基于淘宝开源Tair分布式KV存储引擎的整合部署
一、前言
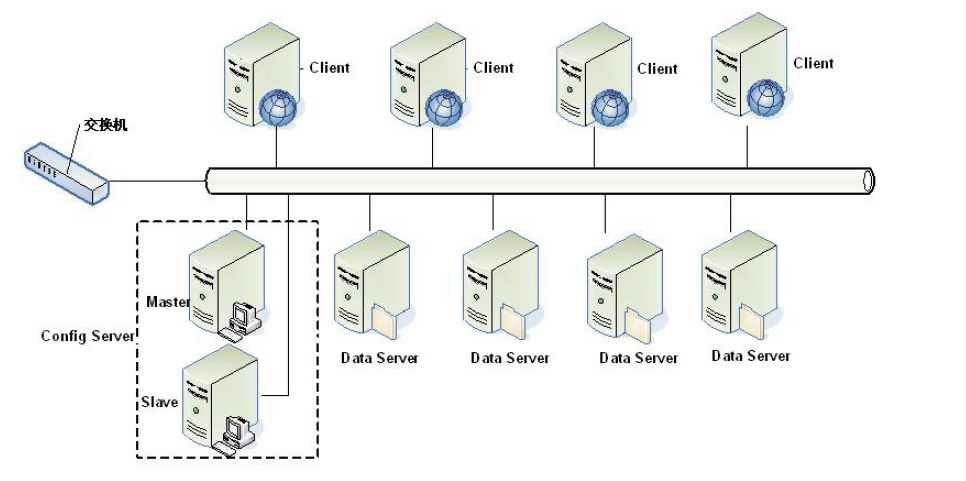
Tair支撑了淘宝几乎所有系统的缓存信息(Tair = Taobao Pair,Pair即Key-Value键值对),内置了三个存储引擎:mdb(默认,类似于Memcache)、rdb(类似于Redis)、ldb(高性能KV存储),其中前2者定位于cache缓存,ldb则定位于持久化存储。Tair属于分布式系统,由一个中心控制节点(Config Server)和一系列的服务节点(Data Server)组成,Config Server负责管理维护所有的Data Server状态信息。Data Server对外提供各种数据服务,并以心跳(Heartbeat)的形式将自身状况汇报给Config Server。Config Server是一个轻量级的控制点,可以采用Master-Slaver的形式来保证其可靠性,所有的Data Server地位都是等价的。持久化的数据存放于磁盘中,为了解决磁盘损坏导致的数据丢失, Tair可以配置数据的备份数目, 自动将一份数据的不同备份放到不同的主机上。
本文记录了详细的部署操作步骤(基于trunk版本),引用一张官方结构图,更多关于Tair的介绍请参照官方wiki(http://code.taobao.org/p/tair/wiki/intro/)。
二、安装Tair Server
1、系统环境:CentOS 6.5 (64位)
2、Tair Server 源码采用 C++ 编写,以下基于源码在linux环境下 make install
3、安装依赖包(感谢万能的yum)
1)wiki中描述需要安装依赖automake 、autoconfig、libtool库,实际CentOS6.5已经集成了以上lib,如果没有请通过yum获取
命令: “ yum install libtool ”
2)安装boost-devel库
命令: “ yum install boost-devel ”
3)安装gcc-c++
命令: “ yum install gcc-c++ ”
4、通过svn获取 tb-common-utils 和 Tair 源码
tb-common-utils 的 SVN地址: http://code.taobao.org/svn/tb-common-utils/trunk
Tair 的 SVN地址: http://code.taobao.org/svn/tair/trunk
5、将获取到的源码复制到当前用户目录,同时手工创建一个名称为“tairlib”文件夹,作为相关lib文件的安装路径,结构如下

6、安装tb-common-utils库,从命名可以看出应该是taobao内部开发的公共库
1)通过终端进入tb-common-utils文件夹,切换到root账号
2)给build.sh 脚本文件增加可执行X权限,否则可能会提示“权限不够”
命令: “ chmod +x build.sh ”
3)创建环境变量TBLIB_ROOT指示相关lib文件的安装路径,指向之前创建的tairlib文件夹
注意这个是会话级的变量,如果中间关闭终端需要重新export
命令: export TBLIB_ROOT="/home/glf/tairlib"
4)执行build.sh脚本。

5)至此tb-common-utils库安装完毕。
7、安装tair
1)切换进入tair文件夹,如果是重新打开的终端窗口,请切换到root账号,同时参照6.3使用同样的命令创建环境变量,tair的安装同样需要这个环境变量
2)给bootstrap.sh 脚本文件增加可执行X权限,否则可能提示“权限不够"
命令: “ chmod +x bootstrap.sh ”
3)执行 bootstrap.sh 脚本
4)执行 configure
5)执行 make
6)执行 make install ,安装成功后会把tair安装到 /root/tair_bin ,至此安装tair 服务器完毕。
因为使用的root账号安装,所以安装目录为/root,但如果使用当前用户在安装过程会提示权限问题,麻烦知道怎么解决的请告之。

三、Tair Server的配置
1、由于机器网络环境复杂,本文仅以一台机器不同端口号模拟分布式集群部署,如果多机器部署端口可以一致,只需要修改IP即可。
| 名称 | IP | 端口 |
| Config Server(Master) | 10.0.2.15 | 5198 |
| Config Server(Slaver) | 10.0.2.15 | 5200 |
| Data Server A | 10.0.2.15 | 5191 |
| Data Server B | 10.0.2.15 | 5192 |
关于IP、端口如何配置请参照下面的conf文件,但需要注意的是Config Server的心跳端口(Heartbeat Port)为Port+1,
例如Port=5198那么Heartbeat Port默认=5199,所以在配置其他端口的时候注意预留,不要重复。
2、CP 4份tair_bin文件夹,依次重命名如下图,后面都在4个CP的目录修改配置,原tair_bin保留不作任何修改( 好不容易才装起来的呀:) )。
tair_bin_cs1:作为Config Server(Master)目录
tair_bin_cs2:作为Config Server(Slaver)目录
tair_bin_ds1:作为Data Server A 目录
tair_bin_ds2:作为Data Server B 目录
3、依次在CP的4个目录下创建(mkdir) data 和 logs 文件夹,用于设置相关配置文件中的路径(不确定是否必须,也有可能服务启动的时候会根据conf设置的路径自动创建)
4、每个Server的etc 目录下都包含以下文件(安装时创建的sample文件),相关文件中已经存在对应的配置项解释说明,
同时可以参照wiki的解释:http://code.taobao.org/p/tair/wiki/deploy
“configserver.conf.default” (Config Server使用)
“dataserver.conf.default” (Data Server使用)
“group.conf.default” (Config Server使用)
“invalserver.conf.default” (暂未使用)
5、配置Config Server
1)在 tair_bin_cs1 和 tair_bin_cs2 的etc目录下将 “configserver.conf.default” 重命名为“configserver.conf”,将“group.conf.default”重命名为“group.conf”,作为服务器的正式配置文件。
2)打开 tair_bin_cs1\etc\configserver.conf 参照如下代码进行配置,其中第一行config_server为master服务器,第二行为slaver服务器,
使用绝对路径修改 log_file、pid_file、goup_file、data_dir 目录,使用 ifconfig 命名查看当前网卡的dev_name和ip,以下修改过的内容用红色字体标识。
(插曲:因为dev_name默认为eth0,我机器实际为eth1,一度陷入了绝境)
#
# tair 2.3 --- configserver config
# [public]
config_server=10.0.2.15:5198
config_server=10.0.2.15:5200 [configserver]
port=5198
log_file=/root/tair_bin_cs1/logs/config.log
pid_file=/root/tair_bin_cs1/logs/config.pid
log_level=warn
group_file=/root/tair_bin_cs1/etc/group.conf
data_dir=/root/tair_bin_cs1/data/data
dev_name=eth1
3)在 tair_bin_cs1\etc\group.conf 参照如下代码进行配置,主要用于注册DataSever服务器的IP和Port
#group name
[group_1]
# data move is 1 means when some data serve down, the migrating will be start.
# default value is 0
_data_move=0
#_min_data_server_count: when data servers left in a group less than this value, config server will stop serve for this group
#default value is copy count.
_min_data_server_count=1
#_plugIns_list=libStaticPlugIn.so
_build_strategy=1 #1 normal 2 rack
_build_diff_ratio=0.6 #how much difference is allowd between different rack
# diff_ratio = |data_sever_count_in_rack1 - data_server_count_in_rack2| / max (data_sever_count_in_rack1, data_server_count_in_rack2)
# diff_ration must less than _build_diff_ratio
_pos_mask=65535 # 65535 is 0xffff this will be used to gernerate rack info. 64 bit serverId & _pos_mask is the rack info,
_copy_count=1
_bucket_number=1023
# accept ds strategy. 1 means accept ds automatically
_accept_strategy=1 # data center A
_server_list=10.0.2.15:5191
_server_list=10.0.2.15:5192 #quota info
_areaCapacity_list=0,1124000;
4)Config Server(Slave)的配置也基本一致,注意修改conf文件中的路径、ip
configserver.conf 参照如下:
#
# tair 2.3 --- configserver config
# [public]
config_server=10.0.2.15:5198
config_server=10.0.2.15:5200 [configserver]
port=5200
log_file=/root/tair_bin_cs2/logs/config.log
pid_file=/root/tair_bin_cs2/logs/config.pid
log_level=warn
group_file=/root/tair_bin_cs2/etc/group.conf
data_dir=/root/tair_bin_cs2/data/data
dev_name=eth1
group.conf 参照如下:
#group name
[group_1]
# data move is 1 means when some data serve down, the migrating will be start.
# default value is 0
_data_move=0
#_min_data_server_count: when data servers left in a group less than this value, config server will stop serve for this group
#default value is copy count.
_min_data_server_count=1
#_plugIns_list=libStaticPlugIn.so
_build_strategy=1 #1 normal 2 rack
_build_diff_ratio=0.6 #how much difference is allowd between different rack
# diff_ratio = |data_sever_count_in_rack1 - data_server_count_in_rack2| / max (data_sever_count_in_rack1, data_server_count_in_rack2)
# diff_ration must less than _build_diff_ratio
_pos_mask=65535 # 65535 is 0xffff this will be used to gernerate rack info. 64 bit serverId & _pos_mask is the rack info,
_copy_count=1
_bucket_number=1023
# accept ds strategy. 1 means accept ds automatically
_accept_strategy=1 # data center A
_server_list=10.0.2.15:5191
_server_list=10.0.2.15:5192 #quota info
_areaCapacity_list=0,1124000;
5)至此2台 Config Server 配置完毕
6、配置Data Server(默认为 mdb 引擎)
1)在2个Data Server的 etc 目录下将 “dataserver.conf.default” 重命名为“dataserver.conf”,作为服务器的正式配置文件
2)打开 tair_bin_ds1\etc\dataserver.conf 参照如下代码进行修改配置,注意[public]节点的2行config_server必须和configserver上的配置保持一致
#
# tair 2.3 --- tairserver config
# [public]
config_server=10.0.2.15:5198
config_server=10.0.2.15:5200 [tairserver]
#
#storage_engine:
#
# mdb
# kdb
# ldb
#
storage_engine=mdb
local_mode=0
#
#mdb_type:
# mdb
# mdb_shm
#
mdb_type=mdb_shm #
# if you just run 1 tairserver on a computer, you may ignore this option.
# if you want to run more than 1 tairserver on a computer, each tairserver must have their own "mdb_shm_path"
#
#
mdb_shm_path=/mdb_shm_path01 #tairserver listen port
port=5191
heartbeat_port=6191 process_thread_num=16
#
#mdb size in MB
#
slab_mem_size=1024
log_file=/root/tair_bin_ds1/logs/server.log
pid_file=/root/tair_bin_ds1/logs/server.pid
log_level=warn
dev_name=eth1
ulog_dir=/root/tair_bin_ds1/data/ulog
ulog_file_number=3
ulog_file_size=64
check_expired_hour_range=2-4
check_slab_hour_range=5-7
dup_sync=1 do_rsync=0
# much resemble json format
# one local cluster config and one or multi remote cluster config.
# {local:[master_cs_addr,slave_cs_addr,group_name,timeout_ms,queue_limit],remote:[...],remote:[...]}
rsync_conf={local:[10.0.0.1:5198,10.0.0.2:5198,group_local,2000,1000],remote:[10.0.1.1:5198,10.0.1.2:5198,group_remote,2000,3000]}
# if same data can be updated in local and remote cluster, then we need care modify time to
# reserve latest update when do rsync to each other.
rsync_mtime_care=0
# rsync data directory(retry_log/fail_log..)
rsync_data_dir=/root/tair_bin_ds1/data/remote
# max log file size to record failed rsync data, rotate to a new file when over the limit
rsync_fail_log_size=30000000
# whether do retry when rsync failed at first time
rsync_do_retry=0
# when doing retry, size limit of retry log's memory use
rsync_retry_log_mem_size=100000000 [fdb]
# in MB
index_mmap_size=30
cache_size=256
bucket_size=10223
free_block_pool_size=8
data_dir=/root/tair_bin_ds1/data/fdb
fdb_name=tair_fdb [kdb]
# in byte
map_size=10485760 # the size of the internal memory-mapped region
bucket_size=1048583 # the number of buckets of the hash table
record_align=128 # the power of the alignment of record size
data_dir=/root/tair_bin_ds1/data/kdb # the directory of kdb's data [ldb]
#### ldb manager config
## data dir prefix, db path will be data/ldbxx, "xx" means db instance index.
## so if ldb_db_instance_count = 2, then leveldb will init in
## /data/ldb1/ldb/, /data/ldb2/ldb/. We can mount each disk to
## data/ldb1, data/ldb2, so we can init each instance on each disk.
data_dir=/root/tair_bin_ds1/data/ldb
## leveldb instance count, buckets will be well-distributed to instances
ldb_db_instance_count=1
## whether load backup version when startup.
## backup version may be created to maintain some db data of specifid version.
ldb_load_backup_version=0
## whether support version strategy.
## if yes, put will do get operation to update existed items's meta info(version .etc),
## get unexist item is expensive for leveldb. set 0 to disable if nobody even care version stuff.
ldb_db_version_care=1
## time range to compact for gc, 1-1 means do no compaction at all
ldb_compact_gc_range = 3-6
## backgroud task check compact interval (s)
ldb_check_compact_interval = 120
## use cache count, 0 means NOT use cache,`ldb_use_cache_count should NOT be larger
## than `ldb_db_instance_count, and better to be a factor of `ldb_db_instance_count.
## each cache mdb's config depends on mdb's config item(mdb_type, slab_mem_size, etc)
ldb_use_cache_count=1
## cache stat can't report configserver, record stat locally, stat file size.
## file will be rotate when file size is over this.
ldb_cache_stat_file_size=20971520
## migrate item batch size one time (1M)
ldb_migrate_batch_size = 3145728
## migrate item batch count.
## real batch migrate items depends on the smaller size/count
ldb_migrate_batch_count = 5000
## comparator_type bitcmp by default
# ldb_comparator_type=numeric
## numeric comparator: special compare method for user_key sorting in order to reducing compact
## parameters for numeric compare. format: [meta][prefix][delimiter][number][suffix]
## skip meta size in compare
# ldb_userkey_skip_meta_size=2
## delimiter between prefix and number
# ldb_userkey_num_delimiter=:
####
## use blommfilter
ldb_use_bloomfilter=1
## use mmap to speed up random acess file(sstable),may cost much memory
ldb_use_mmap_random_access=0
## how many highest levels to limit compaction
ldb_limit_compact_level_count=0
## limit compaction ratio: allow doing one compaction every ldb_limit_compact_interval
## 0 means limit all compaction
ldb_limit_compact_count_interval=0
## limit compaction time interval
## 0 means limit all compaction
ldb_limit_compact_time_interval=0
## limit compaction time range, start == end means doing limit the whole day.
ldb_limit_compact_time_range=6-1
## limit delete obsolete files when finishing one compaction
ldb_limit_delete_obsolete_file_interval=5
## whether trigger compaction by seek
ldb_do_seek_compaction=0
## whether split mmt when compaction with user-define logic(bucket range, eg)
ldb_do_split_mmt_compaction=0 #### following config effects on FastDump ####
## when ldb_db_instance_count > 1, bucket will be sharded to instance base on config strategy.
## current supported:
## hash : just do integer hash to bucket number then module to instance, instance's balance may be
## not perfect in small buckets set. same bucket will be sharded to same instance
## all the time, so data will be reused even if buckets owned by server changed(maybe cluster has changed),
## map : handle to get better balance among all instances. same bucket may be sharded to different instance based
## on different buckets set(data will be migrated among instances).
ldb_bucket_index_to_instance_strategy=map
## bucket index can be updated. this is useful if the cluster wouldn't change once started
## even server down/up accidently.
ldb_bucket_index_can_update=1
## strategy map will save bucket index statistics into file, this is the file's directory
ldb_bucket_index_file_dir=/root/tair_bin_ds1/data/bindex
## memory usage for memtable sharded by bucket when batch-put(especially for FastDump)
ldb_max_mem_usage_for_memtable=3221225472
#### #### leveldb config (Warning: you should know what you're doing.)
## one leveldb instance max open files(actually table_cache_ capacity, consider as working set, see `ldb_table_cache_size)
ldb_max_open_files=65535
## whether return fail when occure fail when init/load db, and
## if true, read data when compactiong will verify checksum
ldb_paranoid_check=0
## memtable size
ldb_write_buffer_size=67108864
## sstable size
ldb_target_file_size=8388608
## max file size in each level. level-n (n > 0): (n - 1) * 10 * ldb_base_level_size
ldb_base_level_size=134217728
## sstable's block size
# ldb_block_size=4096
## sstable cache size (override `ldb_max_open_files)
ldb_table_cache_size=1073741824
##block cache size
ldb_block_cache_size=16777216
## arena used by memtable, arena block size
#ldb_arenablock_size=4096
## key is prefix-compressed period in block,
## this is period length(how many keys will be prefix-compressed period)
# ldb_block_restart_interval=16
## specifid compression method (snappy only now)
# ldb_compression=1
## compact when sstables count in level-0 is over this trigger
ldb_l0_compaction_trigger=1
## write will slow down when sstables count in level-0 is over this trigger
## or sstables' filesize in level-0 is over trigger * ldb_write_buffer_size if ldb_l0_limit_write_with_count=0
ldb_l0_slowdown_write_trigger=32
## write will stop(wait until trigger down)
ldb_l0_stop_write_trigger=64
## when write memtable, max level to below maybe
ldb_max_memcompact_level=3
## read verify checksum
ldb_read_verify_checksums=0
## write sync log. (one write will sync log once, expensive)
ldb_write_sync=0
## bits per key when use bloom filter
#ldb_bloomfilter_bits_per_key=10
## filter data base logarithm. filterbasesize=1<<ldb_filter_base_logarithm
#ldb_filter_base_logarithm=12
3)另一台DataServer的配置基本一致,参照如下代码
注意:由于属于单机部署多个DataServer,需要修改mdb_shm_path=/mdb_shm_path02,(ps:这点我开始没留意导致每次启动一个dataserver的时候另一台自动shutdown)
#
# tair 2.3 --- tairserver config
# [public]
config_server=10.0.2.15:5198
config_server=10.0.2.15:5200 [tairserver]
#
#storage_engine:
#
# mdb
# kdb
# ldb
#
storage_engine=mdb
local_mode=0
#
#mdb_type:
# mdb
# mdb_shm
#
mdb_type=mdb_shm #
# if you just run 1 tairserver on a computer, you may ignore this option.
# if you want to run more than 1 tairserver on a computer, each tairserver must have their own "mdb_shm_path"
#
#
mdb_shm_path=/mdb_shm_path02 #tairserver listen port
port=5192
heartbeat_port=6192 process_thread_num=16
#
#mdb size in MB
#
slab_mem_size=1024
log_file=/root/tair_bin_ds2/logs/server.log
pid_file=/root/tair_bin_ds2/logs/server.pid
log_level=warn
dev_name=eth1
ulog_dir=/root/tair_bin_ds2/data/ulog
ulog_file_number=3
ulog_file_size=64
check_expired_hour_range=2-4
check_slab_hour_range=5-7
dup_sync=1 do_rsync=0
# much resemble json format
# one local cluster config and one or multi remote cluster config.
# {local:[master_cs_addr,slave_cs_addr,group_name,timeout_ms,queue_limit],remote:[...],remote:[...]}
rsync_conf={local:[10.0.0.1:5198,10.0.0.2:5198,group_local,2000,1000],remote:[10.0.1.1:5198,10.0.1.2:5198,group_remote,2000,3000]}
# if same data can be updated in local and remote cluster, then we need care modify time to
# reserve latest update when do rsync to each other.
rsync_mtime_care=0
# rsync data directory(retry_log/fail_log..)
rsync_data_dir=/root/tair_bin_ds2/data/remote
# max log file size to record failed rsync data, rotate to a new file when over the limit
rsync_fail_log_size=30000000
# whether do retry when rsync failed at first time
rsync_do_retry=0
# when doing retry, size limit of retry log's memory use
rsync_retry_log_mem_size=100000000 [fdb]
# in MB
index_mmap_size=30
cache_size=256
bucket_size=10223
free_block_pool_size=8
data_dir=/root/tair_bin_ds2/data/fdb
fdb_name=tair_fdb [kdb]
# in byte
map_size=10485760 # the size of the internal memory-mapped region
bucket_size=1048583 # the number of buckets of the hash table
record_align=128 # the power of the alignment of record size
data_dir=/root/tair_bin_ds2/data/kdb # the directory of kdb's data [ldb]
#### ldb manager config
## data dir prefix, db path will be data/ldbxx, "xx" means db instance index.
## so if ldb_db_instance_count = 2, then leveldb will init in
## /data/ldb1/ldb/, /data/ldb2/ldb/. We can mount each disk to
## data/ldb1, data/ldb2, so we can init each instance on each disk.
data_dir=/root/tair_bin_ds2/data/ldb
## leveldb instance count, buckets will be well-distributed to instances
ldb_db_instance_count=1
## whether load backup version when startup.
## backup version may be created to maintain some db data of specifid version.
ldb_load_backup_version=0
## whether support version strategy.
## if yes, put will do get operation to update existed items's meta info(version .etc),
## get unexist item is expensive for leveldb. set 0 to disable if nobody even care version stuff.
ldb_db_version_care=1
## time range to compact for gc, 1-1 means do no compaction at all
ldb_compact_gc_range = 3-6
## backgroud task check compact interval (s)
ldb_check_compact_interval = 120
## use cache count, 0 means NOT use cache,`ldb_use_cache_count should NOT be larger
## than `ldb_db_instance_count, and better to be a factor of `ldb_db_instance_count.
## each cache mdb's config depends on mdb's config item(mdb_type, slab_mem_size, etc)
ldb_use_cache_count=1
## cache stat can't report configserver, record stat locally, stat file size.
## file will be rotate when file size is over this.
ldb_cache_stat_file_size=20971520
## migrate item batch size one time (1M)
ldb_migrate_batch_size = 3145728
## migrate item batch count.
## real batch migrate items depends on the smaller size/count
ldb_migrate_batch_count = 5000
## comparator_type bitcmp by default
# ldb_comparator_type=numeric
## numeric comparator: special compare method for user_key sorting in order to reducing compact
## parameters for numeric compare. format: [meta][prefix][delimiter][number][suffix]
## skip meta size in compare
# ldb_userkey_skip_meta_size=2
## delimiter between prefix and number
# ldb_userkey_num_delimiter=:
####
## use blommfilter
ldb_use_bloomfilter=1
## use mmap to speed up random acess file(sstable),may cost much memory
ldb_use_mmap_random_access=0
## how many highest levels to limit compaction
ldb_limit_compact_level_count=0
## limit compaction ratio: allow doing one compaction every ldb_limit_compact_interval
## 0 means limit all compaction
ldb_limit_compact_count_interval=0
## limit compaction time interval
## 0 means limit all compaction
ldb_limit_compact_time_interval=0
## limit compaction time range, start == end means doing limit the whole day.
ldb_limit_compact_time_range=6-1
## limit delete obsolete files when finishing one compaction
ldb_limit_delete_obsolete_file_interval=5
## whether trigger compaction by seek
ldb_do_seek_compaction=0
## whether split mmt when compaction with user-define logic(bucket range, eg)
ldb_do_split_mmt_compaction=0 #### following config effects on FastDump ####
## when ldb_db_instance_count > 1, bucket will be sharded to instance base on config strategy.
## current supported:
## hash : just do integer hash to bucket number then module to instance, instance's balance may be
## not perfect in small buckets set. same bucket will be sharded to same instance
## all the time, so data will be reused even if buckets owned by server changed(maybe cluster has changed),
## map : handle to get better balance among all instances. same bucket may be sharded to different instance based
## on different buckets set(data will be migrated among instances).
ldb_bucket_index_to_instance_strategy=map
## bucket index can be updated. this is useful if the cluster wouldn't change once started
## even server down/up accidently.
ldb_bucket_index_can_update=1
## strategy map will save bucket index statistics into file, this is the file's directory
ldb_bucket_index_file_dir=/root/tair_bin_ds2/data/bindex
## memory usage for memtable sharded by bucket when batch-put(especially for FastDump)
ldb_max_mem_usage_for_memtable=3221225472
#### #### leveldb config (Warning: you should know what you're doing.)
## one leveldb instance max open files(actually table_cache_ capacity, consider as working set, see `ldb_table_cache_size)
ldb_max_open_files=65535
## whether return fail when occure fail when init/load db, and
## if true, read data when compactiong will verify checksum
ldb_paranoid_check=0
## memtable size
ldb_write_buffer_size=67108864
## sstable size
ldb_target_file_size=8388608
## max file size in each level. level-n (n > 0): (n - 1) * 10 * ldb_base_level_size
ldb_base_level_size=134217728
## sstable's block size
# ldb_block_size=4096
## sstable cache size (override `ldb_max_open_files)
ldb_table_cache_size=1073741824
##block cache size
ldb_block_cache_size=16777216
## arena used by memtable, arena block size
#ldb_arenablock_size=4096
## key is prefix-compressed period in block,
## this is period length(how many keys will be prefix-compressed period)
# ldb_block_restart_interval=16
## specifid compression method (snappy only now)
# ldb_compression=1
## compact when sstables count in level-0 is over this trigger
ldb_l0_compaction_trigger=1
## write will slow down when sstables count in level-0 is over this trigger
## or sstables' filesize in level-0 is over trigger * ldb_write_buffer_size if ldb_l0_limit_write_with_count=0
ldb_l0_slowdown_write_trigger=32
## write will stop(wait until trigger down)
ldb_l0_stop_write_trigger=64
## when write memtable, max level to below maybe
ldb_max_memcompact_level=3
## read verify checksum
ldb_read_verify_checksums=0
## write sync log. (one write will sync log once, expensive)
ldb_write_sync=0
## bits per key when use bloom filter
#ldb_bloomfilter_bits_per_key=10
## filter data base logarithm. filterbasesize=1<<ldb_filter_base_logarithm
#ldb_filter_base_logarithm=12
4)至此2台 Data Server 也配置完毕
四、启动Tair Server集群
1、通过终端任意选其中一台Server执行 set_shm.sh(需要root权限),修改系统分配内存策略,确保程序能够使用足够的共享内存
命令: “ ./set_shm.sh ”
2、分别通过终端进入2台Data Server目录,执行 tair.sh 脚本启动服务器,注意:请先启动DataServer,后启动ConfigServer,相关解释见wiki
此时由于Config Server还没有启动,Log会出现heartbeat错误。
[2014-12-19 19:28:42.336703] ERROR handlePacket (heartbeat_thread.cpp:141) [140335215126272] ControlPacket, cmd:3
[2014-12-19 19:28:43.341952] ERROR handlePacket (heartbeat_thread.cpp:141) [140335215126272] ControlPacket, cmd:2
[2014-12-19 19:28:43.341982] ERROR handlePacket (heartbeat_thread.cpp:141) [140335215126272] ControlPacket, cmd:3
[2014-12-19 19:28:44.345308] WARN update_server_table (tair_manager.cpp:1397) [140334767929088] updateServerTable, size: 2046
[2014-12-19 19:28:44.345312] WARN handlePacket (heartbeat_thread.cpp:212) [140335215126272] config server HOST UP: 10.0.2.15:5198
[2014-12-19 19:28:44.345350] WARN handlePacket (heartbeat_thread.cpp:212) [140335215126272] config server HOST UP: 10.0.2.15:5200
命令: “ ./tair.sh start_ds ”

3、分别通过终端进入2台Config Server目录,通过执行 tair.sh 脚本来启动服务器
命令: “ ./tair.sh start_cs ”
4、至此4台服务器启动完毕,过程不会一帆风顺,请耐心仔细,查阅log文件
五、客户端连接Tair Server
1、连接Tair服务器目前有3种方式:命令行、C++版本TairClient、Java版本TairClient(从依赖包可以看出使用的Mina通信框架),
底层使用socket通信,所以理论上只要支持socket操作的程序语言都可以直接实现Tair客户端
2、通过终端进入任意一个Server程序目录的 sbin 文件夹,执行 tairclient 命令连接Tair服务器,-c参数表示连接configserver,-s参数表示连接dataserver,
参照下图命令连接,“group_1” 是group.conf配置文件中的默认值。
连接到 tair configserver 后可以通过 put命令 新增一个键值对,例如:put key1 hellowold,然后通过get命令取值,如下图:
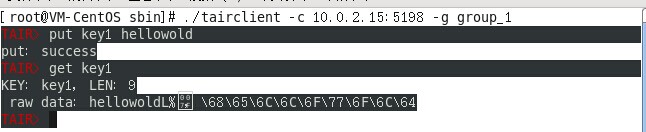
也可以连接到tair dataserver后可以查看单独某个ds上的数据,下图可以看出当连接到Port=5191的DataServer可以取到key1的值,5192的DS上则不能取到值。
Tair ConfigServer负载均衡采用一致性哈希算法进行数据分配,更多相关内容请查阅wiki。
六、更多
至此Tair服务器安装部署完毕,更多关于学习、整合、测试相关的内容请期待后续博文,同时也欢迎有兴趣的人交流沟通。
七、向开源工作者和组织致敬,@tair team,感谢对开源事业作出的任何贡献
基于淘宝开源Tair分布式KV存储引擎的整合部署的更多相关文章
- Tair 分布式K-V存储方案
tair 是淘宝的一个开源项目,它是一个分布式的key/value结构数据的解决方案. 作为一个分布式系统,Tair由一个中心控制节点(config server)和一系列的服务节点(data ser ...
- 淘宝开源Key/Value结构数据存储系统Tair技术剖析
摘要: Tair的功能 Tair是一个Key/Value结构数据的解决方案,它默认支持基于内存和文件的两种存储方式,分别和我们通常所说的缓存和持久化存储对应. Tair除了普通Key/Value系统提 ...
- 编写你的第一个 Java 版 Raft 分布式 KV 存储
前言 本文旨在讲述如何使用 Java 语言实现基于 Raft 算法的,分布式的,KV 结构的存储项目.该项目的背景是为了深入理解 Raft 算法,从而深刻理解分布式环境下数据强一致性该如何实现:该项目 ...
- 淘宝开源编辑器Kissy Editor和简易留言编辑器【转】
原来也写过一篇关于百度Ueditor编辑器的介绍:百度Ueditor编辑器的使用,ASP.NET也可上传图片 最开始是使用CuteEditor控件,需要好几mb的空间,因为刚开始学习ASP.NET的时 ...
- Ping CAP CTO、Codis作者谈redis分布式解决方案和分布式KV存储
此文根据[QCON高可用架构群]分享内容,由群内[编辑组]志愿整理,转发请注明出处. 苏东旭,Ping CAP CTO,Codis作者 开源项目Codis的co-author黄东旭,之前在豌豆荚从事i ...
- 淘宝开源Web服务器Tengine安装教程
简介Tengine是由淘宝核心系统部基于Nginx开发的Web服务器,它在Nginx的基础上,针对大访问量网站的需求,添加了很多功能和特性.Tengine的性能和稳定性已经在大型的网站如淘宝网,淘宝商 ...
- 淘宝开源系统监控工具Tsar
Tsar是淘宝开发的一个非常好用的系统监控工具,在淘宝内部大量使用 它不仅可以监控CPU.IO.内存.TCP等系统状态,也可以监控Apache,Nginx/Tengine,Squid等服务器状态 ...
- 淘宝开源Web服务器Tengine基本安装步骤
Tengine 是由淘宝核心系统部基于Nginx开发的Web服务器,它在Nginx的基础上,针对大访问量 网站的需求,添加了很多功能和特性.Tengine的性能和稳定性已经在大型的网站如淘宝网,淘宝商 ...
- 淘宝开源项目之Tsar
软件介绍: Tsar是淘宝开发的一个非常好用的系统监控工具,在淘宝内部大量使用,它不仅可以监控CPU.IO.内存.TCP等系统状态,也可以监控Apache,Nginx/Tengine,Squid等服务 ...
随机推荐
- linux shell expr 使用
linux shell expr 使用 收藏人:春秋百味 -- | 阅: 转: | | 分享 非原创, 摘自:<LINUX与UNIX Shell编程指南> 17.5 expr用法 expr ...
- 取出type="button" 和type="text" 里面的值显示在页面
<script type="text/JavaScript> function changeLink() { document.getElementById("nod ...
- sina第三方登录
Sina 第三方登录 添加网站的流程如下: Sina接入主要审核点: • 1.网站可正常访问:若页面无法打开,或加载时间过长,或未建设完成的网站.或空白网站将无法通过审核: • 2.站点已部署微连接 ...
- Android PullToRefreshListView上拉刷新和下拉刷新
PullToRefreshListView实现上拉和下拉刷新有两个步骤: 1.设置刷新方式 pullToRefreshView.setMode(PullToRefreshBase.Mode.BOTH) ...
- Android 调用浏览器和嵌入网页
Android App开发时由于布局相对麻烦,很多时候一个App通常是由html5和原生控件相结合而成.简单的网页应用可以直接内嵌html5页面即可,对于需要调用复杂的底层功能时则采用原生控件的方式进 ...
- 在eclipse中进行Struts2项目的配置
Struts2是一个比较出色的基于MVC设计模式的框架,是由Struts1和WebWork发展而来的,性能也比较稳定,现在是Apache软件基金会的一个项目,下面就来配置Struts2进行初始化的开发 ...
- canvas API ,通俗的canvas基础知识(四)
今天要讲的内容是canvas的转换功能,前面的内容没用看的同学可以出门右转,先看看前面的基础知识,废话不多说,开始进入正题吧! 何为转换功能?熟悉css3的同学都知道,css3里面有transform ...
- Ubuntu 12.10 安装 jdk-7u10-linux-x64.tar.gz(转载)
在Ubuntu 12.10下安装 jdk-7u10-linux-x64.tar.gz 总的原则:将jdk-7u10-linux-x64.tar.gz压缩包解压至/usr/lib/jdk,设置jdk环境 ...
- Codeigniter CRUD代码快速构建
一个与数据库操作打交道的应用,必然涉及到数据的添加.修改.删除等操作.因此CRUD操作几乎成为每个后台管理站点的必备功能.数据库的复杂性,导致PHP操作代码也会有不少的冗余,因此,如果可以有工具自动生 ...
- jQuery信息提示工具jquery.poshytip (转载)
转载地址:http://www.helloweba.com/view-blog-123.html Poshy Tip是一款非常友好的信息提示工具,它基于jQuery,当鼠标滑向链接时,会出现一个信息提 ...