in range(100):
if coord.should_stop():
break
data_batch, label_batch = sess.run([data_sample, label_sample])
# 主线程计算完成,停止所有采集数据的进程
coord.request_stop()
coord.join(enqueue_threads)
第二种,使用全局的start_queue_runners方法启动线程。
在这个例子中,tf.train.string_input_produecer将一个隐含的QueueRunner添加到全局图中,类似的操作还有tf.train.shuffle_batch等)。由于没有显式地返回QueueRunner来用create_threads启动线程,这里用tf.train.start_queue_runners方法直接启动tf.GraphKeys.QUEUE_RUNNERS集合中的所有队列线程。
import tensorflow as tf # 同时打开多个文件,显示创建Queue,同时隐含了QueueRunner的创建
filename_queue = tf.train.string_input_producer(["data1.csv","data2.csv"])
reader = tf.TextLineReader(skip_header_lines=1)
# Tensorflow的Reader对象可以直接接受一个Queue作为输入
key, value = reader.read(filename_queue) with tf.Session() as sess:
coord = tf.train.Coordinator()
# 启动计算图中所有的队列线程
threads = tf.train.start_queue_runners(coord=coord)
# 主线程,消费100个数据
for _ in range(100):
features, labels = sess.run([data_batch, label_batch])
# 主线程计算完成,停止所有采集数据的进程
coord.request_stop()
coord.join(threads)
这两种方式在效果上是等效的
import pandas as pd
import numpy as np
import tensorflow as tf def generate_data():
num = 25
label = np.asarray(range(0, num))
images = np.random.random([num, 5])
print('label size :{}, image size {}'.format(label.shape, images.shape))
return images,label def get_batch_data():
images, label = generate_data()
input_queue = tf.train.slice_input_producer([images, label], shuffle=False,num_epochs=2)
image_batch, label_batch = tf.train.batch(input_queue, batch_size=5, num_threads=1, capacity=64,allow_smaller_final_batch=False)
return image_batch,label_batch images,label = get_batch_data()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())#这一行必须加,因为slice_input_producer的原因
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess,coord)
try:
while not coord.should_stop():
i,l = sess.run([images,label])
print(i)
print(l)
except tf.errors.OutOfRangeError:
print('Done training')
finally:
coord.request_stop()
coord.join(threads)
sess.close()
使用队列机制不需要 feed_dict,不再浪费内存,并提高GPU的利用率,节省训练时间
文件准备
|
1
2
3
4
5
6
7
|
$ echo -e "Alpha1,A1\nAlpha2,A2\nAlpha3,A3" > A.csv
$ echo -e "Bee1,B1\nBee2,B2\nBee3,B3" > B.csv
$ echo -e "Sea1,C1\nSea2,C2\nSea3,C3" > C.csv
$ cat A.csv
Alpha1,A1
Alpha2,A2
Alpha3,A3
|
单个Reader,单个样本
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
print example.eval() #取样本的时候,一个Reader先从文件名队列中取出文件名,读出数据,Decoder解析后进入样本队列。
coord.request_stop()
coord.join(threads)
# outpt
Alpha1
Alpha2
Alpha3
Bee1
Bee2
Bee3
Sea1
Sea2
Sea3
Alpha1
单个Reader,多个样本
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print example_batch.eval()
coord.request_stop()
coord.join(threads)
# output
# ['Alpha1' 'Alpha2' 'Alpha3' 'Bee1' 'Bee2']
# ['Bee3' 'Sea1' 'Sea2' 'Sea3' 'Alpha1']
# ['Alpha2' 'Alpha3' 'Bee1' 'Bee2' 'Bee3']
# ['Sea1' 'Sea2' 'Sea3' 'Alpha1' 'Alpha2']
# ['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Sea1']
# ['Sea2' 'Sea3' 'Alpha1' 'Alpha2' 'Alpha3']
# ['Bee1' 'Bee2' 'Bee3' 'Sea1' 'Sea2']
# ['Sea3' 'Alpha1' 'Alpha2' 'Alpha3' 'Bee1']
# ['Bee2' 'Bee3' 'Sea1' 'Sea2' 'Sea3']
# ['Alpha1' 'Alpha2' 'Alpha3' 'Bee1' 'Bee2']
多Reader,多个样本
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print example_batch.eval()
coord.request_stop()
coord.join(threads) # output
# ['Alpha1' 'Alpha2' 'Alpha3' 'Bee1' 'Bee2']
# ['Bee3' 'Sea1' 'Sea2' 'Sea3' 'Alpha1']
# ['Alpha2' 'Alpha3' 'Bee1' 'Bee2' 'Bee3']
# ['Sea1' 'Sea2' 'Sea3' 'Alpha1' 'Alpha2']
# ['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Sea1']
# ['Sea2' 'Sea3' 'Alpha1' 'Alpha2' 'Alpha3']
# ['Bee1' 'Bee2' 'Bee3' 'Sea1' 'Sea2']
# ['Sea3' 'Alpha1' 'Alpha2' 'Alpha3' 'Bee1']
# ['Bee2' 'Bee3' 'Sea1' 'Sea2' 'Sea3']
# ['Alpha1' 'Alpha2' 'Alpha3' 'Bee1' 'Bee2']
tf.train.batchtf.train.shuffle_batch函数是单个Reader读取,但是可以多线程。tf.train.batch_join与tf.train.shuffle_batch_join可设置多Reader读取,每个Reader使用一个线程。至于两种方法的效率,单Reader时,2个线程就达到了速度的极限。多Reader时,2个Reader就达到了极限。所以并不是线程越多越快,甚至更多的线程反而会使效率下降。
迭代控制
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False, num_epochs=3) # num_epoch: 设置迭代数
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)]
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=5)
init_local_op = tf.initialize_local_variables()
with tf.Session() as sess:
sess.run(init_local_op) # 初始化本地变量
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop():
print example_batch.eval()
except tf.errors.OutOfRangeError:
print('Epochs Complete!')
finally:
coord.request_stop()
coord.join(threads)
coord.request_stop()
coord.join(threads)
# output
# ['Alpha1' 'Alpha2' 'Alpha3' 'Bee1' 'Bee2']
# ['Bee3' 'Sea1' 'Sea2' 'Sea3' 'Alpha1']
# ['Alpha2' 'Alpha3' 'Bee1' 'Bee2' 'Bee3']
# ['Sea1' 'Sea2' 'Sea3' 'Alpha1' 'Alpha2']
# ['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Sea1']
# Epochs Complete!
参考自:在迭代控制中,记得添加tf.initialize_local_variables(),官网教程没有说明,但是如果不初始化,运行就会报错。
https://zhuanlan.zhihu.com/p/27238630
http://www.jianshu.com/p/d063804fb272
http://honggang.io/2016/08/19/tensorflow-data-reading/
http://www.jianshu.com/p/f07f28448313
TensorFlow queue多线程读取数据的更多相关文章
- Tensorflow机器学习入门——读取数据
TensorFlow 中可以通过三种方式读取数据: 一.通过feed_dict传递数据: input1 = tf.placeholder(tf.float32) input2 = tf.placeho ...
- TensorFlow从0到1之TensorFlow csv文件读取数据(14)
大多数人了解 Pandas 及其在处理大数据文件方面的实用性.TensorFlow 提供了读取这种文件的方法. 前面章节中,介绍了如何在 TensorFlow 中读取文件,本节将重点介绍如何从 CSV ...
- Tensorflow学习教程------读取数据、建立网络、训练模型,小巧而完整的代码示例
紧接上篇Tensorflow学习教程------tfrecords数据格式生成与读取,本篇将数据读取.建立网络以及模型训练整理成一个小样例,完整代码如下. #coding:utf-8 import t ...
- tf多线程读取数据
多线程读取数据的机制 tf中多线程读取数据跟常规的python多线程思路一致,是基于Queue的多线程编程. 主线程读取数据,然后计算,在读数据这部分有两个线程,一个线程读取文件名,生成文件名队列,另 ...
- Tensorflow高效读取数据的方法
最新上传的mcnn中有完整的数据读写示例,可以参考. 关于Tensorflow读取数据,官网给出了三种方法: 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码 ...
- 云端TensorFlow读取数据IO的高效方式
低效的IO方式 最近通过观察PAI平台上TensoFlow用户的运行情况,发现大家在数据IO这方面还是有比较大的困惑,主要是因为很多同学没有很好的理解本地执行TensorFlow代码和分布式云端执行T ...
- [置顶]
云端TensorFlow读取数据IO的高效方式
低效的IO方式 最近通过观察PAI平台上TensoFlow用户的运行情况,发现大家在数据IO这方面还是有比较大的困惑,主要是因为很多同学没有很好的理解本地执行TensorFlow代码和分布式云端执行T ...
- 第十二节,TensorFlow读取数据的几种方法以及队列的使用
TensorFlow程序读取数据一共有3种方法: 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据. 从文件读取数据: 在TensorFlow图的起 ...
- TensorFlow高效读取数据的方法——TFRecord的学习
关于TensorFlow读取数据,官网给出了三种方法: 供给数据(Feeding):在TensorFlow程序运行的每一步,让python代码来供给数据. 从文件读取数据:在TensorFlow图的起 ...
随机推荐
- POJ 2247 Humble Numbers
A number whose only prime factors are 2,3,5 or 7 is called a humble number. The sequence 1, 2, 3, 4, ...
- java元注解 @Retention注解使用
@Retention定义了该Annotation被保留的时间长短: 1.某些Annotation仅出现在源代码中,而被编译器丢弃: 2.另一些却被编译在class文件中,注解保留在class文件中,在 ...
- JAVA迭代器学习--在JAVA中实现线性表的迭代器
1,迭代器是能够对数据结构如集合(ADT的实现)进行遍历的对象.在遍历过程中,可以查看.修改.添加以及删除元素,这是它与一般的采用循环来遍历集合中的元素不同的地方.因为,通常用循环进行的遍历操作一般是 ...
- The provider is not compatible with the version of Oracle client
保留下安装文件夹里的所有文件.然后把我那个很小应用软件(需要访问远程的oracle数据库)放在这个文件夹里.删除一下直接感觉无用的文件,先抽取可 能用不着的文件,保留放在另一个备用的文件夹里,然后运行 ...
- Mac下压力测试工具siege
安装: brew install siege 用法: siege -c 并发数 -t 运行测试时间 URL 如: siege -c 1000 -t 5S URL 这里要注意的是-t后面的时间要带单位, ...
- MySQL复制框架
一.复制框架 开始接触复制时,看到各种各样的复制,总想把不同类型对应起来,结果越理越乱~究其原因就是对比了不同维度的属性,不同维度得出的结果集之间必然存在交集,没有必要将不同维度的属性安插到成对的萝卜 ...
- python中dir(),__dict__
dir()是python的一个函数, dir()函数如果接受的参数是一个类,则返回这个类所有的类变量和方法 dir()函数如果接收的参数是一个类的实例,则返回这个实例所有的实例变量,对应的类的类变量, ...
- tidb 架构 ~Tidb学习系列(3)
tidb集群安装测试1 环境 3台机器2 配置 server1 pd服务+tidb-server server2 tidb-kv server3 tidb-kv3 环境配置命令 ser ...
- 如何消除手机设置的字体大小对Cordova app(Android)界面font-size的影响
===================== 更新分割线 =================== 现在发现其实不需要用安卓编辑器打开,也能找到这个文件,路径是platforms\android\Cord ...
- maven名词解释
Maven名词解释 Project:任何你想build的事物,Maven都可以认为它们是工程.这些工程被定义为工程对象模型(POM,Poject Object Model).一个工程可以依赖其它的工程 ...