Spark 2.0
Apache Spark 2.0: Faster, Easier, and Smarter
http://blog.madhukaraphatak.com/categories/spark-two/
https://amplab.cs.berkeley.edu/technical-preview-of-apache-spark-2-0-easier-faster-and-smarter/
Dataset - New Abstraction of Spark
For long, RDD was the standard abstraction of Spark.
But from Spark 2.0, Dataset will become the new abstraction layer for spark. Though RDD API will be available, it will become low level API, used mostly for runtime and library development. All user land code will be written against the Dataset abstraction and it’s subset Dataframe API.
2.0中,最关键的是在RDD这个low level抽象层上,又加了一组DataSet的high level的抽象层,让用户可以跟方便的开发
From Definition, ” A Dataset is a strongly typed collection of domain-specific objects that can be transformed in parallel using functional or relational operations. Each dataset also has an untyped view called a DataFrame, which is a Dataset of Row. “
which sounds similar to RDD definition
” RDD represents an immutable,partitioned collection of elements that can be operated on in parallel “
Dataset is a superset of Dataframe API which is released in Spark 1.3.
Dataframe是一种特殊化的Dataset,Dataframe = Dataset[row]
SparkSession - New entry point of Spark
In earlier versions of spark, spark context was entry point for Spark. As RDD was main API, it was created and manipulated using context API’s. For every other API,we needed to use different contexts.For streaming, we needed StreamingContext, for SQL sqlContext and for hive HiveContext. But as DataSet and Dataframe API’s are becoming new standard API’s we need an entry point build for them. So in Spark 2.0, we have a new entry point for DataSet and Dataframe API’s called as Spark Session.
因为有了新的抽象层,所以需要加新的入口,SparkSession
就像RDD对应于SparkContext
更强大的SQL支持
On the SQL side, we have significantly expanded the SQL capabilities of Spark, with the introduction of a new ANSI SQL parser and support for subqueries.
Spark 2.0 can run all the 99 TPC-DS queries, which require many of the SQL:2003 features.
Tungsten 2.0
Spark 2.0 ships with the second generation Tungsten engine.
This engine builds upon ideas from modern compilers and MPP databases and applies them to data processing.
The main idea is to emit optimized bytecode at runtime that collapses the entire query into a single function, eliminating virtual function calls and leveraging CPU registers for intermediate data. We call this technique “whole-stage code generation.”
在内存管理和基于CPU的性能优化上,faster
Structured Streaming
Spark 2.0’s Structured Streaming APIs is a novel way to approach streaming.
It stems from the realization that the simplest way to compute answers on streams of data is to not having to reason about the fact that it is a stream.
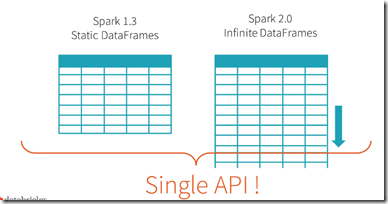
意思就是说,不要意识到流,流就是个无限的DataFrames
这个是典型的spark的思路,batch是一切的根本,和Flink截然相反
Spark 2.0的更多相关文章
- Spark 1.0.0 横空出世 Spark on Yarn 部署(Hadoop 2.4)
就在昨天,北京时间5月30日20点多.Spark 1.0.0最终公布了:Spark 1.0.0 released 依据官网描写叙述,Spark 1.0.0支持SQL编写:Spark SQL Progr ...
- APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If you are ju ...
- Apache Spark 3.0 将内置支持 GPU 调度
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU.FPGA 或 TPU 来加速计算.在 Apache Hadoop 3.1 版本里面 ...
- spark 2.0.0集群安装与hive on spark配置
1. 环境准备: JDK1.8 hive 2.3.4 hadoop 2.7.3 hbase 1.3.3 scala 2.11.12 mysql5.7 2. 下载spark2.0.0 cd /home/ ...
- Spark 2.0 PCA主成份分析
PCA在Spark2.0中用法比较简单,只需要设置: .setInputCol(“features”)//保证输入是特征值向量 .setOutputCol(“pcaFeatures”)//输出 .se ...
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- Spark 2.0 DataFrame map操作中Unable to find encoder for type stored in a Dataset.问题的分析与解决
转载:http://blog.csdn.net/sparkexpert/article/details/52871000 随着新版本的spark已经逐渐稳定,最近拟将原有框架升级到spark 2.0. ...
- Spark 2.0.0 SPARK-SQL returns NPE Error
com.esotericsoftware.kryo.KryoException: java.lang.NullPointerExceptionSerialization trace:underlyin ...
- Apache Spark 3.0 预览版正式发布,多项重大功能发布
2019年11月08日 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3. ...
随机推荐
- Searchable(搜索功能)(转)
文章来源:http://developer.android.com/guide/topics/search/search-dialog.html 一.前言: Android为程序的搜索功能提供了统一的 ...
- Android 下载文件 显示进度条
加入两个权限 一个是联网,另一个是读写SD卡 <uses-permission android:name="android.permission.INTERNET">& ...
- qmf
vim命令 ——————————正文开始—————————— Vim是一款简单而强大的文本编辑器,它能以简单的方式完成复杂的操作. 学习 vim 首先了解它的几种模式: 下图提供了三种模式下的切换: ...
- Laravel环境配置之安装Homestead
laravel requirements: PHP >= 5.5.9 (机器上yum安装的是5.3.3) OpenSSL PHP Extension PDO PHP Extension Mb ...
- Windows Phone 执行模型概述
Windows Phone 执行模型控制在 Windows Phone 上运行的应用程序的生命周期,该过程从启动应用程序开始,直至应用程序终止. 该执行模型旨在始终为最终用户提供快速响应的体验.为此, ...
- .net4.5 await async 简化之后的异步编程模型
步骤核心: 方法签名包含一个 async 修饰符. 按照约定,异步方法的名称以“Async”后缀结尾. 返回类型为以下之一: Task<TResult> 如果您的方法有操作数为 TRes ...
- BZOJ1075 : [SCOI2007]最优驾车drive
设$f[i][j][k]$为到达$(i,j)$,用时为$\frac{k}{5lcm}$小时的最低耗油量,然后DP即可. #include<cstdio> const int N=12,M= ...
- BZOJ3483 : SGU505 Prefixes and suffixes(询问在线版)
将每个串正着插入Trie A中,倒着插入Trie B中. 并求出每个串在A,B中的dfs序. 每次查询等价于查询在A中dfs序在[la,ra]之间,在B中dfs序在[lb,rb]之间的串的个数,用主席 ...
- c++ map删除元素
typedef std::map<std::string,float> StringFloatMap; StringFloatMap col1; StringFloatMap::itera ...
- 洛谷 P1007 独木桥 Label:模拟
题目背景 战争已经进入到紧要时间.你是运输小队长,正在率领运输部队向前线运送物资.运输任务像做题一样的无聊.你希望找些刺激,于是命令你的士兵们到前方的一座独木桥上欣赏风景,而你留在桥下欣赏士兵们.士兵 ...