论文笔记之:SeqGAN: Sequence generative adversarial nets with policy gradient
SeqGAN: Sequence generative adversarial nets with policy gradient
AAAI-2017
Introduction :
产生序列模拟数据来模仿 real data 是无监督学习中非常重要的课题之一。最近, RNN/LSTM 框架在文本生成上取得了非常好的效果,最常见的训练方法是:给定上一个 token,推测当前 token 的最大化似然概率。但是最大似然方法容易受到 “exposure bias” 的干扰:the model generates a sequence iteratively and predicts next token conditioned on its previously predicted ones that may be never observed in the training data。这种 training 和 inference 之间的差异可以招致 accumulatively,随着 sequence 的累计,将会随着 sequence 的增长,变得 prominent。为了解决这个问题,Bengio 在 2015 年提出了 schedule sampling (SS) 的方法,但是又有人说这种方法在某些情况下也会失效。另一个可能的解决方案(the training/inference discrepancy problem)是:在整个产生的序列上构建损失函数,而不是每一个翻译(to build the loss function on the entire generated sequence instead of each trainsition)。但是,在许多其他的应用上,如:poem generation 和 chatbot,一个 task specific loss 无法直接准确的用来评价产生的序列。
GAN 是最近比较热门的研究课题,已经广泛的应用于 CV 的许多课题上,但是,不幸的是,直接用 GAN 来产生 sequence 有两个问题:
(1),GAN 被设计用来产生 real-valued, continuous data,但是在直接产生 离散的 tokens 的序列,是有问题的,如:text。The reason is that in GANs, the generator starts with random sampling first and then a determistic transform, govermented by the model parameters. As such, the gradient of the loss from D w.r.t. the outputs by G is used to guide the generative model G (paramters) to slightly change the generated value to make it more realistic. 但是,如果基于离散的 tokens 产生的数据,从 D 的 loss 得到的 “slight change” 却不是很有道理,因为可能根本不存在这样的 token 使得这一改变有意义(因为 字典空间是有效的)。
(2),GAN 仅仅可以提供 score/loss 给整个的 sequence,而对于部分产生的序列,却无法判断目前已经有多好了。(GAN can only give the score/loss for an entire sequence when it has been generated; for a partially generated sequence, it is non-trivial to balance how good as it is now and the future score as the entire sequence. )
本文提出一种思路来解决上述问题,将 序列产生问题 看做是 序列决策问题(consider the sequence generation procedure as a sequential decision making problem)。产生器 被认为是 RL 当中的 agent;状态是 目前已经产生的 tokens,动作是 下一步需要产生的 token。不像 Bahdanau et al. 2016 提出的方法那样需要 a task specific sequence score, such as BLEU in machine translation,为了给出奖励,我们用 discriminator 来评价 sequence,并且反馈评价来引导 generative model 的学习。为了解决 当输出是离散的,梯度无法回传给 generative model 的情况,我们将 generative model 看做是 stochastic parameterized policy。在我们的策略梯度,我们采用 MC 搜索来近似 the state-action value。我们直接用 policy gradient 来训练 policy,很自然的就避免了传统 GAN 中,离散数据的微分困难问题(the differentiation difficulty for discrete data in a conventional GAN)。
Sequence Generative Adversarial Nets :
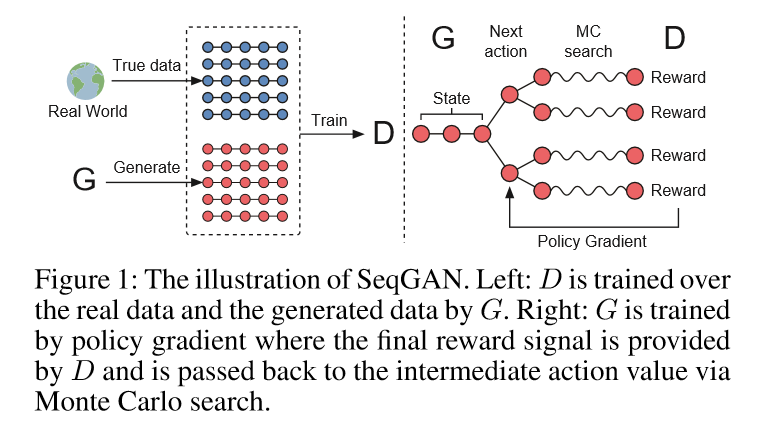
As illustrated in Figure 1, the discriminative model Dφ is trained by providing positive examples from the real sequence data and negative examples from the synthetic sequences generated from the generative model Gθ. At the same time, the generative model Gθ is updated by employing a policy gradient and MC search on the basis of the expected end reward received from the discriminative model Dφ. The reward is estimated by the likelihood that it would fool the discriminative model Dφ. The specific formulation is given in the next subsection.
SeqGAN via PolicyGradient :
Following (Sutton et al. 1999), when there is no intermediate reward, the objective of the generator model (policy) Gθ(yt|Y1:t−1) is to generate a sequence from the start state s0 to maximize its expected end reward:

其中,RT 是整个序列的奖励,奖励来自于 判别器 Dφ。QGθ Dφ(s,a) is the action-value function of a sequence, i.e. the expected accumulative reward starting from state s, taking action a, and then following policy Gθ. 目标函数的合理性应该是: 从给定的初始状态,产生器的目标是产生一个序列,使得 discriminator 认为是真的。
下一个问题就是:如何如何预测 the action-value function。本文当中,我们采用 REINFORCE algorithm,consider the estimated probability of being real by the discriminator D as the reward。意思是说,如果 判别器 D 认为给定的 fake sequence 是真的,其概率记为 reward,此时:概率越高,reward 越大,这两者是成正比例关系的。正式的来说,我们有:

然而,这个 discriminator 仅仅提供了一个 reward 给一个已经结束的 sequence。因为我们实际上关心的是长期的汇报,在每一个时间步骤,我们不但应该考虑到 previous tokens 的拟合程度,也考虑到 the resulted future outcome。就像是下棋的游戏,玩家有时会放弃即可的奖赏,而为了得到更加长远的奖励。所以,为了评价 the action-value for an intermediate state,我们采用 MC search with a roll-out policy to sample the unkown last T-1 tokens。我们表示一个 N-time 的 MC search 为:
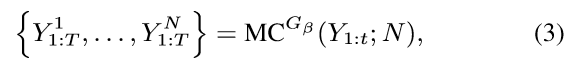
其中,Y^n_{1:t} ={y1, ... , yt} and Y^n_{t+1:T} is sampled based on the roll-out policy and the current state。在我们的实验当中,$G\beta$ 也设置为 the generator。为了降低 variance,并且得到更加精确地 action value 的估计值,我们运行 the roll-out policy starting from current state 直到 序列的结束,N times,以得到一批输出样本。所以,我们有:
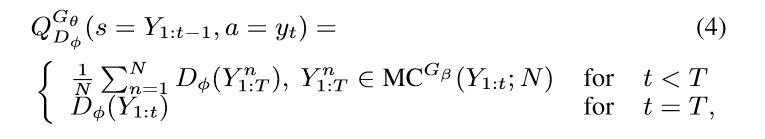
其中,我们看到 当没有即可奖赏的时候,该函数被迭代的定义为:the next-state value starting from state s' = Y1:t and rolling out to the end。
利用 判别器 D 作为奖赏函数的一个函数是:it can be dynamically updated to further improve the generative model interatively(为了进一步的提升产生式模型,它可以被动态的更新)。一旦我们有了一笔新的 更加 realistic 的产生的序列,我们应该重新训练 the discriminator model as follows:
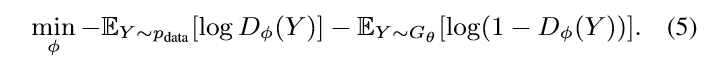
每次当一个新的判别式模型已经被训练完毕的时候,我们已经准备好来更新 generator。所提出的 基于策略的方法依赖于优化一个参数化的策略,来直接最大化 the long-term reward。目标函数 J 的梯度可以写为:
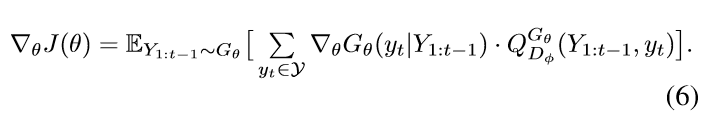
上述形式是由于 the deterministic state transition and zero intermediate rewards。利用 likelihood ratio,我们构建一种 unbiased estimation of Eq.(6) :
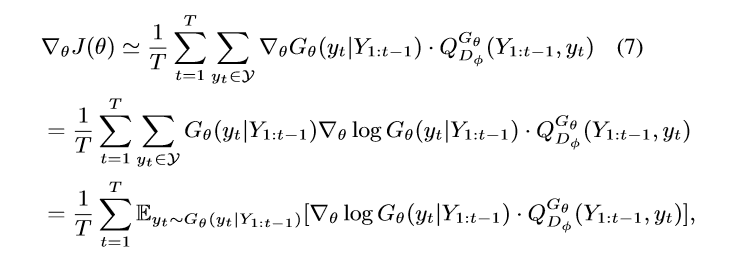
其中,$Y_{1:t}$ 是观察到的 intermediate state sampled from $G\theta$。因为期望 E[*] 可以通过采样的方法进行估计,我们然后更新产生器的参数:
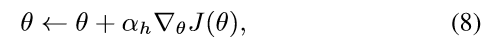
其中,$\alpha$ 代表了对应的时刻 h-th step 的学习率。
整体的算法流程如下图所示:

本文首先用 最大似然估计的方法进行预训练 产生器 G,然后用 迭代的进行 G, D 的训练。
然后就是对 G 和 D 的具体结构进行了解释:
The Generative Model for Sequence:
用 LSTM 来编码 sentences,然后将其映射到 下一个时刻 token 的概率分布。
The Discriminative Model for Sequence:
此处的判别器,作者利用 CNN 的方法来进行判别。作者首先将 Word 转为 vector,然后一句话弄成了一个 matrix,然后用多个卷积核,进行特征提取。为了提升精度,作者也加了 highway architecture based on the pooled feature maps. 最后,添加了 fc layer 以及 sigmoid activation 来输出 给定的序列为真的概率(to output the probabiltiy that the input sequence is real)。优化的目标是:最小化 the groundtruth labels 和 the predicted probability 之间的 cross entropy loss。
论文笔记之:SeqGAN: Sequence generative adversarial nets with policy gradient的更多相关文章
- 论文笔记之:Conditional Generative Adversarial Nets
Conditional Generative Adversarial Nets arXiv 2014 本文是 GANs 的拓展,在产生 和 判别时,考虑到额外的条件 y,以进行更加"激烈 ...
- 论文笔记——N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning
论文地址:https://arxiv.org/abs/1709.06030 1. 论文思想 利用强化学习,对网络进行裁剪,从Layer Removal和Layer Shrinkage两个维度进行裁剪. ...
- 论文笔记之:Generative Adversarial Nets
Generative Adversarial Nets NIPS 2014 摘要:本文通过对抗过程,提出了一种新的框架来预测产生式模型,我们同时训练两个模型:一个产生式模型 G,该模型可以抓住数据分 ...
- 论文笔记之:Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks NIPS 2015 摘要:本文提出一种 ...
- Generative Adversarial Nets(原生GAN学习)
学习总结于国立台湾大学 :李宏毅老师 Author: Ian Goodfellow • Paper: https://arxiv.org/abs/1701.00160 • Video: https:/ ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- Generative Adversarial Nets[Pre-WGAN]
本文来自<towards principled methods for training generative adversarial networks>,时间线为2017年1月,第一作者 ...
- GAN(Generative Adversarial Nets)的发展
GAN(Generative Adversarial Nets),产生式对抗网络 存在问题: 1.无法表示数据分布 2.速度慢 3.resolution太小,大了无语义信息 4.无reference ...
随机推荐
- keras如何求分类问题中的准确率和召回率
https://www.zhihu.com/question/53294625 由于要用keras做一个多分类的问题,评价标准采用precision,recall,和f1_score:但是keras中 ...
- RobotFrameWork(十三)RobotFramework与loadrunner性能测试结合(基于Remote库)
一般我们进行完功能测试,都需要进行下性能测试,那么这章我来介绍下,RobotFramework与loadrunner性能测试的融合,即运行完自动化功能测试,借助RobotFramework的Remot ...
- 浏览器页面请求js、css大文件处理
当页面引用一个比较大的js和css文件时,会出现较大下载延迟,占用带宽的问题,如果一个应用里有很多这样的js或CSS文件,那么就需要优化了. 比如ext-all.js有1.4M,页面引用这个文件,正常 ...
- pyspider 示例
数据存放目录: C:\Users\Administrator\data 升级版(可加载文章内所有多层嵌套的图片标签) #!/usr/bin/env python # -*- encoding: utf ...
- vue中使用第三方UI库的移动端rem适配方案
需求:使用vue-cli脚手架搭建项目,并且使用第三方的UI库(比如vant,mint ui)的时候,因为第三方库用的都是用px单位,无法使用rem适配不同设备的屏幕. 解决办法:使用px2rem-l ...
- Python+OpenCV图像处理(三)—— Numpy数组操作图片
一.改变图片每个像素点每个通道的灰度值 (一) 代码如下: #遍历访问图片每个像素点,并修改相应的RGB import cv2 as cv def access_pixels(image): prin ...
- jboss的使用和安装
1. 安装 1.1.软件安装 首先要安装JDK(仅仅安装JRE是不行的,因为JSP页面需要编译),最新的正式版是JDK1.4.2.然后把JBoss的压缩包解压到一个目录下,目录名一般是"Jb ...
- redis-3.2.7安装脚本
redis-3.2.7 安装脚本 for CentOS 6.5 #!/bin/bash #Filename: inst_for_redis.sh #Version: 1.1 #Lastdate: 20 ...
- 一个随机验证码且不重复的小程序以及求随机输入一组数组中的最大值(Java)
1.代码: package day20181015;import java.util.Arrays;/** * 验证码的实现 * @author Administrator */public clas ...
- 02: djangorestframework使用
1.1 djangorestframework登录.认证和权限 1.认证与权限相关模块 # -*- coding: utf-8 -*- from django.utils import six fro ...