Java集合框架源码剖析:LinkedHashSet 和 LinkedHashMap
Java LinkedHashMap和HashMap有什么区别和联系?为什么LinkedHashMap会有着更快的迭代速度?LinkedHashSet跟LinkedHashMap有着怎样的内在联系?本文从数据结构和算法层面,结合生动图解为读者一一解答。
总体介绍
如果你已看过前面关于HashSet和HashMap,以及TreeSet和TreeMap的讲解,一定能够想到本文将要讲解的LinkedHashSet和LinkedHashMap其实也是一回事。LinkedHashSet和LinkedHashMap在Java里也有着相同的实现,前者仅仅是对后者做了一层包装,也就是说LinkedHashSet里面有一个LinkedHashMap(适配器模式)**。因此本文将重点分析LinkedHashMap。
LinkedHashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体,也就是说它同时满足HashMap和linked list的某些特性。可将LinkedHashMap看作采用linked list增强的HashMap。
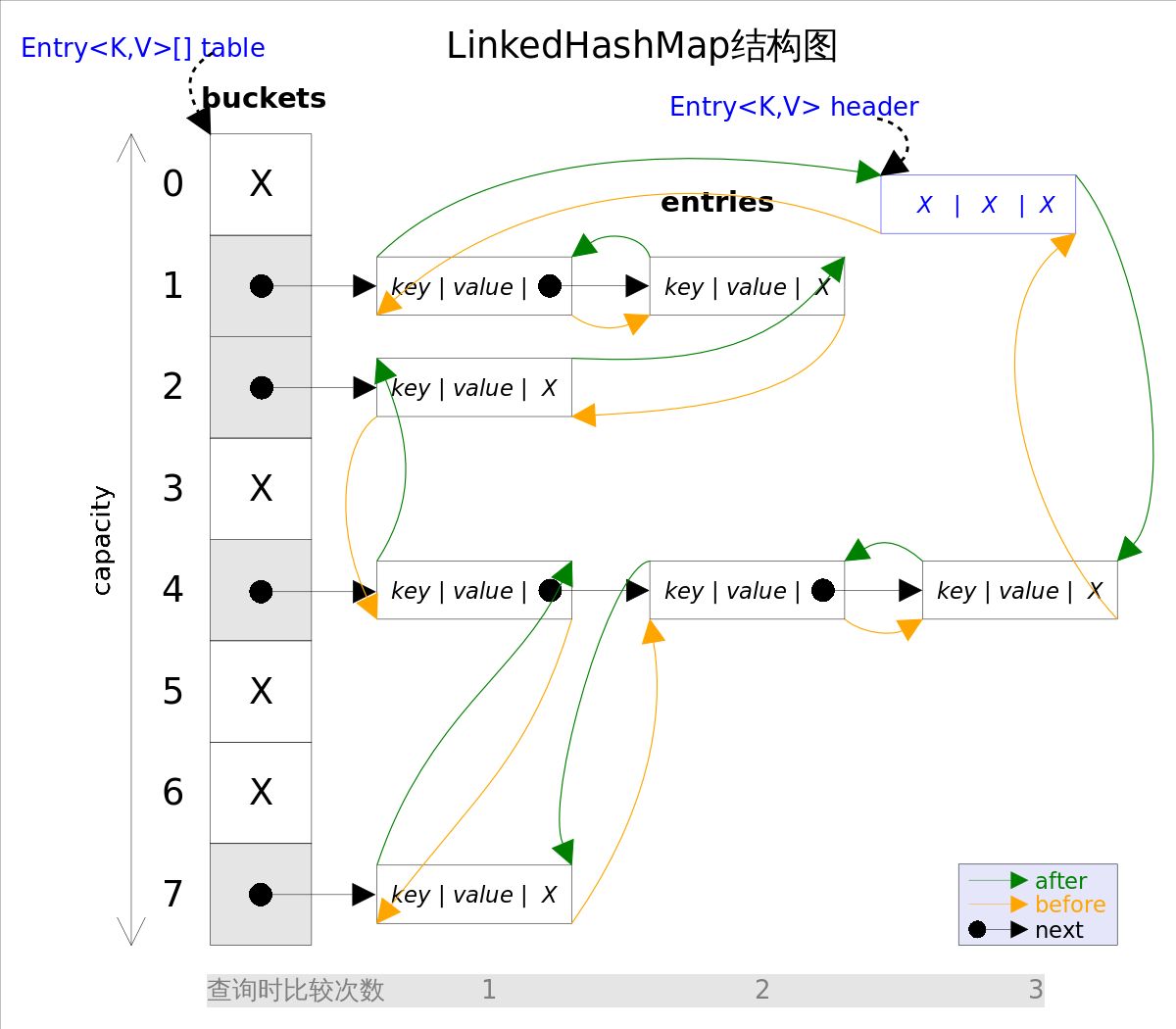
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
除了可以保迭代历顺序,这种结构还有一个好处:迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
有两个参数可以影响LinkedHashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
将对象放入到LinkedHashMap或LinkedHashSet中时,有两个方法需要特别关心:hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到LinkedHashMap或LinkedHashSet中,需要@OverridehashCode()和equals()方法。
通过如下方式可以得到一个跟源Map 迭代顺序一样的LinkedHashMap:
void foo(Map m) {
Map copy = new LinkedHashMap(m);
...
}
出于性能原因,LinkedHashMap是非同步的(not synchronized),如果需要在多线程环境使用,需要程序员手动同步;或者通过如下方式将LinkedHashMap包装成(wrapped)同步的:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
方法剖析
get()
get(Object key)方法根据指定的key值返回对应的value。该方法跟HashMap.get()方法的流程几乎完全一样,读者可自行参考前文,这里不再赘述。
put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。
注意,这里的插入有两重含义:
- 从
table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。- 从
header的角度看,新的entry需要插入到双向链表的尾部。
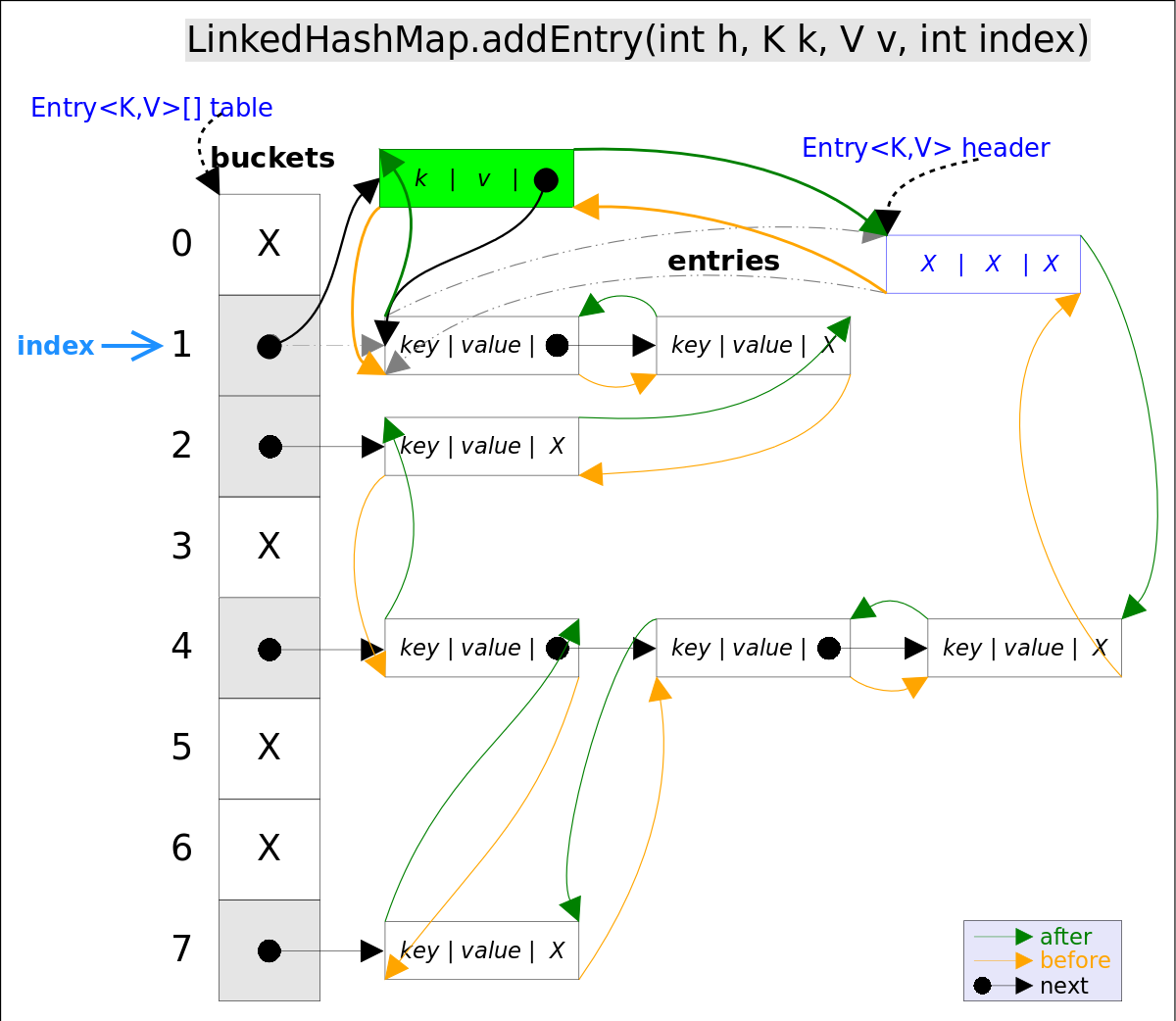
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}
上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
上述代码只是简单修改相关entry的引用而已。
remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
- 从
table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。- 从
header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。
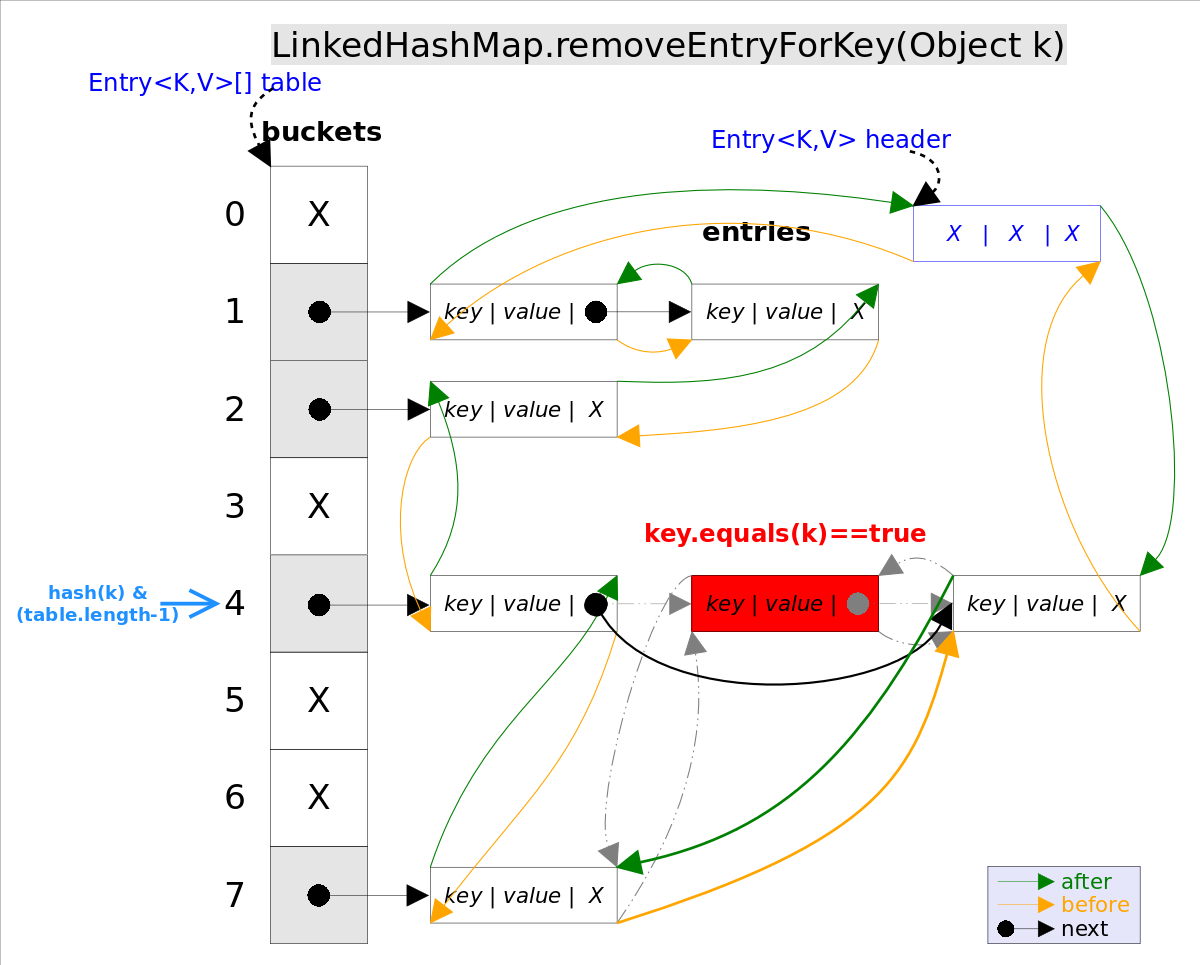
removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}
LinkedHashSet
前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
Java集合框架源码剖析:LinkedHashSet 和 LinkedHashMap的更多相关文章
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- 【java集合框架源码剖析系列】java源码剖析之TreeSet
本博客将从源码的角度带领大家学习TreeSet相关的知识. 一TreeSet类的定义: public class TreeSet<E> extends AbstractSet<E&g ...
- 【java集合框架源码剖析系列】java源码剖析之TreeMap
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于TreeMap的知识. 一TreeMap的定义: public class TreeMap&l ...
- 【java集合框架源码剖析系列】java源码剖析之ArrayList
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本. 本博客将从源码角度带领大家学习关于ArrayList的知识. 一ArrayList类的定义: public class Arr ...
- 【java集合框架源码剖析系列】java源码剖析之LinkedList
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本. 在实际项目中LinkedList也是使用频率非常高的一种集合,本博客将从源码角度带领大家学习关于LinkedList的知识. ...
- 【java集合框架源码剖析系列】java源码剖析之HashMap
前言:之所以打算写java集合框架源码剖析系列博客是因为自己反思了一下阿里内推一面的失败(估计没过,因为写此博客已距阿里巴巴一面一个星期),当时面试完之后感觉自己回答的挺好的,而且据面试官最后说的这几 ...
- 【java集合框架源码剖析系列】java源码剖析之java集合中的折半插入排序算法
注:关于排序算法,博主写过[数据结构排序算法系列]数据结构八大排序算法,基本上把所有的排序算法都详细的讲解过,而之所以单独将java集合中的排序算法拿出来讲解,是因为在阿里巴巴内推面试的时候面试官问过 ...
- Java集合框架源码(二)——hashSet
注:本人的源码基于JDK1.8.0,JDK的版本可以在命令行模式下通过java -version命令查看. 在前面的博文(Java集合框架源码(一)——hashMap)中我们详细讲了HashMap的原 ...
- Java集合框架源码分析(2)LinkedList
链表(LinkedList) 数组(array)和数组列表(ArrayList)都有一个重大的缺陷: 从数组的中间位置删除一个元素要付出很大的代价,因为数组中在被删除元素之后的所有元素都要向数组的前端 ...
随机推荐
- linux web服务器,防火墙iptables最简配置
配置防火墙(服务器安全优化) 安全规划:开启 80 22 端口并 打开回路(回环地址 127.0.0.1) # iptables –P INPUT ACCEPT # iptables –P OUTP ...
- SQL获取本周销售总数
select sum("NUMBER") as WEEK_NUMBER, COMPANY_CODE, PROJECT_CODE from D_VISIT WHERE "D ...
- Python 内置彩蛋
The Zen of Python, by Tim Peters Beautiful is better than ugly.Explicit is better than implicit.Simp ...
- Raw-OS源代码分析之消息系统-Queue_Size
分析的内核版本号截止到2014-04-15.基于1.05正式版.blogs会及时跟进最新版本号的内核开发进度,若源代码凝视出现"???"字样,则是未深究理解部分. Raw-OS官方 ...
- 软件包管理 之 Fedora/Redhat 在线安装更新软件包,yum 篇 ── 给新手指南
在本文中,我们主要解介绍 Fedora core 4.0 通过软件包管理工具yum来在线安装更新软件:关于apt工具应用,我们会在另外一篇中介绍: 一. yum 的使用:有些初学Linux的弟兄可能问 ...
- WPF笔记一
笔记内容: BUG.WPF运行窗体时调用Hide()方法,然后再Show()异常的解决方案 WPF 窗体设置为无边框 选择本地文件 选择文件夹 WPF实现右下角弹出消息窗口 WPF 显示 HTTP 网 ...
- Rails: No such file or directory - getcwd
这个的意思就是你从一个删除的目录里面运行实例:rails s
- 不同iOS版本做代码适配__IPHONE_OS_VERSION_MAX_ALLOWED 和 __IPHONE_8_0等专业术语
目前开发只想最低版本支持iOS8了,iOS8以前的就不管了,然后现在iOS9和iOS10出来以后,有些新的API,也有些弃用的API,为了兼容,有时候代码里面需要编写判断不同iOS版本,或者只允许指定 ...
- Winform下richtextbox截图实现
#region 根据richtextbox创建GDI+ private void DrawGDI(RichTextBox rich,Panel panl,PictureBox p2) { rich.U ...
- [论文笔记] Methodologies for Data Quality Assessment and Improvement (ACM Comput.Surv, 2009) (2)
本篇博文主要对DMQ(S3.7)的分类进行了研读. 1. 这个章节提出了一种DQM的分类法(如下图) 由上图可见,该分类法的分类标准是对assessment & improvement阶段的支 ...